 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiVa: An Iterative Framework to Harvest More Diverse and Valid Labels from User Comments for Music
Aug 09, 2023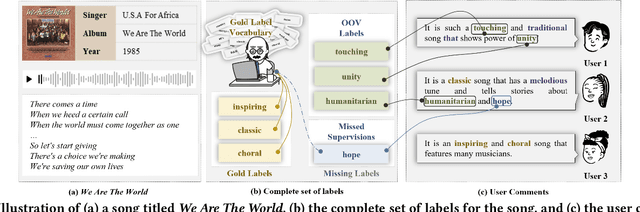

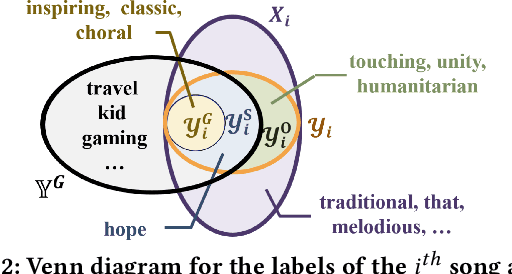
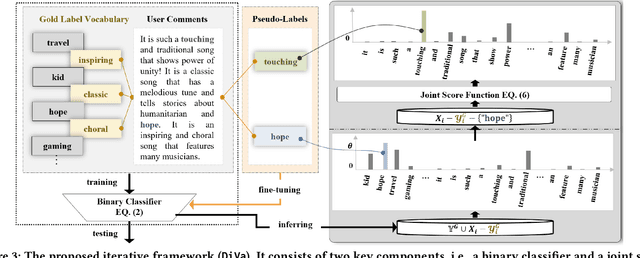
Towards sufficient music searching, it is vital to form a complete set of labels for each song. However, current solutions fail to resolve it as they cannot produce diverse enough mappings to make up for the information missed by the gold labels. Based on the observation that such missing information may already be presented in user comments, we propose to study the automated music labeling in an essential but under-explored setting, where the model is required to harvest more diverse and valid labels from the users' comments given limited gold labels. To this end, we design an iterative framework (DiVa) to harvest more $\underline{\text{Di}}$verse and $\underline{\text{Va}}$lid labels from user comments for music. The framework makes a classifier able to form complete sets of labels for songs via pseudo-labels inferred from pre-trained classifiers and a novel joint score function. The experiment on a densely annotated testing set reveals the superiority of the Diva over state-of-the-art solutions in producing more diverse labels missed by the gold labels. We hope our work can inspire future research on automated music labeling.
Review-Based Tip Generation for Music Songs
May 14, 2022

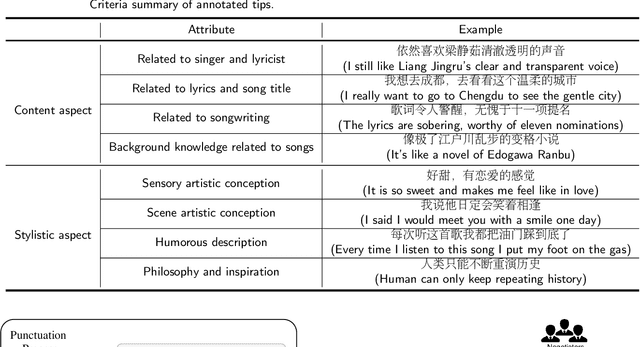
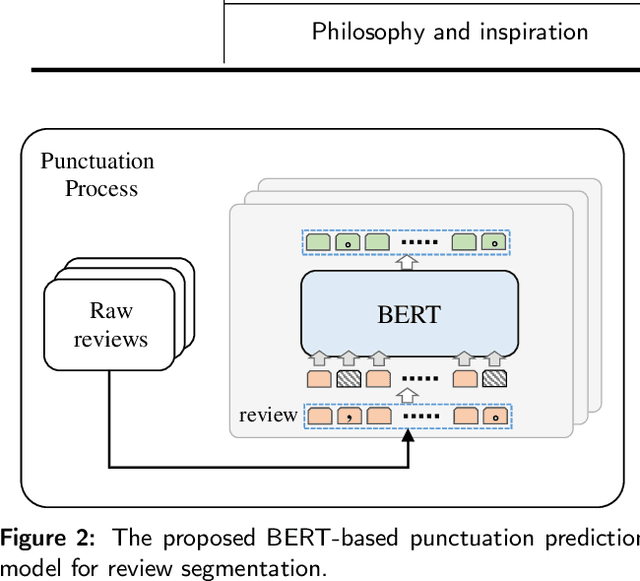
Reviews of songs play an important role in online music service platforms. Prior research shows that users can make quicker and more informed decisions when presented with meaningful song reviews. However, reviews of music songs are generally long in length and most of them are non-informative for users. It is difficult for users to efficiently grasp meaningful messages for making decisions. To solve this problem, one practical strategy is to provide tips, i.e., short, concise, empathetic, and self-contained descriptions about songs. Tips are produced from song reviews and should express non-trivial insight about the songs. To the best of our knowledge, no prior studies have explored the tip generation task in music domain. In this paper, we create a dataset named MTips for the task and propose a framework named GenTMS for automatically generating tips from song reviews. The dataset involves 8,003 Chinese tips/non-tips from 128 songs which are distributed in five different song genres. Experimental results show that GenTMS achieves top-10 precision at 85.56%, outperforming the baseline models by at least 3.34%. Besides, to simulate the practical usage of our proposed framework, we also experiment with previously-unseen songs, during which GenTMS also achieves the best performance with top-10 precision at 78.89% on average. The results demonstrate the effectiveness of the proposed framework in tip generation of the music domain.
Empathetic Response Generation with State Management
May 07, 2022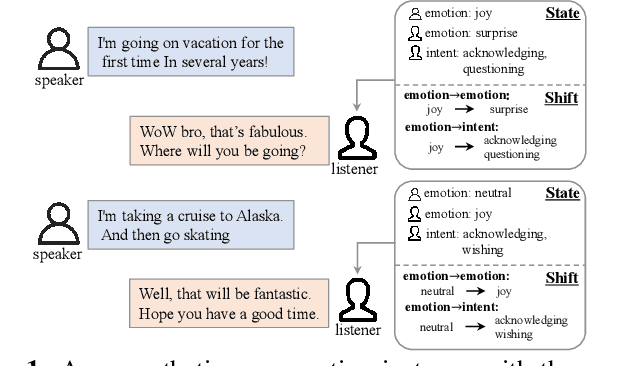
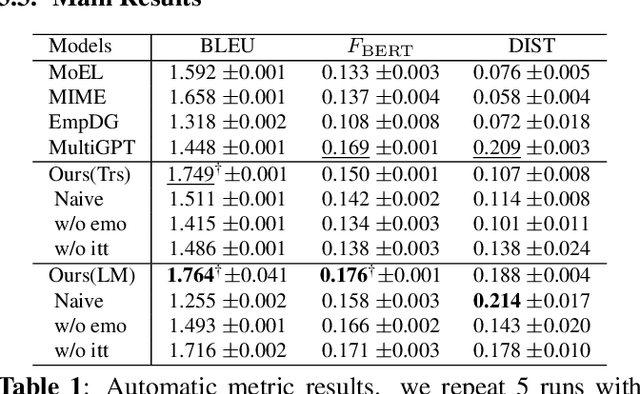
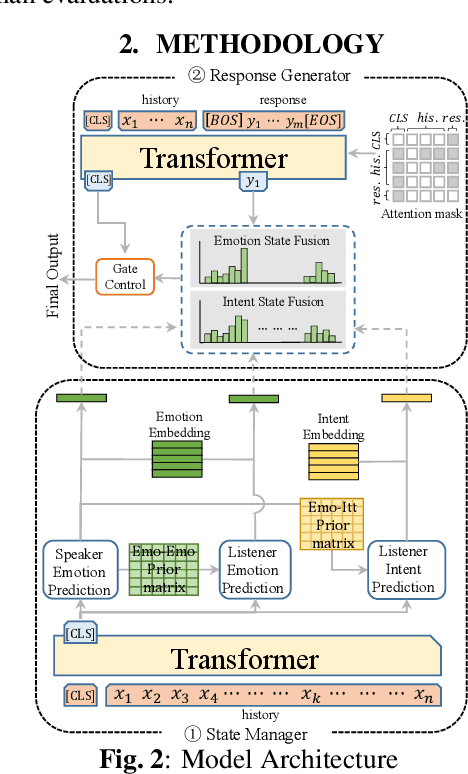
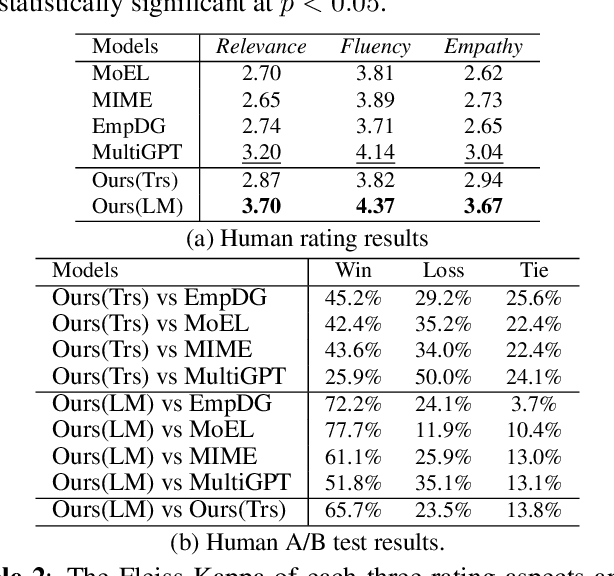
The goal of empathetic response generation is to enhance the ability of dialogue systems to perceive and express emotions in conversations. Current approaches to this task mainly focus on improving the response generation model by recognizing the emotion of the user or predicting a target emotion to guide the generation of responses. Such models only exploit partial information (the user's emotion or the target emotion used as a guiding signal) and do not consider multiple information together. In addition to the emotional style of the response, the intent of the response is also very important for empathetic responding. Thus, we propose a novel empathetic response generation model that can consider multiple state information including emotions and intents simultaneously. Specifically, we introduce a state management method to dynamically update the dialogue states, in which the user's emotion is first recognized, then the target emotion and intent are obtained via predefined shift patterns with the user's emotion as input. The obtained information is used to control the response generation. Experimental results show that dynamically managing different information can help the model generate more empathetic responses compared with several baselines under both automatic and human evaluations.