 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphOTTER: Evolving LLM-based Graph Reasoning for Complex Table Question Answering
Dec 02, 2024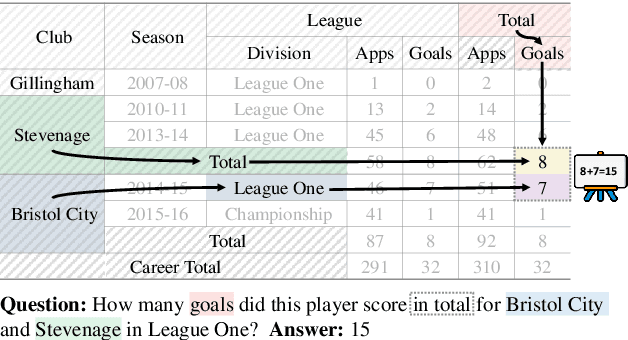

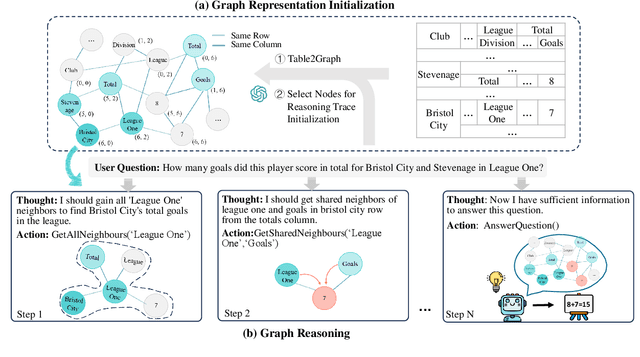
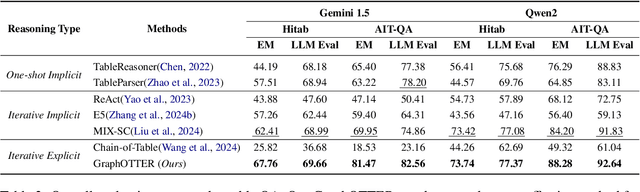
Complex Table Question Answering involves providing accurate answers to specific questions based on intricate tables that exhibit complex layouts and flexible header locations. Despite considerable progress having been made in the LLM era, the reasoning processes of existing methods are often implicit, feeding the entire table into prompts, making it difficult to effectively filter out irrelevant information in the table. To this end, we propose GraphOTTER that explicitly establishes the reasoning process to pinpoint the correct answers. In particular, GraphOTTER leverages a graph-based representation, transforming the complex table into an undirected graph. It then conducts step-by-step reasoning on the graph, with each step guided by a set of pre-defined intermediate reasoning actions. As such, it constructs a clear reasoning path and effectively identifies the answer to a given question. Comprehensive experiments on two benchmark datasets and two LLM backbones demonstrate the effectiveness of GraphOTTER. Further analysis indicates that its success may be attributed to the ability to efficiently filter out irrelevant information, thereby focusing the reasoning process on the most pertinent data. Our code and experimental datasets are available at \url{https://github.com/JDing0521/GraphOTTER}.
DiVa: An Iterative Framework to Harvest More Diverse and Valid Labels from User Comments for Music
Aug 09, 2023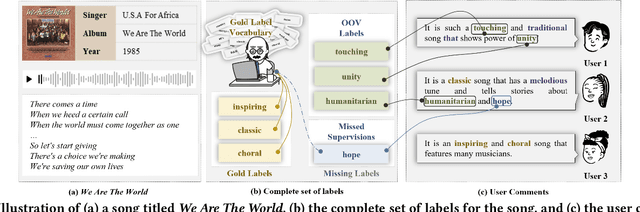

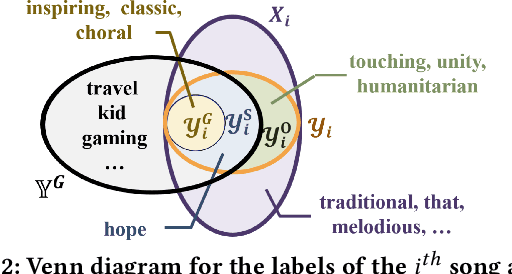
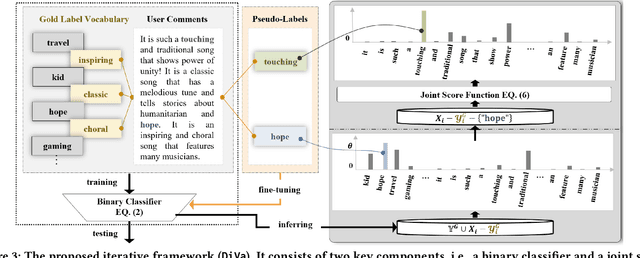
Towards sufficient music searching, it is vital to form a complete set of labels for each song. However, current solutions fail to resolve it as they cannot produce diverse enough mappings to make up for the information missed by the gold labels. Based on the observation that such missing information may already be presented in user comments, we propose to study the automated music labeling in an essential but under-explored setting, where the model is required to harvest more diverse and valid labels from the users' comments given limited gold labels. To this end, we design an iterative framework (DiVa) to harvest more $\underline{\text{Di}}$verse and $\underline{\text{Va}}$lid labels from user comments for music. The framework makes a classifier able to form complete sets of labels for songs via pseudo-labels inferred from pre-trained classifiers and a novel joint score function. The experiment on a densely annotated testing set reveals the superiority of the Diva over state-of-the-art solutions in producing more diverse labels missed by the gold labels. We hope our work can inspire future research on automated music labeling.