 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE2Edev: Benchmarking Large Language Models in End-to-End Software Development Task
Oct 16, 2025E2EDev comprises (i) a fine-grained set of user requirements, (ii) {multiple BDD test scenarios with corresponding Python step implementations for each requirement}, and (iii) a fully automated testing pipeline built on the Behave framework. To ensure its quality while reducing the annotation effort, E2EDev leverages our proposed Human-in-the-Loop Multi-Agent Annotation Framework (HITL-MAA). {By evaluating various E2ESD frameworks and LLM backbones with E2EDev}, our analysis reveals a persistent struggle to effectively solve these tasks, underscoring the critical need for more effective and cost-efficient E2ESD solutions. Our codebase and benchmark are publicly available at https://github.com/SCUNLP/E2EDev.
Investigating Inference-time Scaling for Chain of Multi-modal Thought: A Preliminary Study
Feb 17, 2025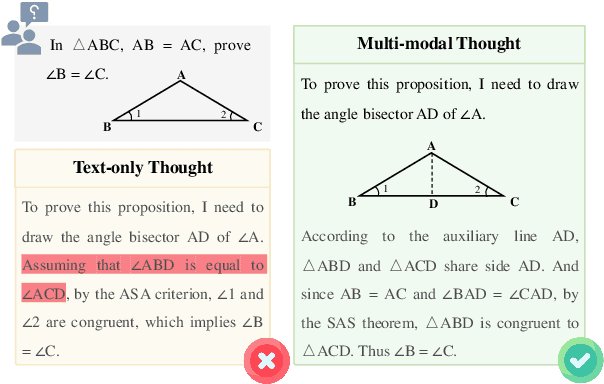
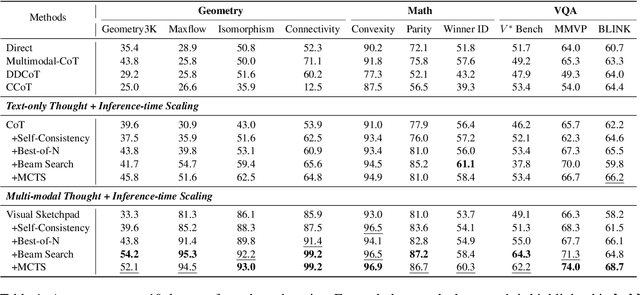
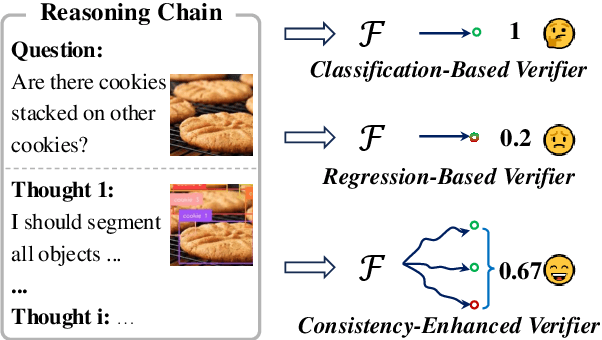
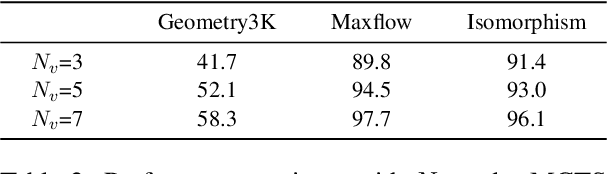
Recently, inference-time scaling of chain-of-thought (CoT) has been demonstrated as a promising approach for addressing multi-modal reasoning tasks. While existing studies have predominantly centered on text-based thinking, the integration of both visual and textual modalities within the reasoning process remains unexplored. In this study, we pioneer the exploration of inference-time scaling with multi-modal thought, aiming to bridge this gap. To provide a comprehensive analysis, we systematically investigate popular sampling-based and tree search-based inference-time scaling methods on 10 challenging tasks spanning various domains. Besides, we uniformly adopt a consistency-enhanced verifier to ensure effective guidance for both methods across different thought paradigms. Results show that multi-modal thought promotes better performance against conventional text-only thought, and blending the two types of thought fosters more diverse thinking. Despite these advantages, multi-modal thoughts necessitate higher token consumption for processing richer visual inputs, which raises concerns in practical applications. We hope that our findings on the merits and drawbacks of this research line will inspire future works in the field.
A Dual-Perspective Metaphor Detection Framework Using Large Language Models
Dec 23, 2024



Metaphor detection, a critical task in natural language processing, involves identifying whether a particular word in a sentence is used metaphorically. Traditional approaches often rely on supervised learning models that implicitly encode semantic relationships based on metaphor theories. However, these methods often suffer from a lack of transparency in their decision-making processes, which undermines the reliability of their predictions. Recent research indicates that LLMs (large language models) exhibit significant potential in metaphor detection. Nevertheless, their reasoning capabilities are constrained by predefined knowledge graphs. To overcome these limitations, we propose DMD, a novel dual-perspective framework that harnesses both implicit and explicit applications of metaphor theories to guide LLMs in metaphor detection and adopts a self-judgment mechanism to validate the responses from the aforementioned forms of guidance. In comparison to previous methods, our framework offers more transparent reasoning processes and delivers more reliable predictions. Experimental results prove the effectiveness of DMD, demonstrating state-of-the-art performance across widely-used datasets.
DiVa: An Iterative Framework to Harvest More Diverse and Valid Labels from User Comments for Music
Aug 09, 2023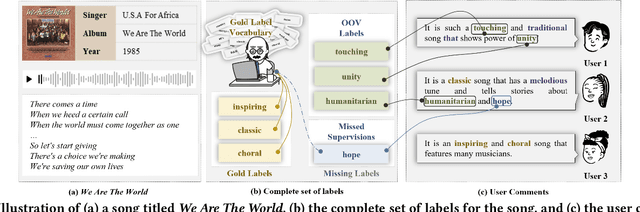

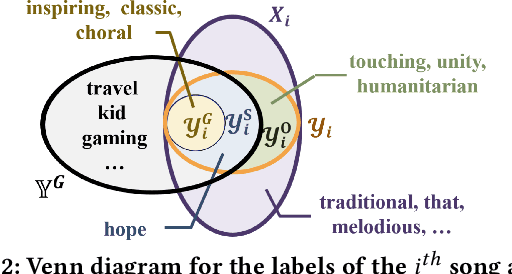
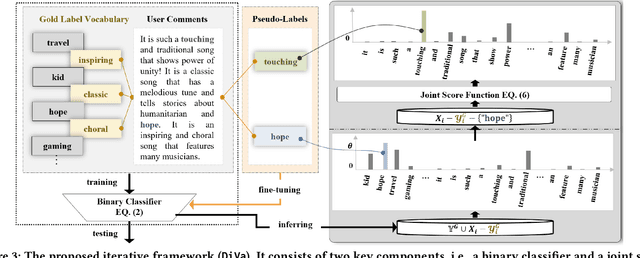
Towards sufficient music searching, it is vital to form a complete set of labels for each song. However, current solutions fail to resolve it as they cannot produce diverse enough mappings to make up for the information missed by the gold labels. Based on the observation that such missing information may already be presented in user comments, we propose to study the automated music labeling in an essential but under-explored setting, where the model is required to harvest more diverse and valid labels from the users' comments given limited gold labels. To this end, we design an iterative framework (DiVa) to harvest more $\underline{\text{Di}}$verse and $\underline{\text{Va}}$lid labels from user comments for music. The framework makes a classifier able to form complete sets of labels for songs via pseudo-labels inferred from pre-trained classifiers and a novel joint score function. The experiment on a densely annotated testing set reveals the superiority of the Diva over state-of-the-art solutions in producing more diverse labels missed by the gold labels. We hope our work can inspire future research on automated music labeling.