 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPCyc: Property-Informed Design of Cyclic Peptides via Automated Cyclization
Jun 11, 2026Cyclic peptides represent a promising class of therapeutic compounds in modern drug discovery, often offering improved stability and binding affinity. However, the de novo design of cyclic peptides remains challenging because methods must identify pocket-adaptive cyclization patterns and linkage sites while simultaneously controlling drug-relevant properties. This challenge is particularly pronounced for recent generative models trained predominantly on linear peptide data, which may fail to capture cyclization-specific constraints. To address the limitation, we introduce APCyc, a target-aware de novo cyclic peptide generation framework that explicitly models cyclization and jointly optimizes multiple essential physicochemical properties. By using an expanded residue vocabulary and explicitly encoding cyclization-site and linkage-type information, APCyc learns cyclization-aware representations and leverages Bayesian posterior guidance to steer sampling toward cyclic peptides satisfying multiple property objectives. Experimental results demonstrate that our model learns target-dependent cyclization preferences, and enables effective and controllable multi-property optimization for cyclic peptide design. The source code of this paper is available at https://github.com/HKUSTGZ-ML4Health-Lab/APCyc.
Can Broad Biomedical Knowledge be Contextualized into Scenario-Grounded Propositions?
May 26, 2026Biomedical discovery often requires connecting broad biomedical knowledge with specific experimental or clinical data. Background knowledge suggests relevant mechanisms but is usually too general to map directly onto dataset variables, while data-driven patterns can be dataset-specific and hard to interpret mechanistically. We study this missing link as knowledge contextualization: transforming broad biomedical knowledge into evidence-supported, scenario-grounded propositions that domain experts can inspect, replay, and validate. We propose SCENE, a bi-level multi-agent framework that treats knowledge contextualization as iterative search. The upper level converts broad knowledge into search directions and grounds them in the dataset schema. The lower level executes these directions through multi-objective optimization to identify concrete propositions that balance evidential strength and data support. Feedback between the two levels progressively refines the search. We evaluate SCENE in two settings: discovering patient subgroups with heterogeneous treatment benefits in clinical trial scenarios, and identifying context-specific biological responses in LINCS L1000 studies. In clinical trials, SCENE discovers specific, well-supported subgroups and outperforms existing baselines. In L1000 studies, SCENE identifies perturbational contexts with strong target-response matching and high positive rates. These results show that SCENE bridges broad knowledge and scenario-specific evidence, producing traceable, inspectable hypotheses for follow-up validation.
Don't Retrain, Just Reuse: Recovering Dual-Target Molecules from Single-Target Diffusion Models
May 25, 2026Designing a single molecule that modulates two targets is a promising strategy for polypharmacology, but it remains substantially harder than standard single-target generation because one candidate must satisfy two binding requirements while preserving drug-likeness and synthesizability. Existing dual-target generative methods typically introduce dual-target capability by either retraining the generator or intervening in the diffusion process during sampling. The former can be costly and difficult to stabilize when dual-target supervision is sparse, while the latter may be sensitive to denoising-time target balancing and competing update directions. These limitations motivate a generator-preserving alternative that keeps the pretrained prior intact: can dual-target candidates instead be recovered from the input space of a frozen single-target diffusion model, without modifying its parameters or denoising dynamics? We formulate this task as a constrained multi-objective optimization problem and propose REUSE, a hierarchical evolutionary input-space search framework that combines pair-conditioned exploration with structured multi-stage selection to enforce dual-target affinity, chemical quality, and diversity. Experiments show that, compared with methods that modify the diffusion process, REUSE consistently improves dual-target affinity and balance, achieving a 20.9-percentage-point gain in Dual High Affinity over the strongest prior baseline while maintaining competitive molecular quality.
Respiration Monitoring of Multiple People using Multi-site FMCW SISO Radar Systems
Apr 14, 2026Continuous contactless respiration monitoring of co-sleeping subjects faces a dilemma: conventional single-site multiple-input multiple-output (MIMO) radars struggle with limited angular resolution for closely spaced individuals, while distributed radar networks typically require complex hardware synchronization. To address these limitations, this paper proposes non-coherent multi-site single-input-single-output (SISO) radar systems that completely eliminate the need for physical synchronization cables or common reference clocks. The fundamental challenge of ghost target ambiguity in such non-coherent multilateration is resolved through a novel physiological-feature-assisted suppression technique. By exploiting the inherent statistical independence of individual respiratory rhythms, true target locations are robustly distinguished from ghosts via cross-correlation analysis. Experimental validation demonstrates that the proposed system can accurately resolve two subjects spaced less than 20 cm apart, surpassing the resolution limits of traditional compact MIMO arrays, while achieving a respiration rate estimation accuracy of 0.7 bpm root mean square error (RMSE) compared to contact-based ground truth.
Stable Reasoning, Unstable Responses: Mitigating LLM Deception via Stability Asymmetry
Mar 27, 2026As Large Language Models (LLMs) expand in capability and application scope, their trustworthiness becomes critical. A vital risk is intrinsic deception, wherein models strategically mislead users to achieve their own objectives. Existing alignment approaches based on chain-of-thought (CoT) monitoring supervise explicit reasoning traces. However, under optimization pressure, models are incentivized to conceal deceptive reasoning, rendering semantic supervision fundamentally unreliable. Grounded in cognitive psychology, we hypothesize that a deceptive LLM maintains a stable internal belief in its CoT while its external response remains fragile under perturbation. We term this phenomenon stability asymmetry and quantify it by measuring the contrast between internal CoT stability and external response stability under perturbation. Building on this structural signature, we propose the Stability Asymmetry Regularization (SAR), a novel alignment objective that penalizes this distributional asymmetry during reinforcement learning. Unlike CoT monitoring, SAR targets the statistical structure of model outputs, rendering it robust to semantic concealment. Extensive experiments confirm that stability asymmetry reliably identifies deceptive behavior, and that SAR effectively suppresses intrinsic deception without degrading general model capability.
AllMem: A Memory-centric Recipe for Efficient Long-context Modeling
Feb 14, 2026Large Language Models (LLMs) encounter significant performance bottlenecks in long-sequence tasks due to the computational complexity and memory overhead inherent in the self-attention mechanism. To address these challenges, we introduce \textsc{AllMem}, a novel and efficient hybrid architecture that integrates Sliding Window Attention (SWA) with non-linear Test-Time Training (TTT) memory networks. \textsc{AllMem} enables models to effectively scale to ultra-long contexts while mitigating catastrophic forgetting. This approach not only overcomes the representation constraints typical of linear memory models but also significantly reduces the computational and memory footprint during long-sequence inference. Furthermore, we implement a Memory-Efficient Fine-Tuning strategy to replace standard attention layers in pre-trained models with memory-augmented sliding window layers. This framework facilitates the efficient transformation of any off-the-shelf pre-trained LLM into an \textsc{AllMem}-based architecture. Empirical evaluations confirm that our 4k window model achieves near-lossless performance on 37k LongBench with a marginal 0.83 drop compared to full attention. Furthermore, on InfiniteBench at a 128k context, our 8k window variant outperforms full attention, which validates the effectiveness of our parameterized memory in mitigating noise and maintaining robust long-range modeling without the prohibitive costs of global attention.
Region-aware Spatiotemporal Modeling with Collaborative Domain Generalization for Cross-Subject EEG Emotion Recognition
Jan 22, 2026Cross-subject EEG-based emotion recognition (EER) remains challenging due to strong inter-subject variability, which induces substantial distribution shifts in EEG signals, as well as the high complexity of emotion-related neural representations in both spatial organization and temporal evolution. Existing approaches typically improve spatial modeling, temporal modeling, or generalization strategies in isolation, which limits their ability to align representations across subjects while capturing multi-scale dynamics and suppressing subject-specific bias within a unified framework. To address these gaps, we propose a Region-aware Spatiotemporal Modeling framework with Collaborative Domain Generalization (RSM-CoDG) for cross-subject EEG emotion recognition. RSM-CoDG incorporates neuroscience priors derived from functional brain region partitioning to construct region-level spatial representations, thereby improving cross-subject comparability. It also employs multi-scale temporal modeling to characterize the dynamic evolution of emotion-evoked neural activity. In addition, the framework employs a collaborative domain generalization strategy, incorporating multidimensional constraints to reduce subject-specific bias in a fully unseen target subject setting, which enhances the generalization to unknown individuals. Extensive experimental results on SEED series datasets demonstrate that RSM-CoDG consistently outperforms existing competing methods, providing an effective approach for improving robustness. The source code is available at https://github.com/RyanLi-X/RSM-CoDG.
3D Deep-learning-based Segmentation of Human Skin Sweat Glands and Their 3D Morphological Response to Temperature Variations
Apr 24, 2025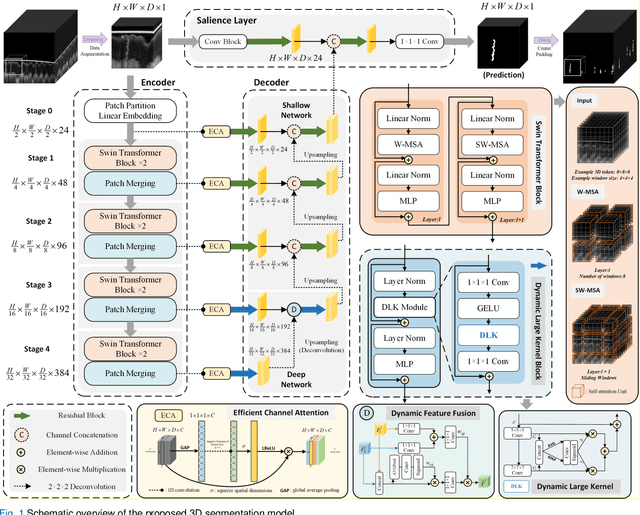
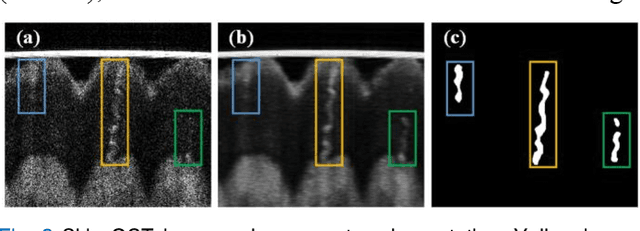
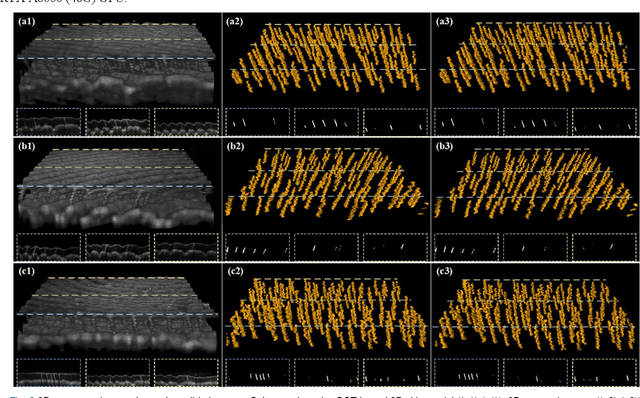
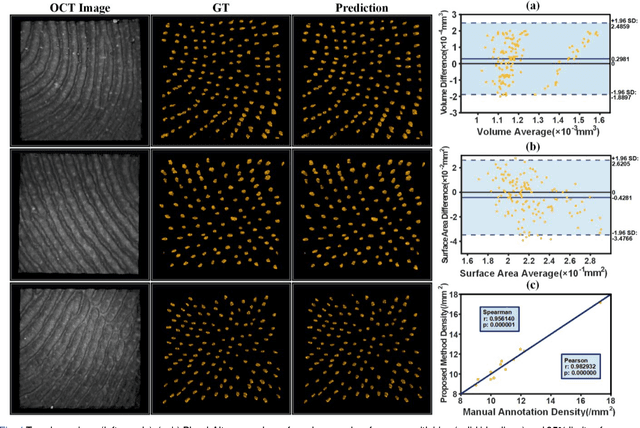
Skin, the primary regulator of heat exchange, relies on sweat glands for thermoregulation. Alterations in sweat gland morphology play a crucial role in various pathological conditions and clinical diagnoses. Current methods for observing sweat gland morphology are limited by their two-dimensional, in vitro, and destructive nature, underscoring the urgent need for real-time, non-invasive, quantifiable technologies. We proposed a novel three-dimensional (3D) transformer-based multi-object segmentation framework, integrating a sliding window approach, joint spatial-channel attention mechanism, and architectural heterogeneity between shallow and deep layers. Our proposed network enables precise 3D sweat gland segmentation from skin volume data captured by optical coherence tomography (OCT). For the first time, subtle variations of sweat gland 3D morphology in response to temperature changes, have been visualized and quantified. Our approach establishes a benchmark for normal sweat gland morphology and provides a real-time, non-invasive tool for quantifying 3D structural parameters. This enables the study of individual variability and pathological changes in sweat gland structure, advancing dermatological research and clinical applications, including thermoregulation and bromhidrosis treatment.
Listen to the Patient: Enhancing Medical Dialogue Generation with Patient Hallucination Detection and Mitigation
Oct 08, 2024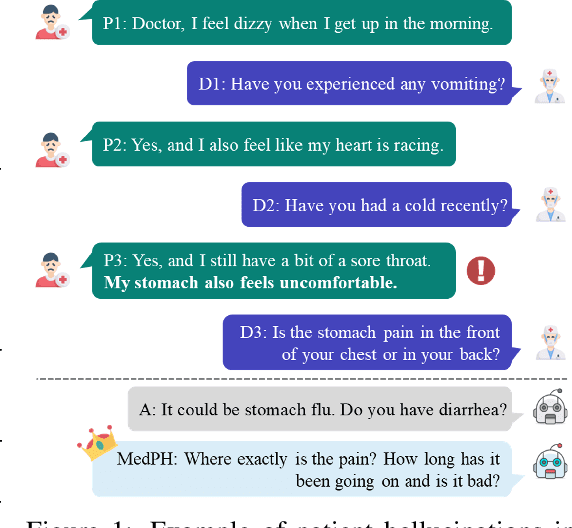
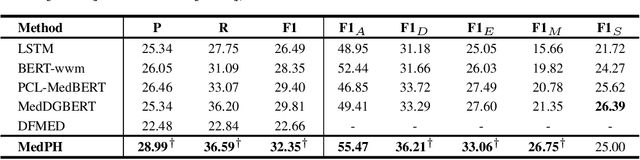
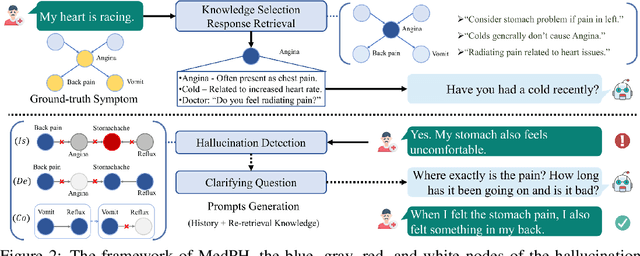
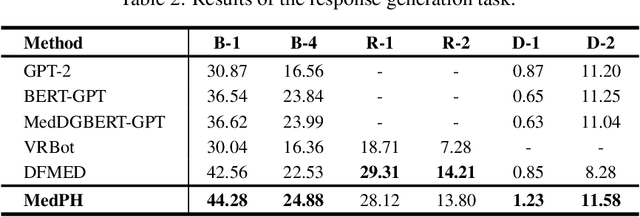
Medical dialogue systems aim to provide medical services through patient-agent conversations. Previous methods typically regard patients as ideal users, focusing mainly on common challenges in dialogue systems, while neglecting the potential biases or misconceptions that might be introduced by real patients, who are typically non-experts. This study investigates the discrepancy between patients' expressions during medical consultations and their actual health conditions, defined as patient hallucination. Such phenomena often arise from patients' lack of knowledge and comprehension, concerns, and anxieties, resulting in the transmission of inaccurate or wrong information during consultations. To address this issue, we propose MedPH, a Medical dialogue generation method for mitigating the problem of Patient Hallucinations designed to detect and cope with hallucinations. MedPH incorporates a detection method that utilizes one-dimensional structural entropy over a temporal dialogue entity graph, and a mitigation strategy based on hallucination-related information to guide patients in expressing their actual conditions. Experimental results indicate the high effectiveness of MedPH when compared to existing approaches in both medical entity prediction and response generation tasks, while also demonstrating its effectiveness in mitigating hallucinations within interactive scenarios.
GRSN: Gated Recurrent Spiking Neurons for POMDPs and MARL
Apr 24, 2024



Spiking neural networks (SNNs) are widely applied in various fields due to their energy-efficient and fast-inference capabilities. Applying SNNs to reinforcement learning (RL) can significantly reduce the computational resource requirements for agents and improve the algorithm's performance under resource-constrained conditions. However, in current spiking reinforcement learning (SRL) algorithms, the simulation results of multiple time steps can only correspond to a single-step decision in RL. This is quite different from the real temporal dynamics in the brain and also fails to fully exploit the capacity of SNNs to process temporal data. In order to address this temporal mismatch issue and further take advantage of the inherent temporal dynamics of spiking neurons, we propose a novel temporal alignment paradigm (TAP) that leverages the single-step update of spiking neurons to accumulate historical state information in RL and introduces gated units to enhance the memory capacity of spiking neurons. Experimental results show that our method can solve partially observable Markov decision processes (POMDPs) and multi-agent cooperation problems with similar performance as recurrent neural networks (RNNs) but with about 50% power consumption.