 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Deep-learning-based Segmentation of Human Skin Sweat Glands and Their 3D Morphological Response to Temperature Variations
Apr 24, 2025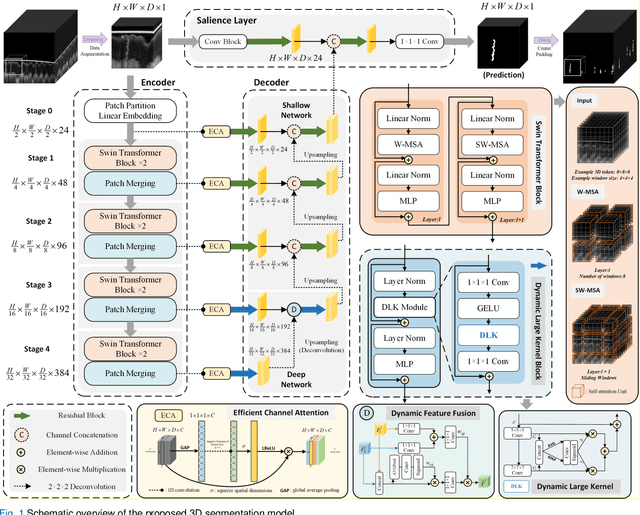
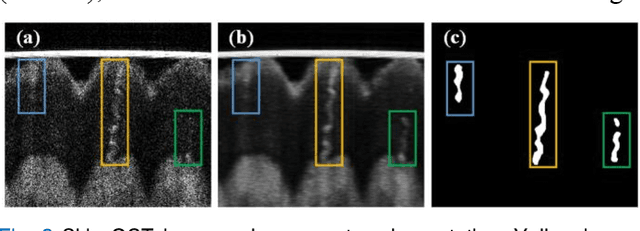
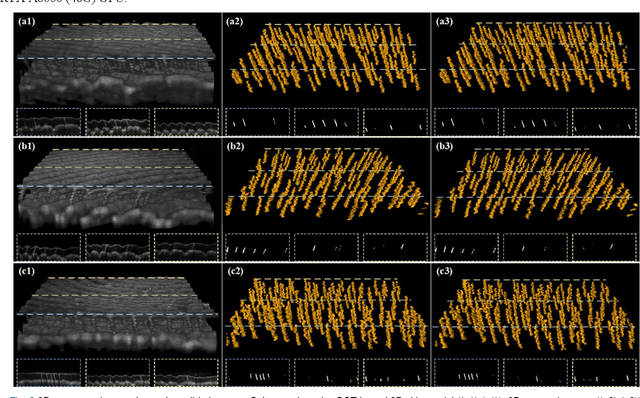
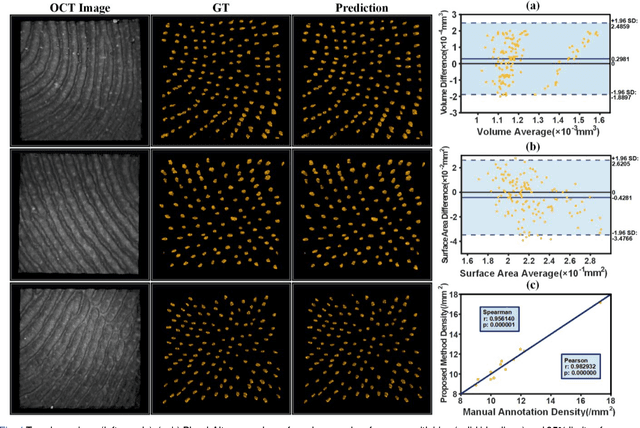
Skin, the primary regulator of heat exchange, relies on sweat glands for thermoregulation. Alterations in sweat gland morphology play a crucial role in various pathological conditions and clinical diagnoses. Current methods for observing sweat gland morphology are limited by their two-dimensional, in vitro, and destructive nature, underscoring the urgent need for real-time, non-invasive, quantifiable technologies. We proposed a novel three-dimensional (3D) transformer-based multi-object segmentation framework, integrating a sliding window approach, joint spatial-channel attention mechanism, and architectural heterogeneity between shallow and deep layers. Our proposed network enables precise 3D sweat gland segmentation from skin volume data captured by optical coherence tomography (OCT). For the first time, subtle variations of sweat gland 3D morphology in response to temperature changes, have been visualized and quantified. Our approach establishes a benchmark for normal sweat gland morphology and provides a real-time, non-invasive tool for quantifying 3D structural parameters. This enables the study of individual variability and pathological changes in sweat gland structure, advancing dermatological research and clinical applications, including thermoregulation and bromhidrosis treatment.
PFB-Diff: Progressive Feature Blending Diffusion for Text-driven Image Editing
Jun 28, 2023



Diffusion models have showcased their remarkable capability to synthesize diverse and high-quality images, sparking interest in their application for real image editing. However, existing diffusion-based approaches for local image editing often suffer from undesired artifacts due to the pixel-level blending of the noised target images and diffusion latent variables, which lack the necessary semantics for maintaining image consistency. To address these issues, we propose PFB-Diff, a Progressive Feature Blending method for Diffusion-based image editing. Unlike previous methods, PFB-Diff seamlessly integrates text-guided generated content into the target image through multi-level feature blending. The rich semantics encoded in deep features and the progressive blending scheme from high to low levels ensure semantic coherence and high quality in edited images. Additionally, we introduce an attention masking mechanism in the cross-attention layers to confine the impact of specific words to desired regions, further improving the performance of background editing. PFB-Diff can effectively address various editing tasks, including object/background replacement and object attribute editing. Our method demonstrates its superior performance in terms of image fidelity, editing accuracy, efficiency, and faithfulness to the original image, without the need for fine-tuning or training.
IA-FaceS: A Bidirectional Method for Semantic Face Editing
Mar 25, 2022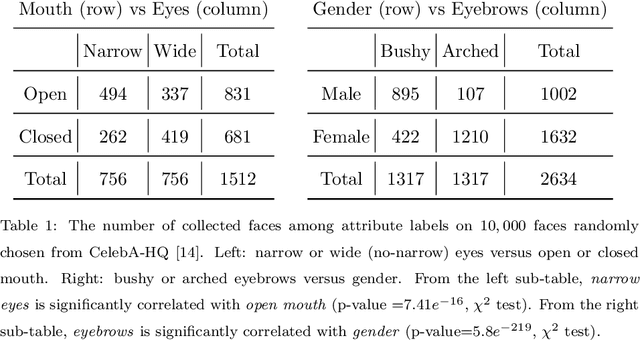
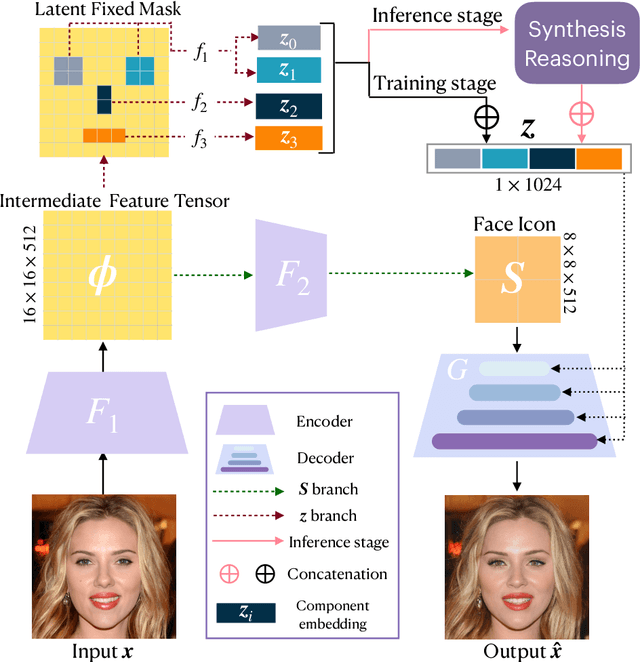


Semantic face editing has achieved substantial progress in recent years. Known as a growingly popular method, latent space manipulation performs face editing by changing the latent code of an input face to liberate users from painting skills. However, previous latent space manipulation methods usually encode an entire face into a single low-dimensional embedding, which constrains the reconstruction capacity and the control flexibility of facial components, such as eyes and nose. This paper proposes IA-FaceS as a bidirectional method for disentangled face attribute manipulation as well as flexible, controllable component editing without the need for segmentation masks or sketches in the original image. To strike a balance between the reconstruction capacity and the control flexibility, the encoder is designed as a multi-head structure to yield embeddings for reconstruction and control, respectively: a high-dimensional tensor with spatial properties for consistent reconstruction and four low-dimensional facial component embeddings for semantic face editing. Manipulating the separate component embeddings can help achieve disentangled attribute manipulation and flexible control of facial components. To further disentangle the highly-correlated components, a component adaptive modulation (CAM) module is proposed for the decoder. The semantic single-eye editing is developed for the first time without any input visual guidance, such as segmentation masks or sketches. According to the experimental results, IA-FaceS establishes a good balance between maintaining image details and performing flexible face manipulation. Both quantitative and qualitative results indicate that the proposed method outperforms the other techniques in reconstruction, face attribute manipulation, and component transfer.
SGE net: Video object detection with squeezed GRU and information entropy map
Jun 14, 2021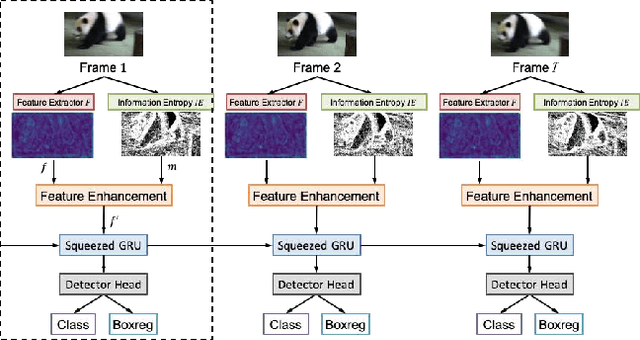
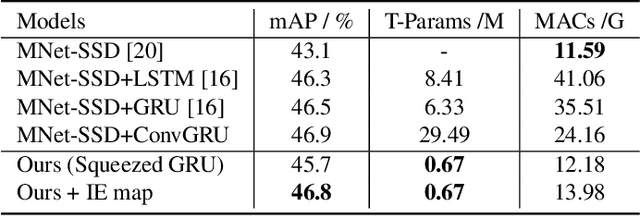
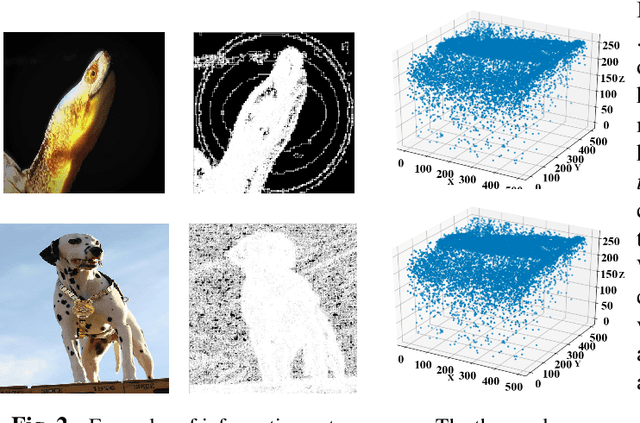
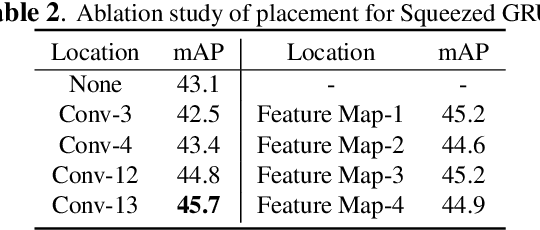
Recently, deep learning based video object detection has attracted more and more attention. Compared with object detection of static images, video object detection is more challenging due to the motion of objects, while providing rich temporal information. The RNN-based algorithm is an effective way to enhance detection performance in videos with temporal information. However, most studies in this area only focus on accuracy while ignoring the calculation cost and the number of parameters. In this paper, we propose an efficient method that combines channel-reduced convolutional GRU (Squeezed GRU), and Information Entropy map for video object detection (SGE-Net). The experimental results validate the accuracy improvement, computational savings of the Squeezed GRU, and superiority of the information entropy attention mechanism on the classification performance. The mAP has increased by 3.7 contrasted with the baseline, and the number of parameters has decreased from 6.33 million to 0.67 million compared with the standard GRU.
Revisit Lmser and its further development based on convolutional layers
Apr 12, 2019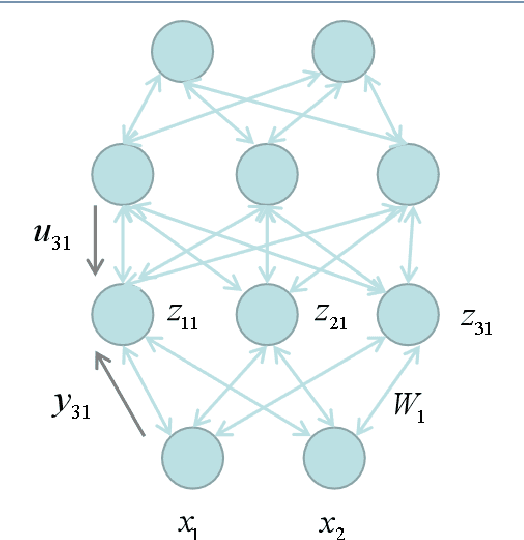
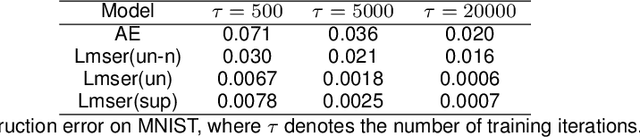

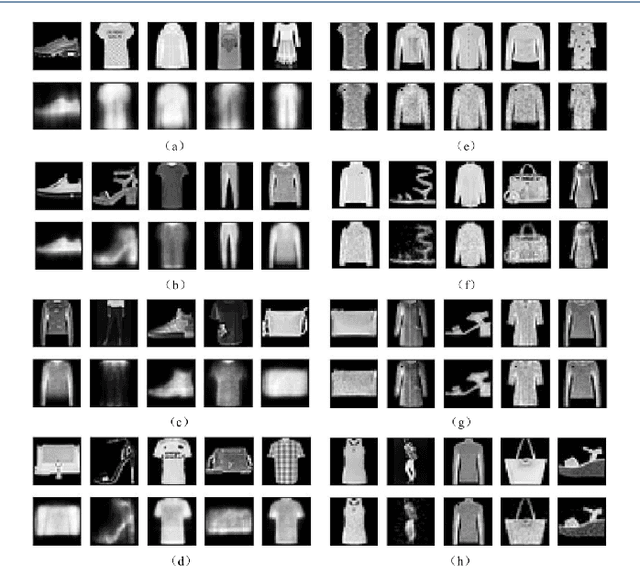
Proposed in 1991, Least Mean Square Error Reconstruction for self-organizing network, shortly Lmser, was a further development of the traditional auto-encoder (AE) by folding the architecture with respect to the central coding layer and thus leading to the features of symmetric weights and neurons, as well as jointly supervised and unsupervised learning. However, its advantages were only demonstrated in a one-hidden-layer implementation due to the lack of computing resources and big data at that time. In this paper, we revisit Lmser from the perspective of deep learning, develop Lmser network based on multiple convolutional layers, which is more suitable for image-related tasks, and confirm several Lmser functions with preliminary demonstrations on image recognition, reconstruction, association recall, and so on. Experiments demonstrate that Lmser indeed works as indicated in the original paper, and it has promising performance in various applications.