 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Scientific General Intelligence of LLMs with Scientist-Aligned Workflows
Dec 18, 2025Despite advances in scientific AI, a coherent framework for Scientific General Intelligence (SGI)-the ability to autonomously conceive, investigate, and reason across scientific domains-remains lacking. We present an operational SGI definition grounded in the Practical Inquiry Model (PIM: Deliberation, Conception, Action, Perception) and operationalize it via four scientist-aligned tasks: deep research, idea generation, dry/wet experiments, and experimental reasoning. SGI-Bench comprises over 1,000 expert-curated, cross-disciplinary samples inspired by Science's 125 Big Questions, enabling systematic evaluation of state-of-the-art LLMs. Results reveal gaps: low exact match (10--20%) in deep research despite step-level alignment; ideas lacking feasibility and detail; high code executability but low execution result accuracy in dry experiments; low sequence fidelity in wet protocols; and persistent multimodal comparative-reasoning challenges. We further introduce Test-Time Reinforcement Learning (TTRL), which optimizes retrieval-augmented novelty rewards at inference, enhancing hypothesis novelty without reference answer. Together, our PIM-grounded definition, workflow-centric benchmark, and empirical insights establish a foundation for AI systems that genuinely participate in scientific discovery.
Hierarchical Schedule Optimization for Fast and Robust Diffusion Model Sampling
Nov 12, 2025


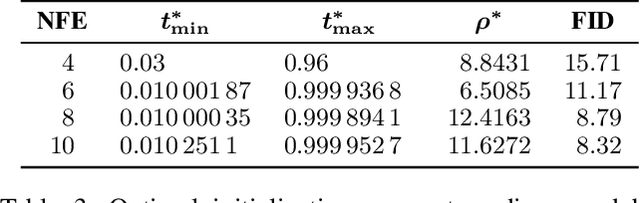
Diffusion probabilistic models have set a new standard for generative fidelity but are hindered by a slow iterative sampling process. A powerful training-free strategy to accelerate this process is Schedule Optimization, which aims to find an optimal distribution of timesteps for a fixed and small Number of Function Evaluations (NFE) to maximize sample quality. To this end, a successful schedule optimization method must adhere to four core principles: effectiveness, adaptivity, practical robustness, and computational efficiency. However, existing paradigms struggle to satisfy these principles simultaneously, motivating the need for a more advanced solution. To overcome these limitations, we propose the Hierarchical-Schedule-Optimizer (HSO), a novel and efficient bi-level optimization framework. HSO reframes the search for a globally optimal schedule into a more tractable problem by iteratively alternating between two synergistic levels: an upper-level global search for an optimal initialization strategy and a lower-level local optimization for schedule refinement. This process is guided by two key innovations: the Midpoint Error Proxy (MEP), a solver-agnostic and numerically stable objective for effective local optimization, and the Spacing-Penalized Fitness (SPF) function, which ensures practical robustness by penalizing pathologically close timesteps. Extensive experiments show that HSO sets a new state-of-the-art for training-free sampling in the extremely low-NFE regime. For instance, with an NFE of just 5, HSO achieves a remarkable FID of 11.94 on LAION-Aesthetics with Stable Diffusion v2.1. Crucially, this level of performance is attained not through costly retraining, but with a one-time optimization cost of less than 8 seconds, presenting a highly practical and efficient paradigm for diffusion model acceleration.
Vertex Features for Neural Global Illumination
Aug 11, 2025Recent research on learnable neural representations has been widely adopted in the field of 3D scene reconstruction and neural rendering applications. However, traditional feature grid representations often suffer from substantial memory footprint, posing a significant bottleneck for modern parallel computing hardware. In this paper, we present neural vertex features, a generalized formulation of learnable representation for neural rendering tasks involving explicit mesh surfaces. Instead of uniformly distributing neural features throughout 3D space, our method stores learnable features directly at mesh vertices, leveraging the underlying geometry as a compact and structured representation for neural processing. This not only optimizes memory efficiency, but also improves feature representation by aligning compactly with the surface using task-specific geometric priors. We validate our neural representation across diverse neural rendering tasks, with a specific emphasis on neural radiosity. Experimental results demonstrate that our method reduces memory consumption to only one-fifth (or even less) of grid-based representations, while maintaining comparable rendering quality and lowering inference overhead.
Swarm Intelligence Enhanced Reasoning: A Density-Driven Framework for LLM-Based Multi-Agent Optimization
May 21, 2025Recently, many approaches, such as Chain-of-Thought (CoT) prompting and Multi-Agent Debate (MAD), have been proposed to further enrich Large Language Models' (LLMs) complex problem-solving capacities in reasoning scenarios. However, these methods may fail to solve complex problems due to the lack of ability to find optimal solutions. Swarm Intelligence has been serving as a powerful tool for finding optima in the field of traditional optimization problems. To this end, we propose integrating swarm intelligence into the reasoning process by introducing a novel Agent-based Swarm Intelligence (ASI) paradigm. In this paradigm, we formulate LLM reasoning as an optimization problem and use a swarm intelligence scheme to guide a group of LLM-based agents in collaboratively searching for optimal solutions. To avoid swarm intelligence getting trapped in local optima, we further develop a Swarm Intelligence Enhancing Reasoning (SIER) framework, which develops a density-driven strategy to enhance the reasoning ability. To be specific, we propose to perform kernel density estimation and non-dominated sorting to optimize both solution quality and diversity simultaneously. In this case, SIER efficiently enhances solution space exploration through expanding the diversity of the reasoning path. Besides, a step-level quality evaluation is used to help agents improve solution quality by correcting low-quality intermediate steps. Then, we use quality thresholds to dynamically control the termination of exploration and the selection of candidate steps, enabling a more flexible and efficient reasoning process. Extensive experiments are ...
SeisMoLLM: Advancing Seismic Monitoring via Cross-modal Transfer with Pre-trained Large Language Model
Feb 27, 2025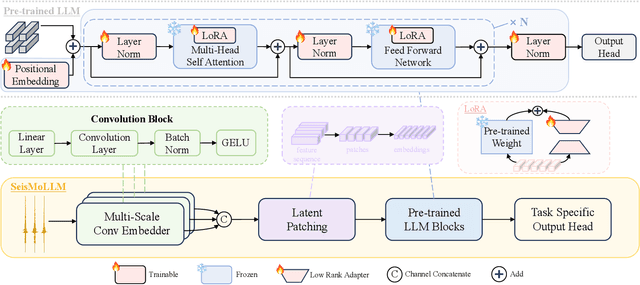
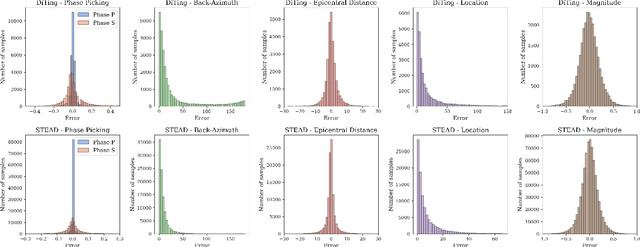
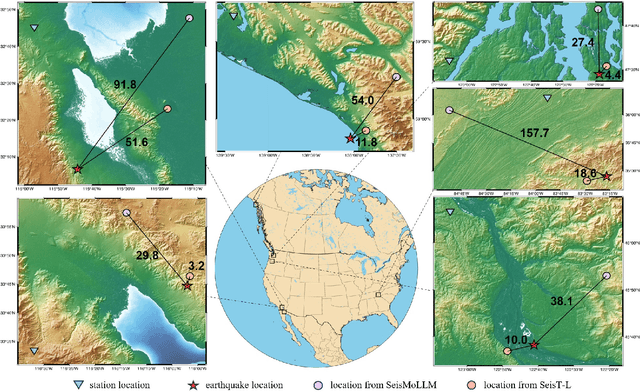
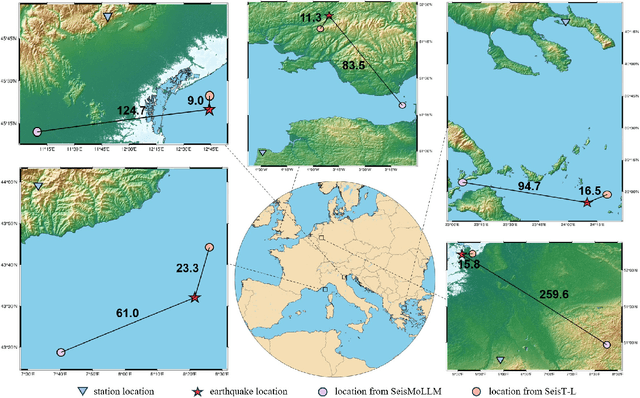
Recent advances in deep learning have revolutionized seismic monitoring, yet developing a foundation model that performs well across multiple complex tasks remains challenging, particularly when dealing with degraded signals or data scarcity. This work presents SeisMoLLM, the first foundation model that utilizes cross-modal transfer for seismic monitoring, to unleash the power of large-scale pre-training from a large language model without requiring direct pre-training on seismic datasets. Through elaborate waveform tokenization and fine-tuning of pre-trained GPT-2 model, SeisMoLLM achieves state-of-the-art performance on the DiTing and STEAD datasets across five critical tasks: back-azimuth estimation, epicentral distance estimation, magnitude estimation, phase picking, and first-motion polarity classification. It attains 36 best results out of 43 task metrics and 12 top scores out of 16 few-shot generalization metrics, with many relative improvements ranging from 10% to 50%. In addition to its superior performance, SeisMoLLM maintains efficiency comparable to or even better than lightweight models in both training and inference. These findings establish SeisMoLLM as a promising foundation model for practical seismic monitoring and highlight cross-modal transfer as an exciting new direction for earthquake studies, showcasing the potential of advanced deep learning techniques to propel seismology research forward.
DispFormer: Pretrained Transformer for Flexible Dispersion Curve Inversion from Global Synthesis to Regional Applications
Jan 08, 2025



Surface wave dispersion curve inversion is essential for estimating subsurface Shear-wave velocity ($v_s$), yet traditional methods often struggle to balance computational efficiency with inversion accuracy. While deep learning approaches show promise, previous studies typically require large amounts of labeled data and struggle with real-world datasets that have varying period ranges, missing data, and low signal-to-noise ratios. This study proposes DispFormer, a transformer-based neural network for inverting the $v_s$ profile from Rayleigh-wave phase and group dispersion curves. DispFormer processes dispersion data at each period independently, thereby allowing it to handle data of varying lengths without requiring network modifications or alignment between training and testing data. The performance is demonstrated by pre-training it on a global synthetic dataset and testing it on two regional synthetic datasets using zero-shot and few-shot strategies. Results indicate that zero-shot DispFormer, even without any labeled data, produces inversion profiles that match well with the ground truth, providing a deployable initial model generator to assist traditional methods. When labeled data is available, few-shot DispFormer outperforms traditional methods with only a small number of labels. Furthermore, real-world tests indicate that DispFormer effectively handles varying length data, and yields lower data residuals than reference models. These findings demonstrate that DispFormer provides a robust foundation model for dispersion curve inversion and is a promising approach for broader applications.
Fast Information Streaming Handler (FisH): A Unified Seismic Neural Network for Single Station Real-Time Earthquake Early Warning
Aug 13, 2024



Existing EEW approaches often treat phase picking, location estimation, and magnitude estimation as separate tasks, lacking a unified framework. Additionally, most deep learning models in seismology rely on full three-component waveforms and are not suitable for real-time streaming data. To address these limitations, we propose a novel unified seismic neural network called Fast Information Streaming Handler (FisH). FisH is designed to process real-time streaming seismic data and generate simultaneous results for phase picking, location estimation, and magnitude estimation in an end-to-end fashion. By integrating these tasks within a single model, FisH simplifies the overall process and leverages the nonlinear relationships between tasks for improved performance. The FisH model utilizes RetNet as its backbone, enabling parallel processing during training and recurrent handling during inference. This capability makes FisH suitable for real-time applications, reducing latency in EEW systems. Extensive experiments conducted on the STEAD benchmark dataset provide strong validation for the effectiveness of our proposed FisH model. The results demonstrate that FisH achieves impressive performance across multiple seismic event detection and characterization tasks. Specifically, it achieves an F1 score of 0.99/0.96. Also, FisH demonstrates precise earthquake location estimation, with location error of only 6.0km, a distance error of 2.6km, and a back-azimuth error of 19{\deg}. The model also exhibits accurate earthquake magnitude estimation, with a magnitude error of just 0.14. Additionally, FisH is capable of generating real-time estimations, providing location and magnitude estimations with a location error of 8.06km and a magnitude error of 0.18 within a mere 3 seconds after the P-wave arrives.
FengWu: Pushing the Skillful Global Medium-range Weather Forecast beyond 10 Days Lead
Apr 06, 2023



We present FengWu, an advanced data-driven global medium-range weather forecast system based on Artificial Intelligence (AI). Different from existing data-driven weather forecast methods, FengWu solves the medium-range forecast problem from a multi-modal and multi-task perspective. Specifically, a deep learning architecture equipped with model-specific encoder-decoders and cross-modal fusion Transformer is elaborately designed, which is learned under the supervision of an uncertainty loss to balance the optimization of different predictors in a region-adaptive manner. Besides this, a replay buffer mechanism is introduced to improve medium-range forecast performance. With 39-year data training based on the ERA5 reanalysis, FengWu is able to accurately reproduce the atmospheric dynamics and predict the future land and atmosphere states at 37 vertical levels on a 0.25{\deg} latitude-longitude resolution. Hindcasts of 6-hourly weather in 2018 based on ERA5 demonstrate that FengWu performs better than GraphCast in predicting 80\% of the 880 reported predictands, e.g., reducing the root mean square error (RMSE) of 10-day lead global z500 prediction from 733 to 651 $m^{2}/s^2$. In addition, the inference cost of each iteration is merely 600ms on NVIDIA Tesla A100 hardware. The results suggest that FengWu can significantly improve the forecast skill and extend the skillful global medium-range weather forecast out to 10.75 days lead (with ACC of z500 > 0.6) for the first time.
Slow Motion Matters: A Slow Motion Enhanced Network for Weakly Supervised Temporal Action Localization
Nov 21, 2022



Weakly supervised temporal action localization (WTAL) aims to localize actions in untrimmed videos with only weak supervision information (e.g. video-level labels). Most existing models handle all input videos with a fixed temporal scale. However, such models are not sensitive to actions whose pace of the movements is different from the ``normal" speed, especially slow-motion action instances, which complete the movements with a much slower speed than their counterparts with a normal speed. Here arises the slow-motion blurred issue: It is hard to explore salient slow-motion information from videos at ``normal" speed. In this paper, we propose a novel framework termed Slow Motion Enhanced Network (SMEN) to improve the ability of a WTAL network by compensating its sensitivity on slow-motion action segments. The proposed SMEN comprises a Mining module and a Localization module. The mining module generates mask to mine slow-motion-related features by utilizing the relationships between the normal motion and slow motion; while the localization module leverages the mined slow-motion features as complementary information to improve the temporal action localization results. Our proposed framework can be easily adapted by existing WTAL networks and enable them be more sensitive to slow-motion actions. Extensive experiments on three benchmarks are conducted, which demonstrate the high performance of our proposed framework.
3D-QueryIS: A Query-based Framework for 3D Instance Segmentation
Nov 17, 2022Previous top-performing methods for 3D instance segmentation often maintain inter-task dependencies and the tendency towards a lack of robustness. Besides, inevitable variations of different datasets make these methods become particularly sensitive to hyper-parameter values and manifest poor generalization capability. In this paper, we address the aforementioned challenges by proposing a novel query-based method, termed as 3D-QueryIS, which is detector-free, semantic segmentation-free, and cluster-free. Specifically, we propose to generate representative points in an implicit manner, and use them together with the initial queries to generate the informative instance queries. Then, the class and binary instance mask predictions can be produced by simply applying MLP layers on top of the instance queries and the extracted point cloud embeddings. Thus, our 3D-QueryIS is free from the accumulated errors caused by the inter-task dependencies. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness and efficiency of our proposed 3D-QueryIS method.