 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeopleSearchBench: A Multi-Dimensional Benchmark for Evaluating AI-Powered People Search Platforms
Mar 29, 2026AI-powered people search platforms are increasingly used in recruiting, sales prospecting, and professional networking, yet no widely accepted benchmark exists for evaluating their performance. We introduce PeopleSearchBench, an open-source benchmark that compares four people search platforms on 119 real-world queries across four use cases: corporate recruiting, B2B sales prospecting, expert search with deterministic answers, and influencer/KOL discovery. A key contribution is Criteria-Grounded Verification, a factual relevance pipeline that extracts explicit, verifiable criteria from each query and uses live web search to determine whether returned people satisfy them. This produces binary relevance judgments grounded in factual verification rather than subjective holistic LLM-as-judge scores. We evaluate systems on three dimensions: Relevance Precision (padded nDCG@10), Effective Coverage (task completion and qualified result yield), and Information Utility (profile completeness and usefulness), averaged equally into an overall score. Lessie, a specialized AI people search agent, performs best overall, scoring 65.2, 18.5% higher than the second-ranked system, and is the only system to achieve 100% task completion across all 119 queries. We also report confidence intervals, human validation of the verification pipeline (Cohen's kappa = 0.84), ablations, and full documentation of queries, prompts, and normalization procedures. Code, query definitions, and aggregated results are available on GitHub.
Stop Treating Collisions Equally: Qualification-Aware Semantic ID Learning for Recommendation at Industrial Scale
Feb 28, 2026Semantic IDs (SIDs) are compact discrete representations derived from multimodal item features, serving as a unified abstraction for ID-based and generative recommendation. However, learning high-quality SIDs remains challenging due to two issues. (1) Collision problem: the quantized token space is prone to collisions, in which semantically distinct items are assigned identical or overly similar SID compositions, resulting in semantic entanglement. (2) Collision-signal heterogeneity: collisions are not uniformly harmful. Some reflect genuine conflicts between semantically unrelated items, while others stem from benign redundancy or systematic data effects. To address these challenges, we propose Qualification-Aware Semantic ID Learning (QuaSID), an end-to-end framework that learns collision-qualified SIDs by selectively repelling qualified conflict pairs and scaling the repulsion strength by collision severity. QuaSID consists of two mechanisms: Hamming-guided Margin Repulsion, which translates low-Hamming SID overlaps into explicit, severity-scaled geometric constraints on the encoder space; and Conflict-Aware Valid Pair Masking, which masks protocol-induced benign overlaps to denoise repulsion supervision. In addition, QuaSID incorporates a dual-tower contrastive objective to inject collaborative signals into tokenization. Experiments on public benchmarks and industrial data validate QuaSID. On public datasets, QuaSID consistently outperforms strong baselines, improving top-K ranking quality by 5.9% over the best baseline while increasing SID composition diversity. In an online A/B test on Kuaishou e-commerce with a 5% traffic split, QuaSID increases ranking GMV-S2 by 2.38% and improves completed orders on cold-start retrieval by up to 6.42%. Finally, we show that the proposed repulsion loss is plug-and-play and enhances a range of SID learning frameworks across datasets.
Implicit Strategic Optimization: Rethinking Long-Horizon Decision-Making in Adversarial Poker Environments
Feb 08, 2026Training large language model (LLM) agents for adversarial games is often driven by episodic objectives such as win rate. In long-horizon settings, however, payoffs are shaped by latent strategic externalities that evolve over time, so myopic optimization and variation-based regret analyses can become vacuous even when the dynamics are predictable. To solve this problem, we introduce Implicit Strategic Optimization (ISO), a prediction-aware framework in which each agent forecasts the current strategic context and uses it to update its policy online. ISO combines a Strategic Reward Model (SRM) that estimates the long-run strategic value of actions with iso-grpo, a context-conditioned optimistic learning rule. We prove sublinear contextual regret and equilibrium convergence guarantees whose dominant terms scale with the number of context mispredictions; when prediction errors are bounded, our bounds recover the static-game rates obtained when strategic externalities are known. Experiments in 6-player No-Limit Texas Hold'em and competitive Pokemon show consistent improvements in long-term return over strong LLM and RL baselines, and graceful degradation under controlled prediction noise.
OneMall: One Architecture, More Scenarios -- End-to-End Generative Recommender Family at Kuaishou E-Commerce
Feb 02, 2026In the wave of generative recommendation, we present OneMall, an end-to-end generative recommendation framework tailored for e-commerce services at Kuaishou. Our OneMall systematically unifies the e-commerce's multiple item distribution scenarios, such as Product-card, short-video and live-streaming. Specifically, it comprises three key components, aligning the entire model training pipeline to the LLM's pre-training/post-training: (1) E-commerce Semantic Tokenizer: we provide a tokenizer solution that captures both real-world semantics and business-specific item relations across different scenarios; (2) Transformer-based Architecture: we largely utilize Transformer as our model backbone, e.g., employing Query-Former for long sequence compression, Cross-Attention for multi-behavior sequence fusion, and Sparse MoE for scalable auto-regressive generation; (3) Reinforcement Learning Pipeline: we further connect retrieval and ranking models via RL, enabling the ranking model to serve as a reward signal for end-to-end policy retrieval model optimization. Extensive experiments demonstrate that OneMall achieves consistent improvements across all e-commerce scenarios: +13.01\% GMV in product-card, +15.32\% Orders in Short-Video, and +2.78\% Orders in Live-Streaming. OneMall has been deployed, serving over 400 million daily active users at Kuaishou.
OneMall: One Model, More Scenarios -- End-to-End Generative Recommender Family at Kuaishou E-Commerce
Jan 29, 2026In the wave of generative recommendation, we present OneMall, an end-to-end generative recommendation framework tailored for e-commerce services at Kuaishou. Our OneMall systematically unifies the e-commerce's multiple item distribution scenarios, such as Product-card, short-video and live-streaming. Specifically, it comprises three key components, aligning the entire model training pipeline to the LLM's pre-training/post-training: (1) E-commerce Semantic Tokenizer: we provide a tokenizer solution that captures both real-world semantics and business-specific item relations across different scenarios; (2) Transformer-based Architecture: we largely utilize Transformer as our model backbone, e.g., employing Query-Former for long sequence compression, Cross-Attention for multi-behavior sequence fusion, and Sparse MoE for scalable auto-regressive generation; (3) Reinforcement Learning Pipeline: we further connect retrieval and ranking models via RL, enabling the ranking model to serve as a reward signal for end-to-end policy retrieval model optimization. Extensive experiments demonstrate that OneMall achieves consistent improvements across all e-commerce scenarios: +13.01\% GMV in product-card, +15.32\% Orders in Short-Video, and +2.78\% Orders in Live-Streaming. OneMall has been deployed, serving over 400 million daily active users at Kuaishou.
Designing faster mixed integer linear programming algorithm via learning the optimal path
Jan 22, 2026Designing faster algorithms for solving Mixed-Integer Linear Programming (MILP) problems is highly desired across numerous practical domains, as a vast array of complex real-world challenges can be effectively modeled as MILP formulations. Solving these problems typically employs the branch-and-bound algorithm, the core of which can be conceived as searching for a path of nodes (or sub-problems) that contains the optimal solution to the original MILP problem. Traditional approaches to finding this path rely heavily on hand-crafted, intuition-based heuristic strategies, which often suffer from unstable and unpredictable performance across different MILP problem instances. To address this limitation, we introduce DeepBound, a deep learning-based node selection algorithm that automates the learning of such human intuition from data. The core of DeepBound lies in learning to prioritize nodes containing the optimal solution, thereby improving solving efficiency. DeepBound introduces a multi-level feature fusion network to capture the node representations. To tackle the inherent node imbalance in branch-and-bound trees, DeepBound employs a pairwise training paradigm that enhances the model's ability to discriminate between nodes. Extensive experiments on three NP-hard MILP benchmarks demonstrate that DeepBound achieves superior solving efficiency over conventional heuristic rules and existing learning-based approaches, obtaining optimal feasible solutions with significantly reduced computation time. Moreover, DeepBound demonstrates strong generalization capability on large and complex instances. The analysis of its learned features reveals that the method can automatically discover more flexible and robust feature selection, which may effectively improve and potentially replace human-designed heuristic rules.
STCRank: Spatio-temporal Collaborative Ranking for Interactive Recommender System at Kuaishou E-shop
Jan 15, 2026As a popular e-commerce platform, Kuaishou E-shop provides precise personalized product recommendations to tens of millions of users every day. To better respond real-time user feedback, we have deployed an interactive recommender system (IRS) alongside our core homepage recommender system. This IRS is triggered by user click on homepage, and generates a series of highly relevant recommendations based on the clicked item to meet focused browsing demands. Different from traditional e-commerce RecSys, the full-screen UI and immersive swiping down functionality present two distinct challenges for regular ranking system. First, there exists explicit interference (overlap or conflicts) between ranking objectives, i.e., conversion, view and swipe down. This is because there are intrinsic behavioral co-occurrences under the premise of immersive browsing and swiping down functionality. Second, the ranking system is prone to temporal greedy traps in sequential recommendation slot transitions, which is caused by full-screen UI design. To alleviate these challenges, we propose a novel Spatio-temporal collaborative ranking (STCRank) framework to achieve collaboration between multi-objectives within one slot (spatial) and between multiple sequential recommondation slots. In multi-objective collaboration (MOC) module, we push Pareto frontier by mitigating the objective overlaps and conflicts. In multi-slot collaboration (MSC) module, we achieve global optima on overall sequential slots by dual-stage look-ahead ranking mechanism. Extensive experiments demonstrate our proposed method brings about purchase and DAU co-growth. The proposed system has been already deployed at Kuaishou E-shop since 2025.6.
HarmonRank: Ranking-aligned Multi-objective Ensemble for Live-streaming E-commerce Recommendation
Jan 08, 2026Recommendation for live-streaming e-commerce is gaining increasing attention due to the explosive growth of the live streaming economy. Different from traditional e-commerce, live-streaming e-commerce shifts the focus from products to streamers, which requires ranking mechanism to balance both purchases and user-streamer interactions for long-term ecology. To trade off multiple objectives, a popular solution is to build an ensemble model to integrate multi-objective scores into a unified score. The ensemble model is usually supervised by multiple independent binary classification losses of all objectives. However, this paradigm suffers from two inherent limitations. First, the optimization direction of the binary classification task is misaligned with the ranking task (evaluated by AUC). Second, this paradigm overlooks the alignment between objectives, e.g., comment and buy behaviors are partially dependent which can be revealed in labels correlations. The model can achieve better trade-offs if it learns the aligned parts of ranking abilities among different objectives. To mitigate these limitations, we propose a novel multi-objective ensemble framework HarmonRank to fulfill both alignment to the ranking task and alignment among objectives. For alignment to ranking, we formulate ranking metric AUC as a rank-sum problem and utilize differentiable ranking techniques for ranking-oriented optimization. For inter-objective alignment, we change the original one-step ensemble paradigm to a two-step relation-aware ensemble scheme. Extensive offline experiments results on two industrial datasets and online experiments demonstrate that our approach significantly outperforms existing state-of-the-art methods. The proposed method has been fully deployed in Kuaishou's live-streaming e-commerce recommendation platform with 400 million DAUs, contributing over 2% purchase gain.
ChorusCVR: Chorus Supervision for Entire Space Post-Click Conversion Rate Modeling
Feb 12, 2025



Post-click conversion rate (CVR) estimation is a vital task in many recommender systems of revenue businesses, e.g., e-commerce and advertising. In a perspective of sample, a typical CVR positive sample usually goes through a funnel of exposure to click to conversion. For lack of post-event labels for un-clicked samples, CVR learning task commonly only utilizes clicked samples, rather than all exposed samples as for click-through rate (CTR) learning task. However, during online inference, CVR and CTR are estimated on the same assumed exposure space, which leads to a inconsistency of sample space between training and inference, i.e., sample selection bias (SSB). To alleviate SSB, previous wisdom proposes to design novel auxiliary tasks to enable the CVR learning on un-click training samples, such as CTCVR and counterfactual CVR, etc. Although alleviating SSB to some extent, none of them pay attention to the discrimination between ambiguous negative samples (un-clicked) and factual negative samples (clicked but un-converted) during modelling, which makes CVR model lacks robustness. To full this gap, we propose a novel ChorusCVR model to realize debiased CVR learning in entire-space.
CODER: Coupled Diversity-Sensitive Momentum Contrastive Learning for Image-Text Retrieval
Aug 21, 2022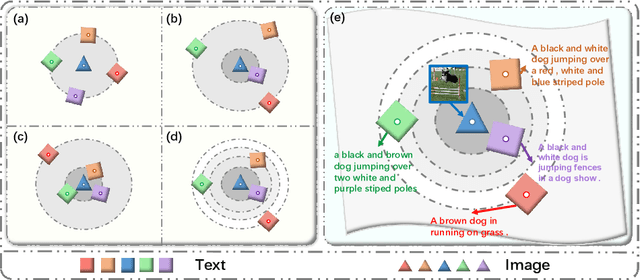
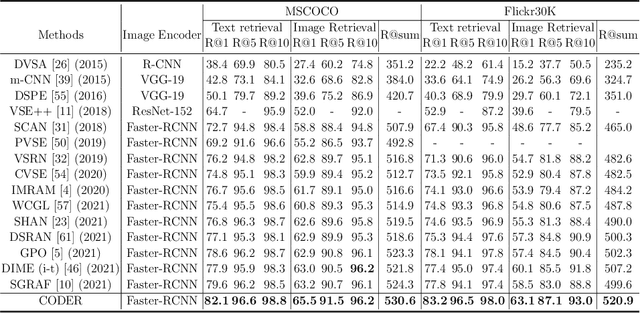
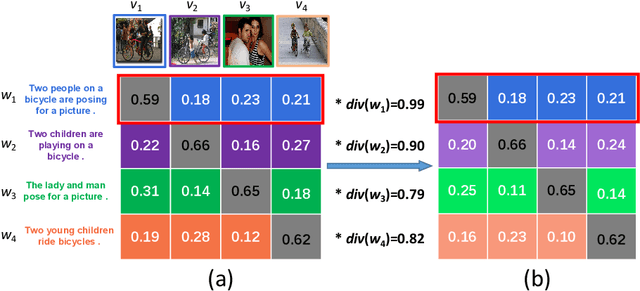
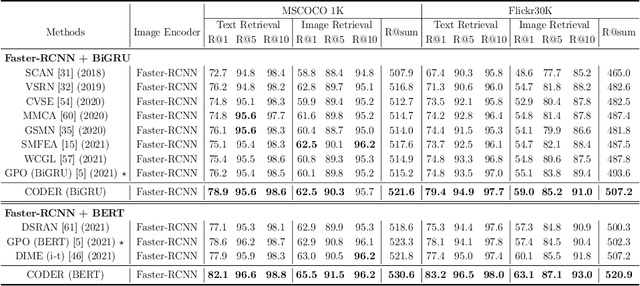
Image-Text Retrieval (ITR) is challenging in bridging visual and lingual modalities. Contrastive learning has been adopted by most prior arts. Except for limited amount of negative image-text pairs, the capability of constrastive learning is restricted by manually weighting negative pairs as well as unawareness of external knowledge. In this paper, we propose our novel Coupled Diversity-Sensitive Momentum Constrastive Learning (CODER) for improving cross-modal representation. Firstly, a novel diversity-sensitive contrastive learning (DCL) architecture is invented. We introduce dynamic dictionaries for both modalities to enlarge the scale of image-text pairs, and diversity-sensitiveness is achieved by adaptive negative pair weighting. Furthermore, two branches are designed in CODER. One learns instance-level embeddings from image/text, and it also generates pseudo online clustering labels for its input image/text based on their embeddings. Meanwhile, the other branch learns to query from commonsense knowledge graph to form concept-level descriptors for both modalities. Afterwards, both branches leverage DCL to align the cross-modal embedding spaces while an extra pseudo clustering label prediction loss is utilized to promote concept-level representation learning for the second branch. Extensive experiments conducted on two popular benchmarks, i.e. MSCOCO and Flicker30K, validate CODER remarkably outperforms the state-of-the-art approaches.