 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOneMall: One Architecture, More Scenarios -- End-to-End Generative Recommender Family at Kuaishou E-Commerce
Feb 02, 2026In the wave of generative recommendation, we present OneMall, an end-to-end generative recommendation framework tailored for e-commerce services at Kuaishou. Our OneMall systematically unifies the e-commerce's multiple item distribution scenarios, such as Product-card, short-video and live-streaming. Specifically, it comprises three key components, aligning the entire model training pipeline to the LLM's pre-training/post-training: (1) E-commerce Semantic Tokenizer: we provide a tokenizer solution that captures both real-world semantics and business-specific item relations across different scenarios; (2) Transformer-based Architecture: we largely utilize Transformer as our model backbone, e.g., employing Query-Former for long sequence compression, Cross-Attention for multi-behavior sequence fusion, and Sparse MoE for scalable auto-regressive generation; (3) Reinforcement Learning Pipeline: we further connect retrieval and ranking models via RL, enabling the ranking model to serve as a reward signal for end-to-end policy retrieval model optimization. Extensive experiments demonstrate that OneMall achieves consistent improvements across all e-commerce scenarios: +13.01\% GMV in product-card, +15.32\% Orders in Short-Video, and +2.78\% Orders in Live-Streaming. OneMall has been deployed, serving over 400 million daily active users at Kuaishou.
OneMall: One Model, More Scenarios -- End-to-End Generative Recommender Family at Kuaishou E-Commerce
Jan 29, 2026In the wave of generative recommendation, we present OneMall, an end-to-end generative recommendation framework tailored for e-commerce services at Kuaishou. Our OneMall systematically unifies the e-commerce's multiple item distribution scenarios, such as Product-card, short-video and live-streaming. Specifically, it comprises three key components, aligning the entire model training pipeline to the LLM's pre-training/post-training: (1) E-commerce Semantic Tokenizer: we provide a tokenizer solution that captures both real-world semantics and business-specific item relations across different scenarios; (2) Transformer-based Architecture: we largely utilize Transformer as our model backbone, e.g., employing Query-Former for long sequence compression, Cross-Attention for multi-behavior sequence fusion, and Sparse MoE for scalable auto-regressive generation; (3) Reinforcement Learning Pipeline: we further connect retrieval and ranking models via RL, enabling the ranking model to serve as a reward signal for end-to-end policy retrieval model optimization. Extensive experiments demonstrate that OneMall achieves consistent improvements across all e-commerce scenarios: +13.01\% GMV in product-card, +15.32\% Orders in Short-Video, and +2.78\% Orders in Live-Streaming. OneMall has been deployed, serving over 400 million daily active users at Kuaishou.
ChorusCVR: Chorus Supervision for Entire Space Post-Click Conversion Rate Modeling
Feb 12, 2025



Post-click conversion rate (CVR) estimation is a vital task in many recommender systems of revenue businesses, e.g., e-commerce and advertising. In a perspective of sample, a typical CVR positive sample usually goes through a funnel of exposure to click to conversion. For lack of post-event labels for un-clicked samples, CVR learning task commonly only utilizes clicked samples, rather than all exposed samples as for click-through rate (CTR) learning task. However, during online inference, CVR and CTR are estimated on the same assumed exposure space, which leads to a inconsistency of sample space between training and inference, i.e., sample selection bias (SSB). To alleviate SSB, previous wisdom proposes to design novel auxiliary tasks to enable the CVR learning on un-click training samples, such as CTCVR and counterfactual CVR, etc. Although alleviating SSB to some extent, none of them pay attention to the discrimination between ambiguous negative samples (un-clicked) and factual negative samples (clicked but un-converted) during modelling, which makes CVR model lacks robustness. To full this gap, we propose a novel ChorusCVR model to realize debiased CVR learning in entire-space.
QARM: Quantitative Alignment Multi-Modal Recommendation at Kuaishou
Nov 18, 2024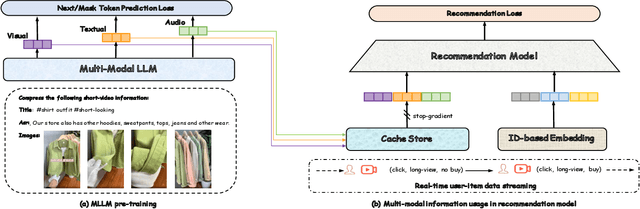
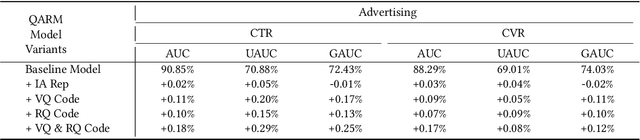
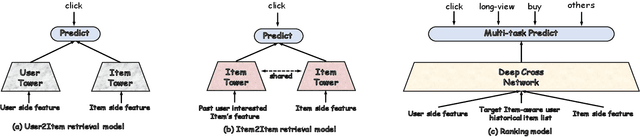
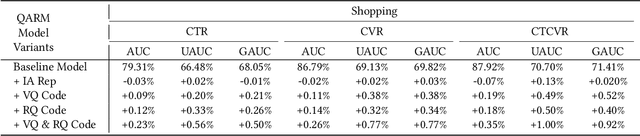
In recent years, with the significant evolution of multi-modal large models, many recommender researchers realized the potential of multi-modal information for user interest modeling. In industry, a wide-used modeling architecture is a cascading paradigm: (1) first pre-training a multi-modal model to provide omnipotent representations for downstream services; (2) The downstream recommendation model takes the multi-modal representation as additional input to fit real user-item behaviours. Although such paradigm achieves remarkable improvements, however, there still exist two problems that limit model performance: (1) Representation Unmatching: The pre-trained multi-modal model is always supervised by the classic NLP/CV tasks, while the recommendation models are supervised by real user-item interaction. As a result, the two fundamentally different tasks' goals were relatively separate, and there was a lack of consistent objective on their representations; (2) Representation Unlearning: The generated multi-modal representations are always stored in cache store and serve as extra fixed input of recommendation model, thus could not be updated by recommendation model gradient, further unfriendly for downstream training. Inspired by the two difficulties challenges in downstream tasks usage, we introduce a quantitative multi-modal framework to customize the specialized and trainable multi-modal information for different downstream models.
Magnetic-Assisted Initialization for Infrastructure-free Mobile Robot Localization
Nov 21, 2019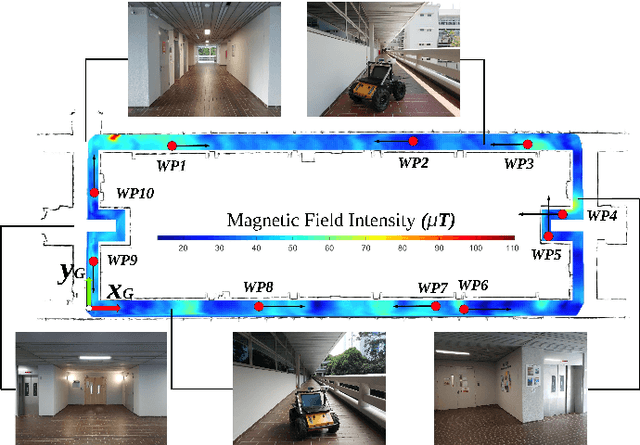
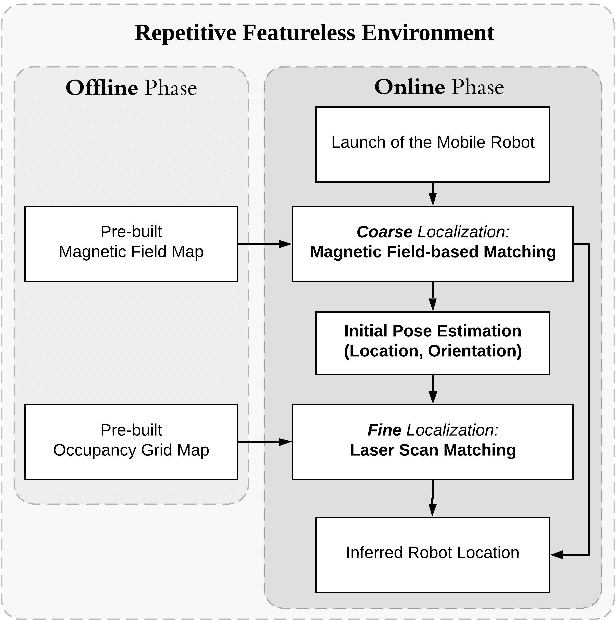

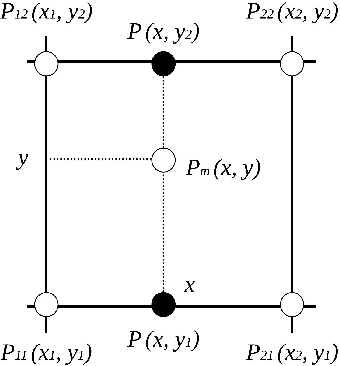
Most of the existing mobile robot localization solutions are either heavily dependent on pre-installed infrastructures or having difficulty working in highly repetitive environments which do not have sufficient unique features. To address this problem, we propose a magnetic-assisted initialization approach that enhances the performance of infrastructure-free mobile robot localization in repetitive featureless environments. The proposed system adopts a coarse-to-fine structure, which mainly consists of two parts: magnetic field-based matching and laser scan matching. Firstly, the interpolated magnetic field map is built and the initial pose of the mobile robot is partly determined by the k-Nearest Neighbors (k-NN) algorithm. Next, with the fusion of prior initial pose information, the robot is localized by laser scan matching more accurately and efficiently. In our experiment, the mobile robot was successfully localized in a featureless rectangular corridor with a success rate of 88% and an average correct localization time of 6.6 seconds.