 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
MISS: Multi-Modal Tree Indexing and Searching with Lifelong Sequential Behavior for Retrieval Recommendation
Aug 20, 2025



Large-scale industrial recommendation systems typically employ a two-stage paradigm of retrieval and ranking to handle huge amounts of information. Recent research focuses on improving the performance of retrieval model. A promising way is to introduce extensive information about users and items. On one hand, lifelong sequential behavior is valuable. Existing lifelong behavior modeling methods in ranking stage focus on the interaction of lifelong behavior and candidate items from retrieval stage. In retrieval stage, it is difficult to utilize lifelong behavior because of a large corpus of candidate items. On the other hand, existing retrieval methods mostly relay on interaction information, potentially disregarding valuable multi-modal information. To solve these problems, we represent the pioneering exploration of leveraging multi-modal information and lifelong sequence model within the advanced tree-based retrieval model. We propose Multi-modal Indexing and Searching with lifelong Sequence (MISS), which contains a multi-modal index tree and a multi-modal lifelong sequence modeling module. Specifically, for better index structure, we propose multi-modal index tree, which is built using the multi-modal embedding to precisely represent item similarity. To precisely capture diverse user interests in user lifelong sequence, we propose collaborative general search unit (Co-GSU) and multi-modal general search unit (MM-GSU) for multi-perspective interests searching.
Kwai Keye-VL Technical Report
Jul 02, 2025While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce \textbf{Kwai Keye-VL}, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode ``cold-start'' data mixture, which includes ``thinking'', ``non-thinking'', ``auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the \textbf{KC-MMBench}, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
OneRec Technical Report
Jun 16, 2025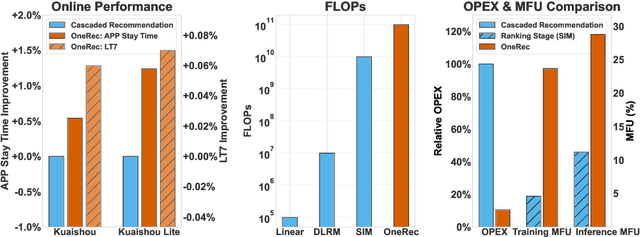

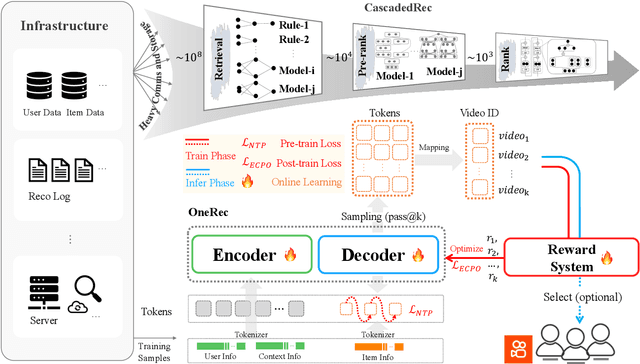

Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment
Feb 26, 2025



Recently, generative retrieval-based recommendation systems have emerged as a promising paradigm. However, most modern recommender systems adopt a retrieve-and-rank strategy, where the generative model functions only as a selector during the retrieval stage. In this paper, we propose OneRec, which replaces the cascaded learning framework with a unified generative model. To the best of our knowledge, this is the first end-to-end generative model that significantly surpasses current complex and well-designed recommender systems in real-world scenarios. Specifically, OneRec includes: 1) an encoder-decoder structure, which encodes the user's historical behavior sequences and gradually decodes the videos that the user may be interested in. We adopt sparse Mixture-of-Experts (MoE) to scale model capacity without proportionally increasing computational FLOPs. 2) a session-wise generation approach. In contrast to traditional next-item prediction, we propose a session-wise generation, which is more elegant and contextually coherent than point-by-point generation that relies on hand-crafted rules to properly combine the generated results. 3) an Iterative Preference Alignment module combined with Direct Preference Optimization (DPO) to enhance the quality of the generated results. Unlike DPO in NLP, a recommendation system typically has only one opportunity to display results for each user's browsing request, making it impossible to obtain positive and negative samples simultaneously. To address this limitation, We design a reward model to simulate user generation and customize the sampling strategy. Extensive experiments have demonstrated that a limited number of DPO samples can align user interest preferences and significantly improve the quality of generated results. We deployed OneRec in the main scene of Kuaishou, achieving a 1.6\% increase in watch-time, which is a substantial improvement.
QARM: Quantitative Alignment Multi-Modal Recommendation at Kuaishou
Nov 18, 2024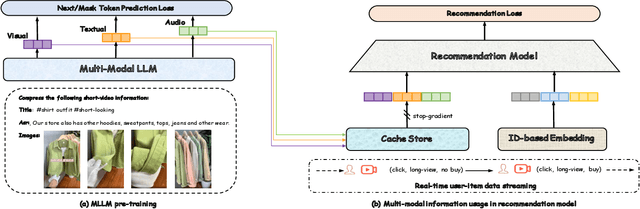
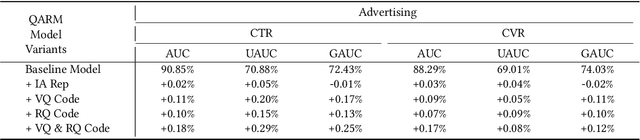
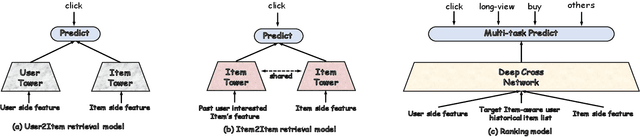
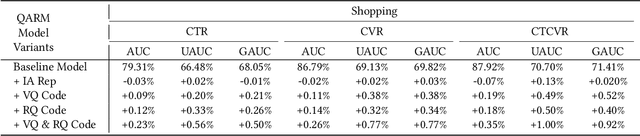
In recent years, with the significant evolution of multi-modal large models, many recommender researchers realized the potential of multi-modal information for user interest modeling. In industry, a wide-used modeling architecture is a cascading paradigm: (1) first pre-training a multi-modal model to provide omnipotent representations for downstream services; (2) The downstream recommendation model takes the multi-modal representation as additional input to fit real user-item behaviours. Although such paradigm achieves remarkable improvements, however, there still exist two problems that limit model performance: (1) Representation Unmatching: The pre-trained multi-modal model is always supervised by the classic NLP/CV tasks, while the recommendation models are supervised by real user-item interaction. As a result, the two fundamentally different tasks' goals were relatively separate, and there was a lack of consistent objective on their representations; (2) Representation Unlearning: The generated multi-modal representations are always stored in cache store and serve as extra fixed input of recommendation model, thus could not be updated by recommendation model gradient, further unfriendly for downstream training. Inspired by the two difficulties challenges in downstream tasks usage, we introduce a quantitative multi-modal framework to customize the specialized and trainable multi-modal information for different downstream models.