 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Token-Trained Models into Byte-Level Models
Feb 01, 2026Byte Language Models (BLMs) have emerged as a promising direction for scaling language models beyond tokenization. However, existing BLMs typically require training from scratch on trillions of bytes, making them prohibitively expensive. In this paper, we propose an efficient distillation recipe that converts existing token-trained LLMs into BLMs while retaining comparable capabilities. Our recipe follows a two-stage curriculum: (1) Progressive Knowledge Distillation, which aligns byte-level representations with the embeddings of the token-trained teacher model; and (2) Byte-Level Supervised Fine-Tuning, which enables end-to-end generation entirely in the byte space. We validate our approach across multiple model families, including Llama, Qwen, and OLMo, and demonstrate that the distilled BLMs retain most of the teacher models' performance using only approximately 125B bytes.
Feeding LLM Annotations to BERT Classifiers at Your Own Risk
Apr 21, 2025Using LLM-generated labels to fine-tune smaller encoder-only models for text classification has gained popularity in various settings. While this approach may be justified in simple and low-stakes applications, we conduct empirical analysis to demonstrate how the perennial curse of training on synthetic data manifests itself in this specific setup. Compared to models trained on gold labels, we observe not only the expected performance degradation in accuracy and F1 score, but also increased instability across training runs and premature performance plateaus. These findings cast doubts on the reliability of such approaches in real-world applications. We contextualize the observed phenomena through the lens of error propagation and offer several practical mitigation strategies, including entropy-based filtering and ensemble techniques. Although these heuristics offer partial relief, they do not fully resolve the inherent risks of propagating non-random errors from LLM annotations to smaller classifiers, underscoring the need for caution when applying this workflow in high-stakes text classification tasks.
Learning to Harmonize Cross-vendor X-ray Images by Non-linear Image Dynamics Correction
Apr 14, 2025In this paper, we explore how conventional image enhancement can improve model robustness in medical image analysis. By applying commonly used normalization methods to images from various vendors and studying their influence on model generalization in transfer learning, we show that the nonlinear characteristics of domain-specific image dynamics cannot be addressed by simple linear transforms. To tackle this issue, we reformulate the image harmonization task as an exposure correction problem and propose a method termed Global Deep Curve Estimation (GDCE) to reduce domain-specific exposure mismatch. GDCE performs enhancement via a pre-defined polynomial function and is trained with the help of a ``domain discriminator'', aiming to improve model transparency in downstream tasks compared to existing black-box methods.
ChorusCVR: Chorus Supervision for Entire Space Post-Click Conversion Rate Modeling
Feb 12, 2025



Post-click conversion rate (CVR) estimation is a vital task in many recommender systems of revenue businesses, e.g., e-commerce and advertising. In a perspective of sample, a typical CVR positive sample usually goes through a funnel of exposure to click to conversion. For lack of post-event labels for un-clicked samples, CVR learning task commonly only utilizes clicked samples, rather than all exposed samples as for click-through rate (CTR) learning task. However, during online inference, CVR and CTR are estimated on the same assumed exposure space, which leads to a inconsistency of sample space between training and inference, i.e., sample selection bias (SSB). To alleviate SSB, previous wisdom proposes to design novel auxiliary tasks to enable the CVR learning on un-click training samples, such as CTCVR and counterfactual CVR, etc. Although alleviating SSB to some extent, none of them pay attention to the discrimination between ambiguous negative samples (un-clicked) and factual negative samples (clicked but un-converted) during modelling, which makes CVR model lacks robustness. To full this gap, we propose a novel ChorusCVR model to realize debiased CVR learning in entire-space.
LiveForesighter: Generating Future Information for Live-Streaming Recommendations at Kuaishou
Feb 10, 2025Live-streaming, as a new-generation media to connect users and authors, has attracted a lot of attention and experienced rapid growth in recent years. Compared with the content-static short-video recommendation, the live-streaming recommendation faces more challenges in giving our users a satisfactory experience: (1) Live-streaming content is dynamically ever-changing along time. (2) valuable behaviors (e.g., send digital-gift, buy products) always require users to watch for a long-time (>10 min). Combining the two attributes, here raising a challenging question for live-streaming recommendation: How to discover the live-streamings that the content user is interested in at the current moment, and further a period in the future?
On dataset transferability in medical image classification
Dec 28, 2024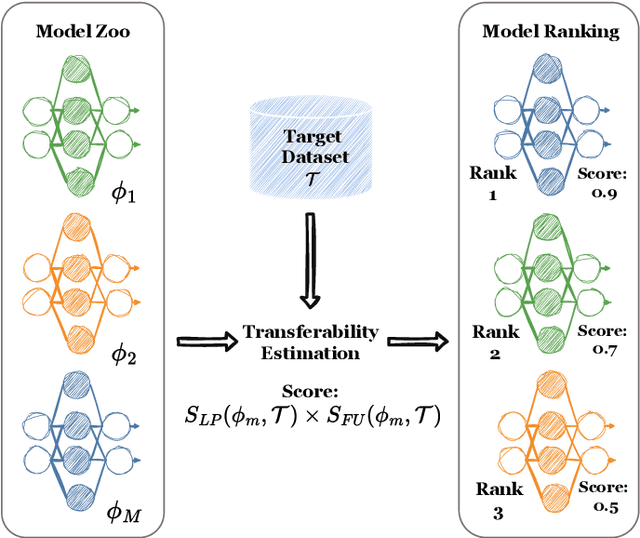
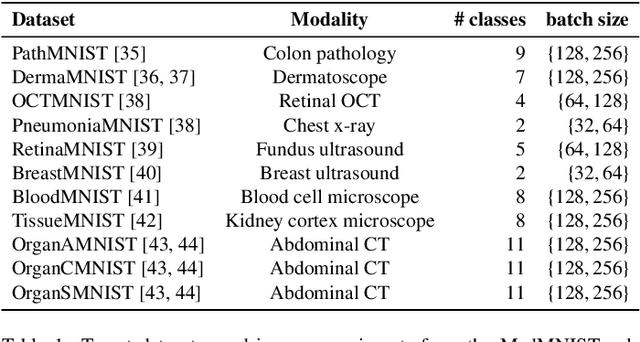
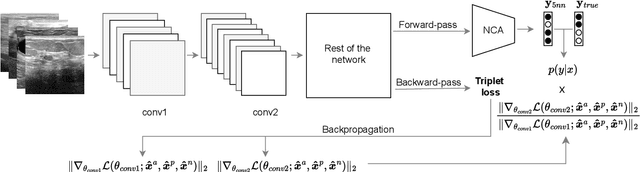
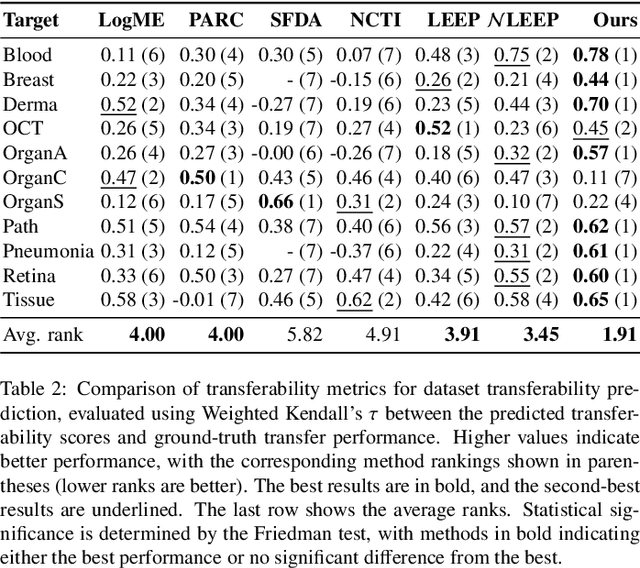
Current transferability estimation methods designed for natural image datasets are often suboptimal in medical image classification. These methods primarily focus on estimating the suitability of pre-trained source model features for a target dataset, which can lead to unrealistic predictions, such as suggesting that the target dataset is the best source for itself. To address this, we propose a novel transferability metric that combines feature quality with gradients to evaluate both the suitability and adaptability of source model features for target tasks. We evaluate our approach in two new scenarios: source dataset transferability for medical image classification and cross-domain transferability. Our results show that our method outperforms existing transferability metrics in both settings. We also provide insight into the factors influencing transfer performance in medical image classification, as well as the dynamics of cross-domain transfer from natural to medical images. Additionally, we provide ground-truth transfer performance benchmarking results to encourage further research into transferability estimation for medical image classification. Our code and experiments are available at https://github.com/DovileDo/transferability-in-medical-imaging.
Exploring connections of spectral analysis and transfer learning in medical imaging
Jul 16, 2024



In this paper, we use spectral analysis to investigate transfer learning and study model sensitivity to frequency shortcuts in medical imaging. By analyzing the power spectrum density of both pre-trained and fine-tuned model gradients, as well as artificially generated frequency shortcuts, we observe notable differences in learning priorities between models pre-trained on natural vs medical images, which generally persist during fine-tuning. We find that when a model's learning priority aligns with the power spectrum density of an artifact, it results in overfitting to that artifact. Based on these observations, we show that source data editing can alter the model's resistance to shortcut learning.
Source Matters: Source Dataset Impact on Model Robustness in Medical Imaging
Mar 07, 2024Transfer learning has become an essential part of medical imaging classification algorithms, often leveraging ImageNet weights. However, the domain shift from natural to medical images has prompted alternatives such as RadImageNet, often demonstrating comparable classification performance. However, it remains unclear whether the performance gains from transfer learning stem from improved generalization or shortcut learning. To address this, we investigate potential confounders -- whether synthetic or sampled from the data -- across two publicly available chest X-ray and CT datasets. We show that ImageNet and RadImageNet achieve comparable classification performance, yet ImageNet is much more prone to overfitting to confounders. We recommend that researchers using ImageNet-pretrained models reexamine their model robustness by conducting similar experiments. Our code and experiments are available at https://github.com/DovileDo/source-matters.
Multi-frame-based Cross-domain Image Denoising for Low-dose Computed Tomography
Apr 27, 2023Computed tomography (CT) has been used worldwide for decades as one of the most important non-invasive tests in assisting diagnosis. However, the ionizing nature of X-ray exposure raises concerns about potential health risks such as cancer. The desire for lower radiation dose has driven researchers to improve the reconstruction quality, especially by removing noise and artifacts. Although previous studies on low-dose computed tomography (LDCT) denoising have demonstrated the potential of learning-based methods, most of them were developed on the simulated data collected using Radon transform. However, the real-world scenario significantly differs from the simulation domain, and the joint optimization of denoising with the modern CT image reconstruction pipeline is still missing. In this paper, for the commercially available third-generation multi-slice spiral CT scanners, we propose a two-stage method that better exploits the complete reconstruction pipeline for LDCT denoising across different domains. Our method makes good use of the high redundancy of both the multi-slice projections and the volumetric reconstructions while avoiding the collapse of information in conventional cascaded frameworks. The dedicated design also provides a clearer interpretation of the workflow. Through extensive evaluations, we demonstrate its superior performance against state-of-the-art methods.
Scale up with Order: Finding Good Data Permutations for Distributed Training
Feb 02, 2023



Gradient Balancing (GraB) is a recently proposed technique that finds provably better data permutations when training models with multiple epochs over a finite dataset. It converges at a faster rate than the widely adopted Random Reshuffling, by minimizing the discrepancy of the gradients on adjacently selected examples. However, GraB only operates under critical assumptions such as small batch sizes and centralized data, leaving open the question of how to order examples at large scale -- i.e. distributed learning with decentralized data. To alleviate the limitation, in this paper we propose D-GraB that involves two novel designs: (1) $\textsf{PairBalance}$ that eliminates the requirement to use stale gradient mean in GraB which critically relies on small learning rates; (2) an ordering protocol that runs $\textsf{PairBalance}$ in a distributed environment with negligible overhead, which benefits from both data ordering and parallelism. We prove D-GraB enjoys linear speed up at rate $\tilde{O}((mnT)^{-2/3})$ on smooth non-convex objectives and $\tilde{O}((mnT)^{-2})$ under PL condition, where $n$ denotes the number of parallel workers, $m$ denotes the number of examples per worker and $T$ denotes the number of epochs. Empirically, we show on various applications including GLUE, CIFAR10 and WikiText-2 that D-GraB outperforms naive parallel GraB and Distributed Random Reshuffling in terms of both training and validation performance.