 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccam's model: Selecting simpler representations for better transferability estimation
Feb 10, 2025Fine-tuning models that have been pre-trained on large datasets has become a cornerstone of modern machine learning workflows. With the widespread availability of online model repositories, such as Hugging Face, it is now easier than ever to fine-tune pre-trained models for specific tasks. This raises a critical question: which pre-trained model is most suitable for a given task? This problem is called transferability estimation. In this work, we introduce two novel and effective metrics for estimating the transferability of pre-trained models. Our approach is grounded in viewing transferability as a measure of how easily a pre-trained model's representations can be trained to separate target classes, providing a unique perspective on transferability estimation. We rigorously evaluate the proposed metrics against state-of-the-art alternatives across diverse problem settings, demonstrating their robustness and practical utility. Additionally, we present theoretical insights that explain our metrics' efficacy and adaptability to various scenarios. We experimentally show that our metrics increase Kendall's Tau by up to 32% compared to the state-of-the-art baselines.
On dataset transferability in medical image classification
Dec 28, 2024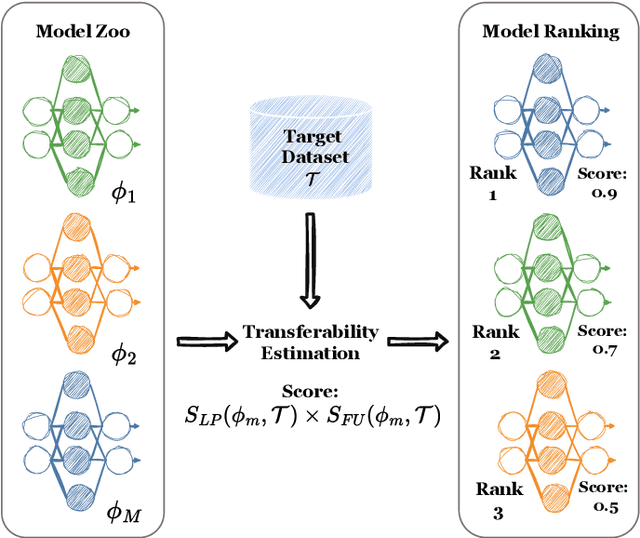
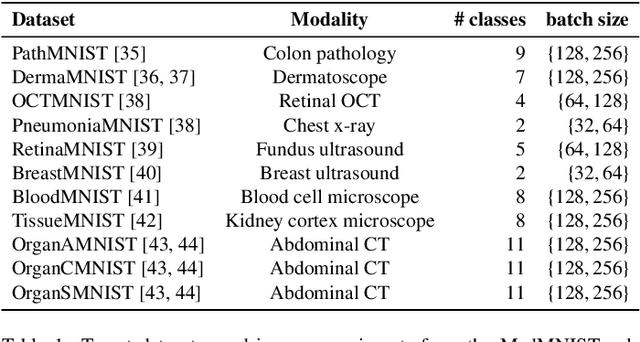
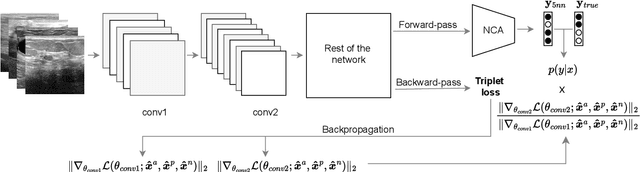
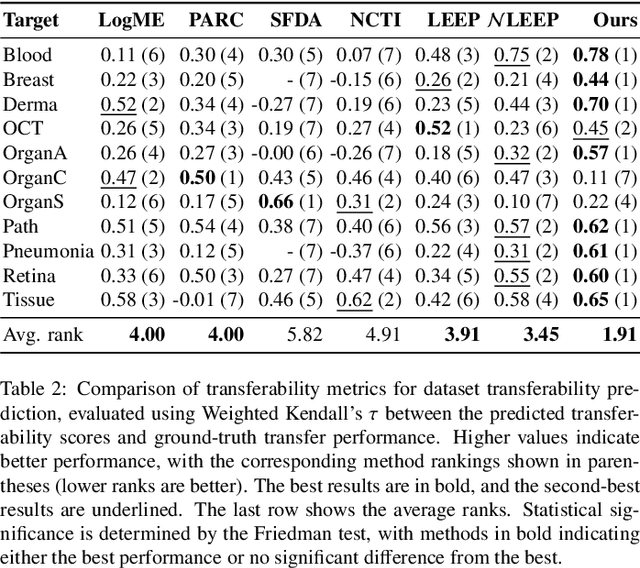
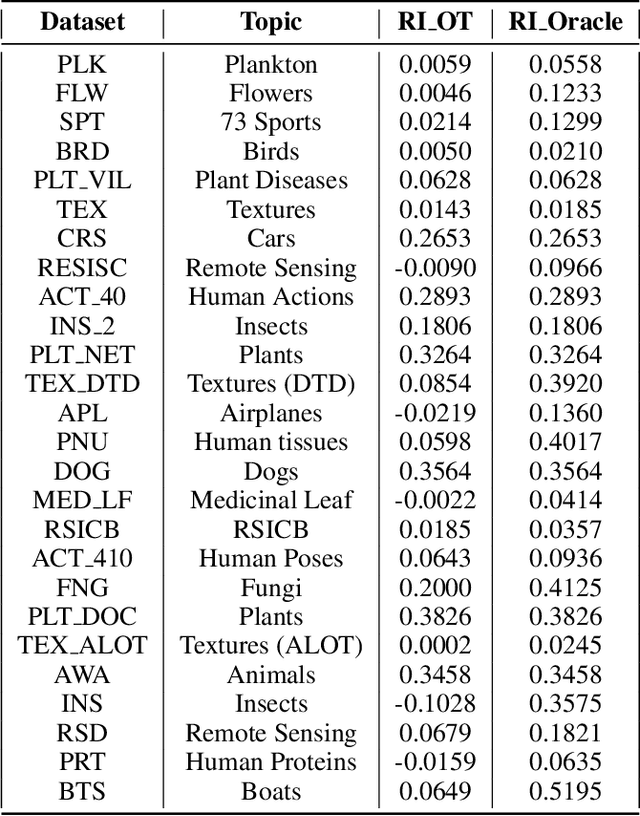
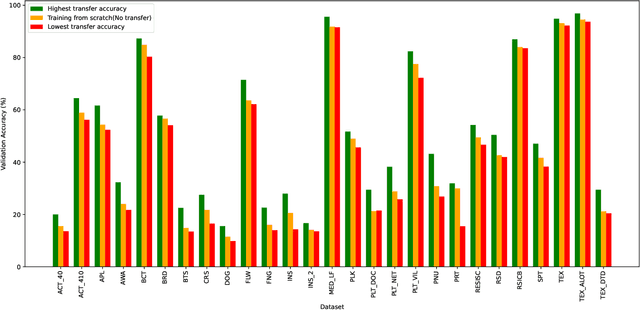
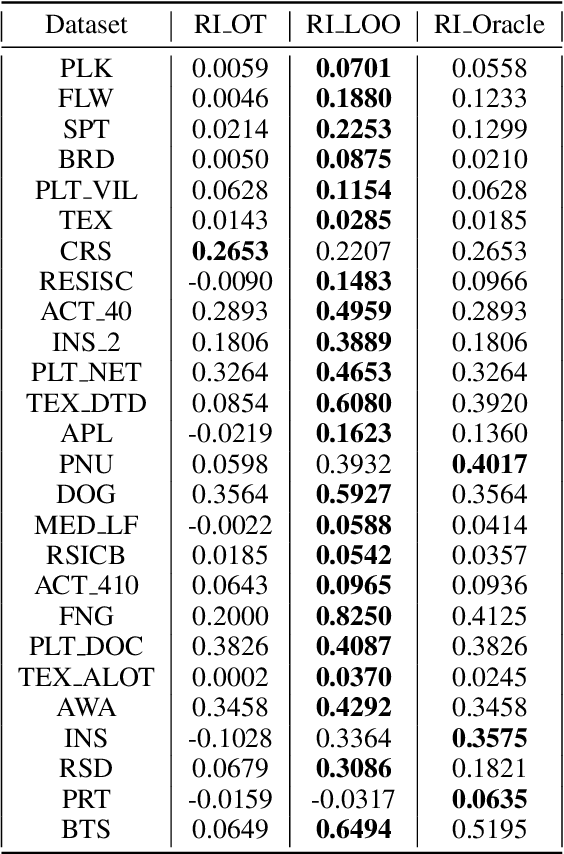
Current transferability estimation methods designed for natural image datasets are often suboptimal in medical image classification. These methods primarily focus on estimating the suitability of pre-trained source model features for a target dataset, which can lead to unrealistic predictions, such as suggesting that the target dataset is the best source for itself. To address this, we propose a novel transferability metric that combines feature quality with gradients to evaluate both the suitability and adaptability of source model features for target tasks. We evaluate our approach in two new scenarios: source dataset transferability for medical image classification and cross-domain transferability. Our results show that our method outperforms existing transferability metrics in both settings. We also provide insight into the factors influencing transfer performance in medical image classification, as well as the dynamics of cross-domain transfer from natural to medical images. Additionally, we provide ground-truth transfer performance benchmarking results to encourage further research into transferability estimation for medical image classification. Our code and experiments are available at https://github.com/DovileDo/transferability-in-medical-imaging.
Robust and Efficient Transfer Learning via Supernet Transfer in Warm-started Neural Architecture Search
Jul 26, 2024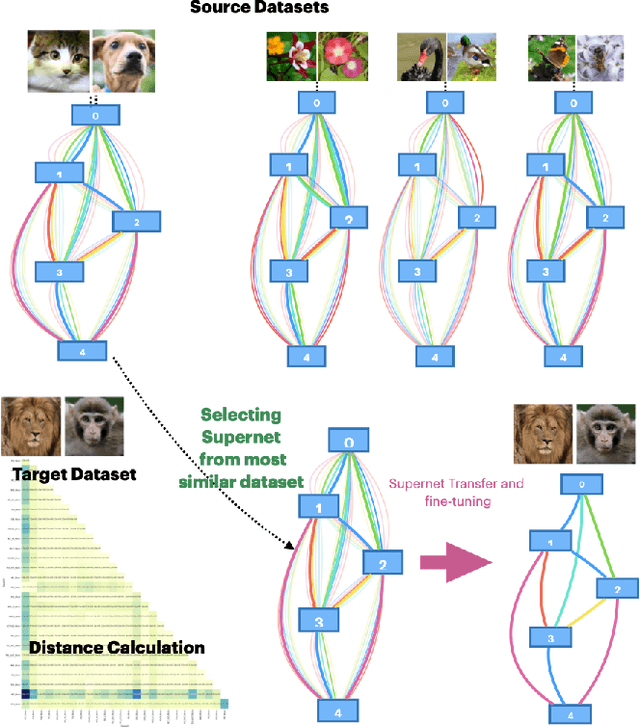
Hand-designing Neural Networks is a tedious process that requires significant expertise. Neural Architecture Search (NAS) frameworks offer a very useful and popular solution that helps to democratize AI. However, these NAS frameworks are often computationally expensive to run, which limits their applicability and accessibility. In this paper, we propose a novel transfer learning approach, capable of effectively transferring pretrained supernets based on Optimal Transport or multi-dataset pretaining. This method can be generally applied to NAS methods based on Differentiable Architecture Search (DARTS). Through extensive experiments across dozens of image classification tasks, we demonstrate that transferring pretrained supernets in this way can not only drastically speed up the supernet training which then finds optimal models (3 to 5 times faster on average), but even yield that outperform those found when running DARTS methods from scratch. We also observe positive transfer to almost all target datasets, making it very robust. Besides drastically improving the applicability of NAS methods, this also opens up new applications for continual learning and related fields.
CLAMS: A System for Zero-Shot Model Selection for Clustering
Jul 15, 2024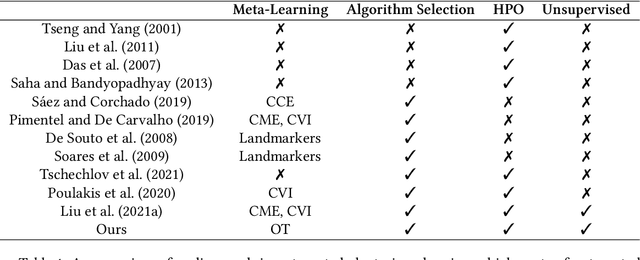

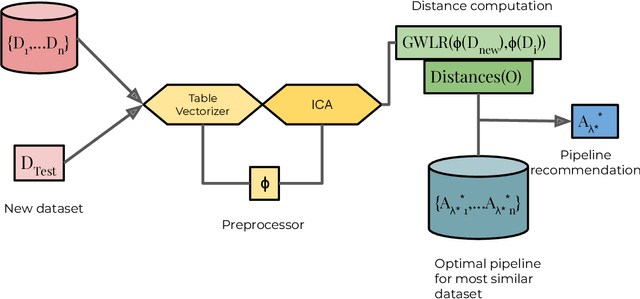
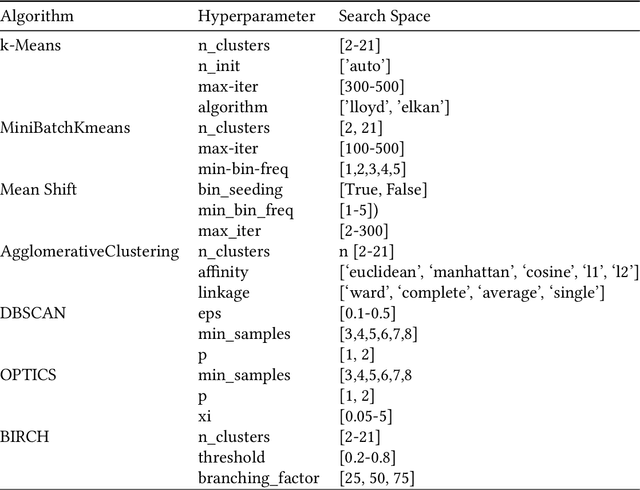
We propose an AutoML system that enables model selection on clustering problems by leveraging optimal transport-based dataset similarity. Our objective is to establish a comprehensive AutoML pipeline for clustering problems and provide recommendations for selecting the most suitable algorithms, thus opening up a new area of AutoML beyond the traditional supervised learning settings. We compare our results against multiple clustering baselines and find that it outperforms all of them, hence demonstrating the utility of similarity-based automated model selection for solving clustering applications.
Meta-Learning for Unsupervised Outlier Detection with Optimal Transport
Nov 01, 2022Automated machine learning has been widely researched and adopted in the field of supervised classification and regression, but progress in unsupervised settings has been limited. We propose a novel approach to automate outlier detection based on meta-learning from previous datasets with outliers. Our premise is that the selection of the optimal outlier detection technique depends on the inherent properties of the data distribution. We leverage optimal transport in particular, to find the dataset with the most similar underlying distribution, and then apply the outlier detection techniques that proved to work best for that data distribution. We evaluate the robustness of our approach and find that it outperforms the state of the art methods in unsupervised outlier detection. This approach can also be easily generalized to automate other unsupervised settings.
Automated Imbalanced Learning
Nov 01, 2022Automated Machine Learning has grown very successful in automating the time-consuming, iterative tasks of machine learning model development. However, current methods struggle when the data is imbalanced. Since many real-world datasets are naturally imbalanced, and improper handling of this issue can lead to quite useless models, this issue should be handled carefully. This paper first introduces a new benchmark to study how different AutoML methods are affected by label imbalance. Second, we propose strategies to better deal with imbalance and integrate them into an existing AutoML framework. Finally, we present a systematic study which evaluates the impact of these strategies and find that their inclusion in AutoML systems significantly increases their robustness against label imbalance.
Online AutoML: An adaptive AutoML framework for online learning
Jan 24, 2022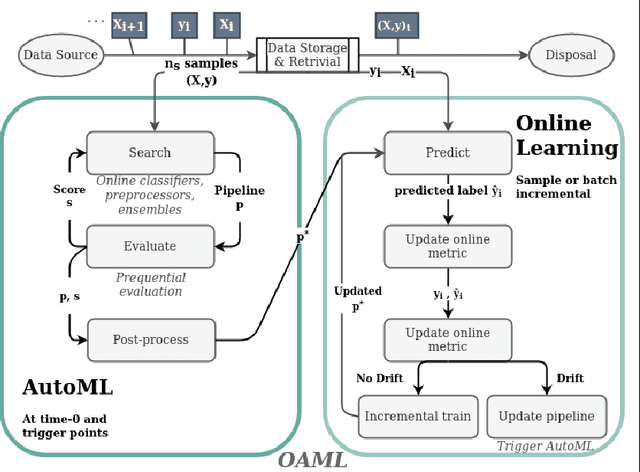
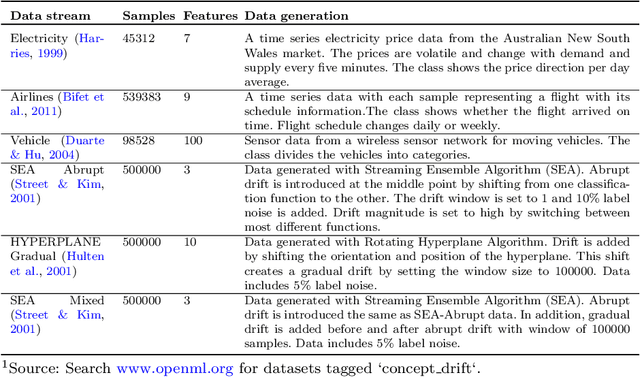
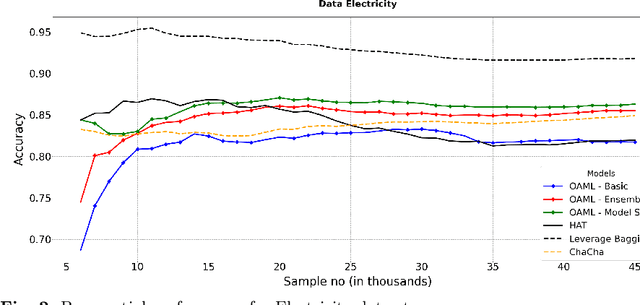
Automated Machine Learning (AutoML) has been used successfully in settings where the learning task is assumed to be static. In many real-world scenarios, however, the data distribution will evolve over time, and it is yet to be shown whether AutoML techniques can effectively design online pipelines in dynamic environments. This study aims to automate pipeline design for online learning while continuously adapting to data drift. For this purpose, we design an adaptive Online Automated Machine Learning (OAML) system, searching the complete pipeline configuration space of online learners, including preprocessing algorithms and ensembling techniques. This system combines the inherent adaptation capabilities of online learners with the fast automated pipeline (re)optimization capabilities of AutoML. Focusing on optimization techniques that can adapt to evolving objectives, we evaluate asynchronous genetic programming and asynchronous successive halving to optimize these pipelines continually. We experiment on real and artificial data streams with varying types of concept drift to test the performance and adaptation capabilities of the proposed system. The results confirm the utility of OAML over popular online learning algorithms and underscore the benefits of continuous pipeline redesign in the presence of data drift.
A Study of the Learning Progress in Neural Architecture Search Techniques
Jun 18, 2019
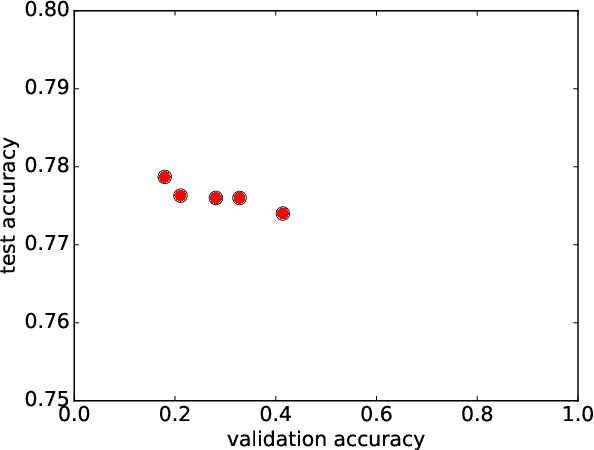
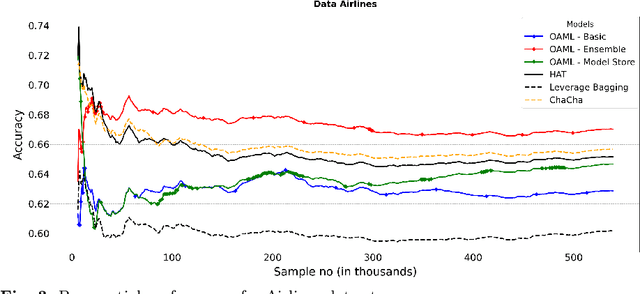
In neural architecture search, the structure of the neural network to best model a given dataset is determined by an automated search process. Efficient Neural Architecture Search (ENAS), proposed by Pham et al. (2018), has recently received considerable attention due to its ability to find excellent architectures within a comparably short search time. In this work, which is motivated by the quest to further improve the learning speed of architecture search, we evaluate the learning progress of the controller which generates the architectures in ENAS. We measure the progress by comparing the architectures generated by it at different controller training epochs, where architectures are evaluated after having re-trained them from scratch. As a surprising result, we find that the learning curves are completely flat, i.e., there is no observable progress of the controller in terms of the performance of its generated architectures. This observation is consistent across the CIFAR-10 and CIFAR-100 datasets and two different search spaces. We conclude that the high quality of the models generated by ENAS is a result of the search space design rather than the controller training, and our results indicate that one-shot architecture design is an efficient alternative to architecture search by ENAS.