Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLAMS: A System for Zero-Shot Model Selection for Clustering
Paper and Code
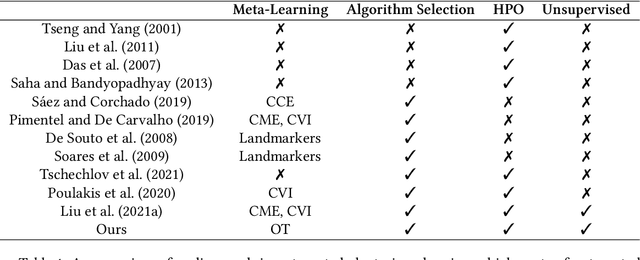

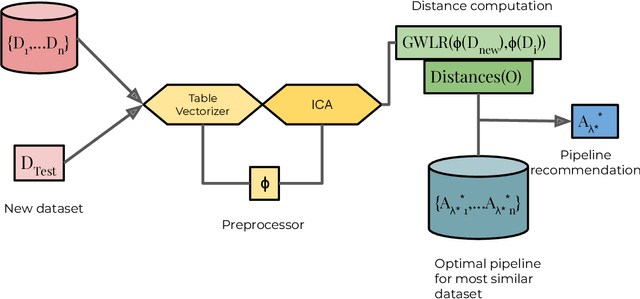
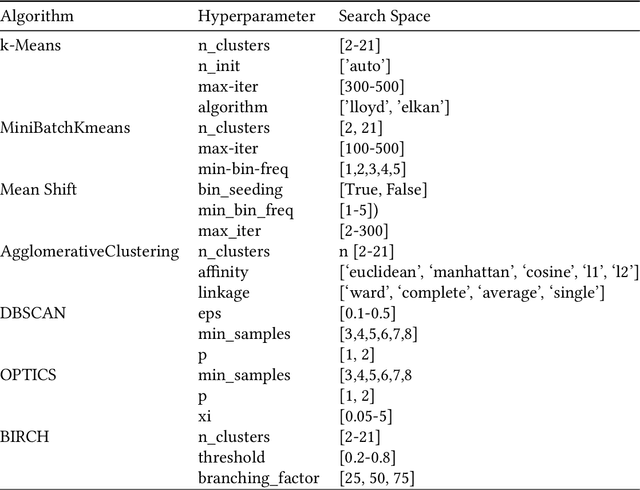
We propose an AutoML system that enables model selection on clustering problems by leveraging optimal transport-based dataset similarity. Our objective is to establish a comprehensive AutoML pipeline for clustering problems and provide recommendations for selecting the most suitable algorithms, thus opening up a new area of AutoML beyond the traditional supervised learning settings. We compare our results against multiple clustering baselines and find that it outperforms all of them, hence demonstrating the utility of similarity-based automated model selection for solving clustering applications.
View paper on