 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoML Benchmark with shorter time constraints and early stopping
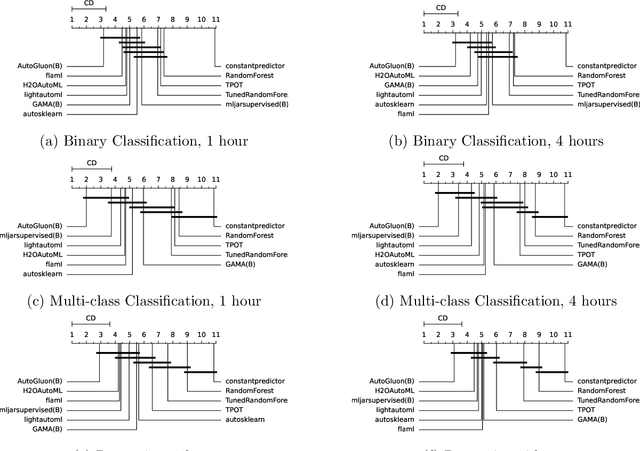
Apr 01, 2025Automated Machine Learning (AutoML) automatically builds machine learning (ML) models on data. The de facto standard for evaluating new AutoML frameworks for tabular data is the AutoML Benchmark (AMLB). AMLB proposed to evaluate AutoML frameworks using 1- and 4-hour time budgets across 104 tasks. We argue that shorter time constraints should be considered for the benchmark because of their practical value, such as when models need to be retrained with high frequency, and to make AMLB more accessible. This work considers two ways in which to reduce the overall computation used in the benchmark: smaller time constraints and the use of early stopping. We conduct evaluations of 11 AutoML frameworks on 104 tasks with different time constraints and find the relative ranking of AutoML frameworks is fairly consistent across time constraints, but that using early-stopping leads to a greater variety in model performance.
CLAMS: A System for Zero-Shot Model Selection for Clustering
Jul 15, 2024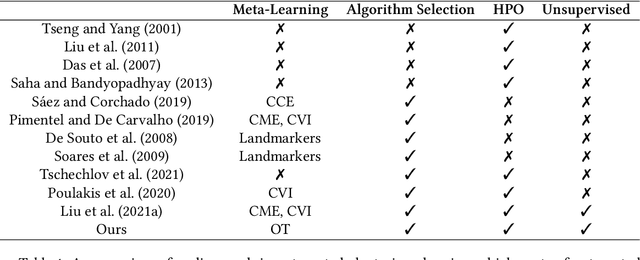

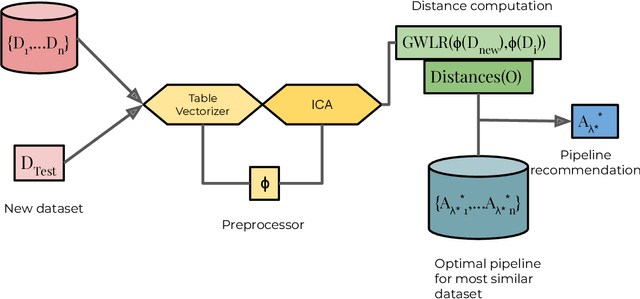
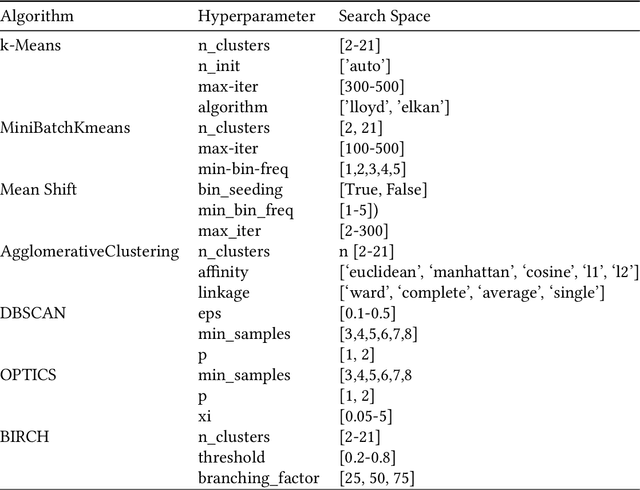
We propose an AutoML system that enables model selection on clustering problems by leveraging optimal transport-based dataset similarity. Our objective is to establish a comprehensive AutoML pipeline for clustering problems and provide recommendations for selecting the most suitable algorithms, thus opening up a new area of AutoML beyond the traditional supervised learning settings. We compare our results against multiple clustering baselines and find that it outperforms all of them, hence demonstrating the utility of similarity-based automated model selection for solving clustering applications.
AMLB: an AutoML Benchmark
Jul 25, 2022
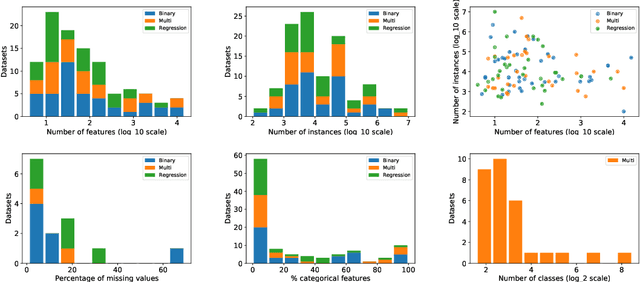
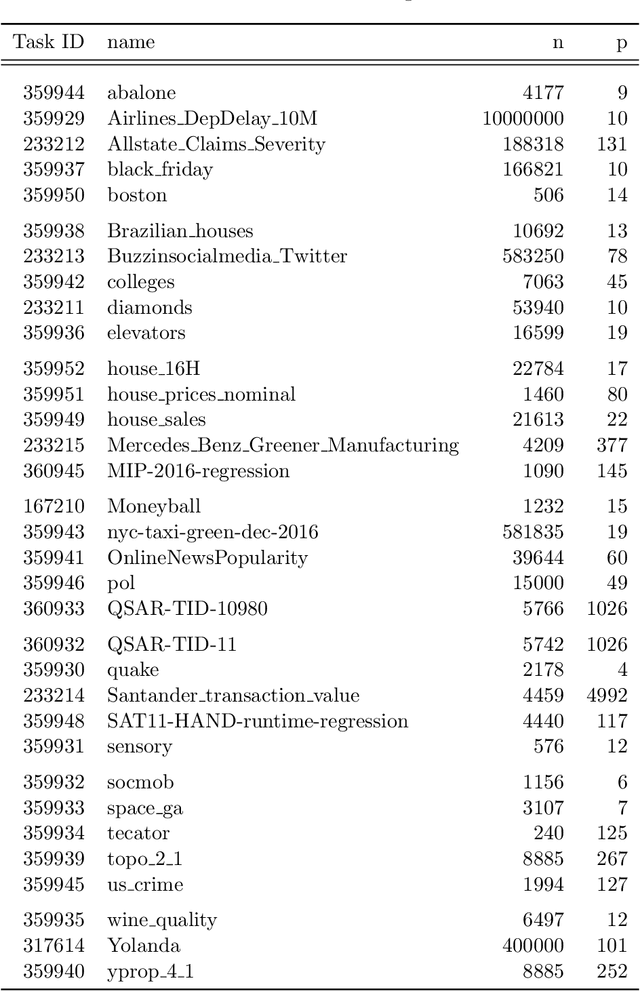
Comparing different AutoML frameworks is notoriously challenging and often done incorrectly. We introduce an open and extensible benchmark that follows best practices and avoids common mistakes when comparing AutoML frameworks. We conduct a thorough comparison of 9 well-known AutoML frameworks across 71 classification and 33 regression tasks. The differences between the AutoML frameworks are explored with a multi-faceted analysis, evaluating model accuracy, its trade-offs with inference time, and framework failures. We also use Bradley-Terry trees to discover subsets of tasks where the relative AutoML framework rankings differ. The benchmark comes with an open-source tool that integrates with many AutoML frameworks and automates the empirical evaluation process end-to-end: from framework installation and resource allocation to in-depth evaluation. The benchmark uses public data sets, can be easily extended with other AutoML frameworks and tasks, and has a website with up-to-date results.
Meta-Learning for Symbolic Hyperparameter Defaults
Jun 11, 2021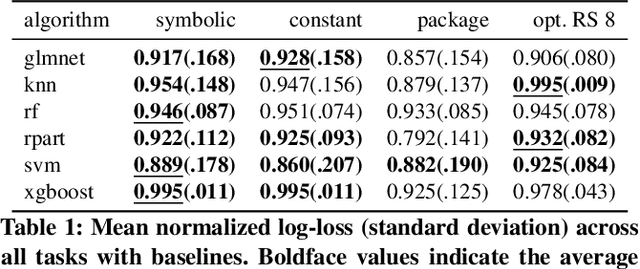
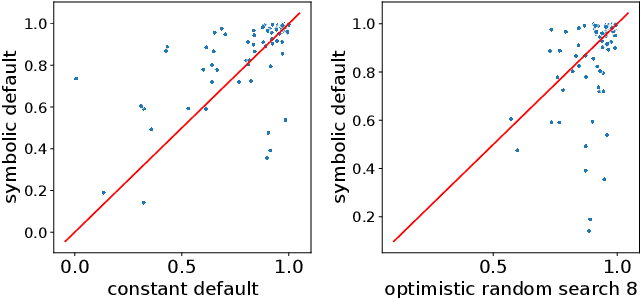

Hyperparameter optimization in machine learning (ML) deals with the problem of empirically learning an optimal algorithm configuration from data, usually formulated as a black-box optimization problem. In this work, we propose a zero-shot method to meta-learn symbolic default hyperparameter configurations that are expressed in terms of the properties of the dataset. This enables a much faster, but still data-dependent, configuration of the ML algorithm, compared to standard hyperparameter optimization approaches. In the past, symbolic and static default values have usually been obtained as hand-crafted heuristics. We propose an approach of learning such symbolic configurations as formulas of dataset properties from a large set of prior evaluations on multiple datasets by optimizing over a grammar of expressions using an evolutionary algorithm. We evaluate our method on surrogate empirical performance models as well as on real data across 6 ML algorithms on more than 100 datasets and demonstrate that our method indeed finds viable symbolic defaults.
GAMA: a General Automated Machine learning Assistant
Jul 09, 2020

The General Automated Machine learning Assistant (GAMA) is a modular AutoML system developed to empower users to track and control how AutoML algorithms search for optimal machine learning pipelines, and facilitate AutoML research itself. In contrast to current, often black-box systems, GAMA allows users to plug in different AutoML and post-processing techniques, logs and visualizes the search process, and supports easy benchmarking. It currently features three AutoML search algorithms, two model post-processing steps, and is designed to allow for more components to be added.
OpenML-Python: an extensible Python API for OpenML
Nov 06, 2019
OpenML is an online platform for open science collaboration in machine learning, used to share datasets and results of machine learning experiments. In this paper we introduce \emph{OpenML-Python}, a client API for Python, opening up the OpenML platform for a wide range of Python-based tools. It provides easy access to all datasets, tasks and experiments on OpenML from within Python. It also provides functionality to conduct machine learning experiments, upload the results to OpenML, and reproduce results which are stored on OpenML. Furthermore, it comes with a scikit-learn plugin and a plugin mechanism to easily integrate other machine learning libraries written in Python into the OpenML ecosystem. Source code and documentation is available at https://github.com/openml/openml-python/.
An Open Source AutoML Benchmark
Jul 01, 2019

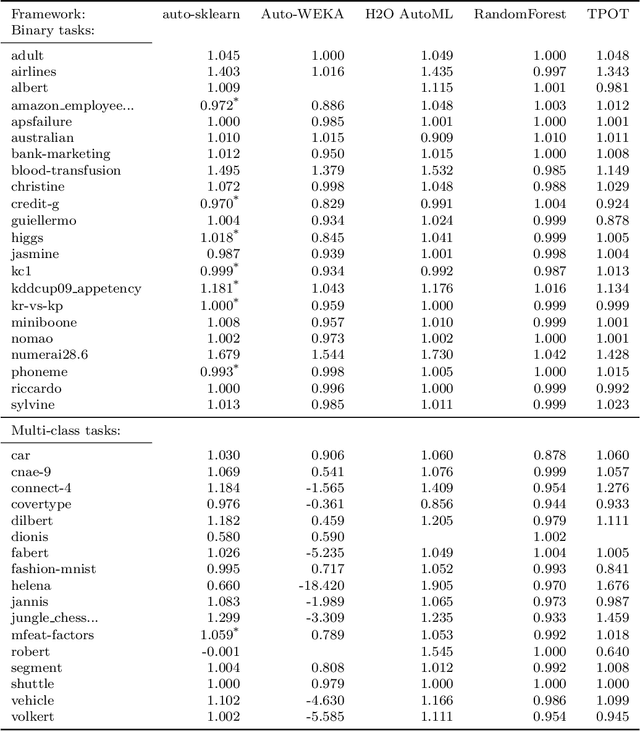
In recent years, an active field of research has developed around automated machine learning (AutoML). Unfortunately, comparing different AutoML systems is hard and often done incorrectly. We introduce an open, ongoing, and extensible benchmark framework which follows best practices and avoids common mistakes. The framework is open-source, uses public datasets and has a website with up-to-date results. We use the framework to conduct a thorough comparison of 4 AutoML systems across 39 datasets and analyze the results.
Layered TPOT: Speeding up Tree-based Pipeline Optimization
Mar 12, 2018
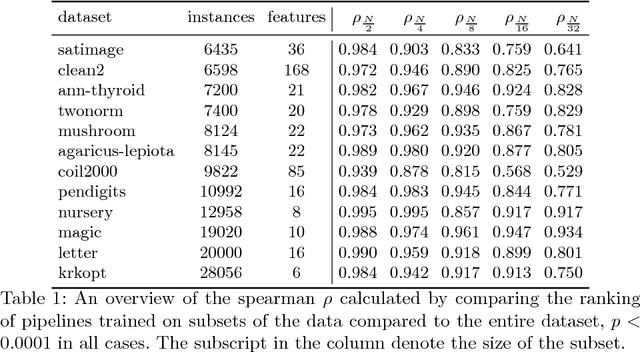
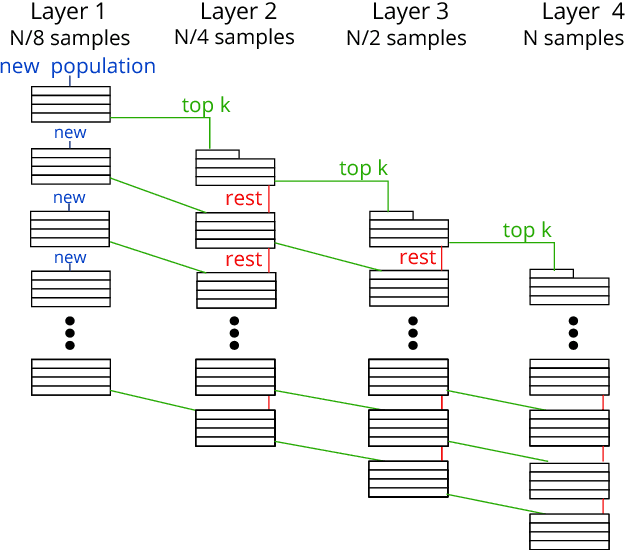
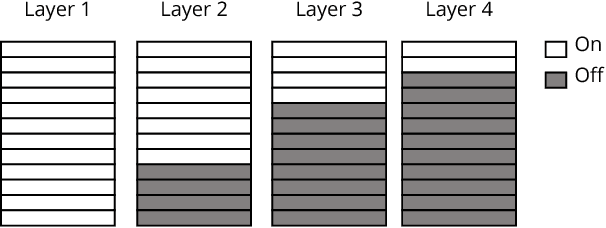
With the demand for machine learning increasing, so does the demand for tools which make it easier to use. Automated machine learning (AutoML) tools have been developed to address this need, such as the Tree-Based Pipeline Optimization Tool (TPOT) which uses genetic programming to build optimal pipelines. We introduce Layered TPOT, a modification to TPOT which aims to create pipelines equally good as the original, but in significantly less time. This approach evaluates candidate pipelines on increasingly large subsets of the data according to their fitness, using a modified evolutionary algorithm to allow for separate competition between pipelines trained on different sample sizes. Empirical evaluation shows that, on sufficiently large datasets, Layered TPOT indeed finds better models faster.