 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustness of AutoML on Dirty Categorical Data
Jan 31, 2026The goal of automated machine learning (AutoML) is to reduce trial and error when doing machine learning (ML). Although AutoML methods for classification are able to deal with data imperfections, such as outliers, multiple scales and missing data, their behavior is less known on dirty categorical datasets. These datasets often have several categorical features with high cardinality arising from issues such as lack of curation and automated collection. Recent research has shown that ML models can benefit from morphological encoders for dirty categorical data, leading to significantly superior predictive performance. However the effects of using such encoders in AutoML methods are not known at the moment. In this paper, we propose a pipeline that transforms categorical data into numerical data so that an AutoML can handle categorical data transformed by more advanced encoding schemes. We benchmark the current robustness of AutoML methods on a set of dirty datasets and compare it with the proposed pipeline. This allows us to get insight on differences in predictive performance. We also look at the ML pipelines built by AutoMLs in order to gain insight beyond the best model as typically returned by these methods.
AMLB: an AutoML Benchmark
Jul 25, 2022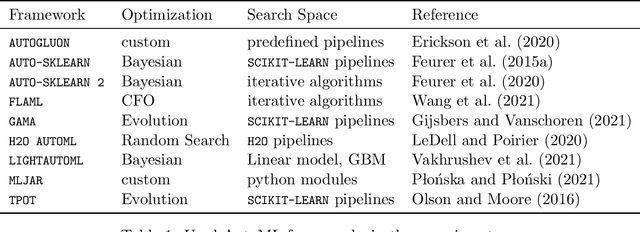
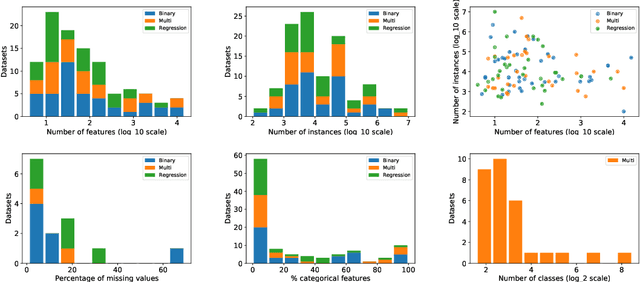
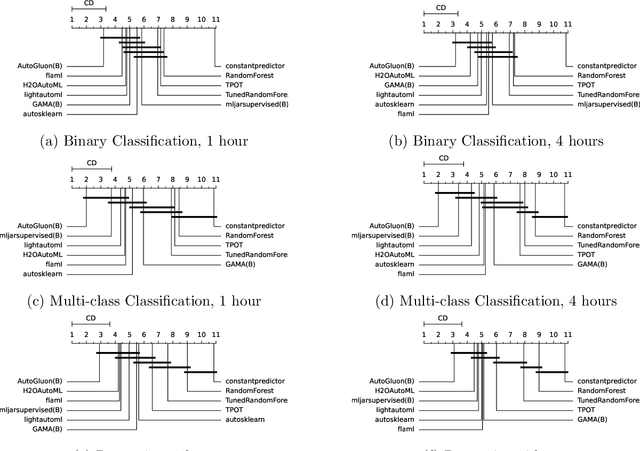
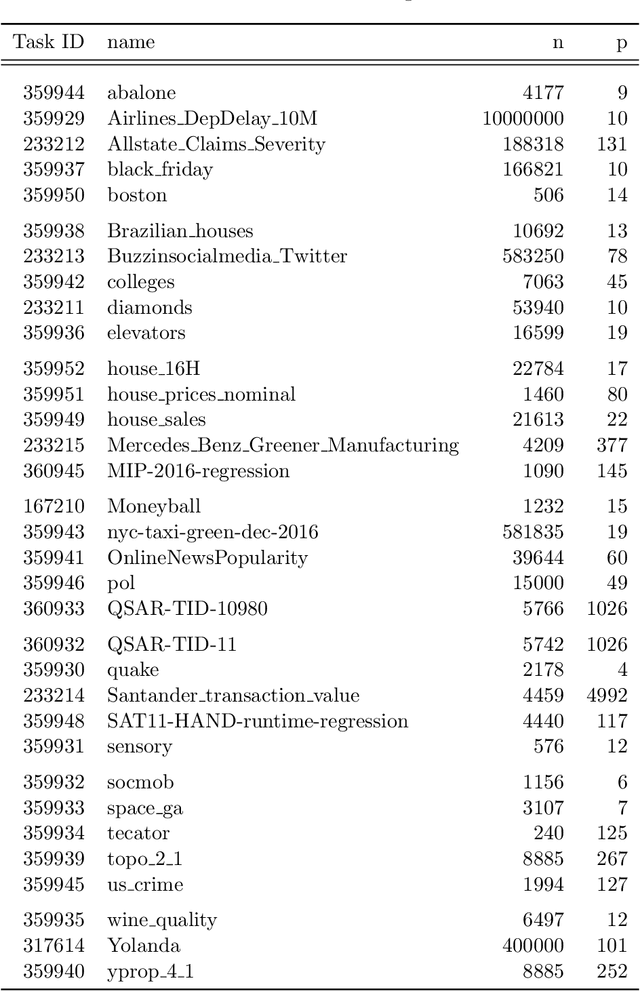
Comparing different AutoML frameworks is notoriously challenging and often done incorrectly. We introduce an open and extensible benchmark that follows best practices and avoids common mistakes when comparing AutoML frameworks. We conduct a thorough comparison of 9 well-known AutoML frameworks across 71 classification and 33 regression tasks. The differences between the AutoML frameworks are explored with a multi-faceted analysis, evaluating model accuracy, its trade-offs with inference time, and framework failures. We also use Bradley-Terry trees to discover subsets of tasks where the relative AutoML framework rankings differ. The benchmark comes with an open-source tool that integrates with many AutoML frameworks and automates the empirical evaluation process end-to-end: from framework installation and resource allocation to in-depth evaluation. The benchmark uses public data sets, can be easily extended with other AutoML frameworks and tasks, and has a website with up-to-date results.