 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest Practices For Empirical Meta-Algorithmic Research: Guidelines from the COSEAL Research Network
Dec 19, 2025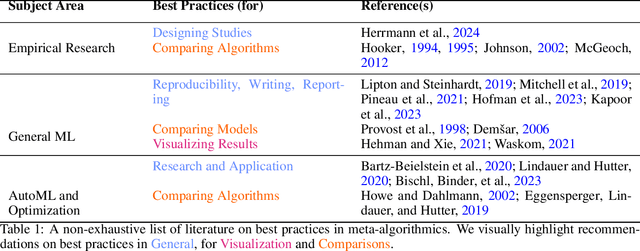
Empirical research on meta-algorithmics, such as algorithm selection, configuration, and scheduling, often relies on extensive and thus computationally expensive experiments. With the large degree of freedom we have over our experimental setup and design comes a plethora of possible error sources that threaten the scalability and validity of our scientific insights. Best practices for meta-algorithmic research exist, but they are scattered between different publications and fields, and continue to evolve separately from each other. In this report, we collect good practices for empirical meta-algorithmic research across the subfields of the COSEAL community, encompassing the entire experimental cycle: from formulating research questions and selecting an experimental design, to executing experiments, and ultimately, analyzing and presenting results impartially. It establishes the current state-of-the-art practices within meta-algorithmic research and serves as a guideline to both new researchers and practitioners in meta-algorithmic fields.
Overtuning in Hyperparameter Optimization
Jun 24, 2025Hyperparameter optimization (HPO) aims to identify an optimal hyperparameter configuration (HPC) such that the resulting model generalizes well to unseen data. As the expected generalization error cannot be optimized directly, it is estimated with a resampling strategy, such as holdout or cross-validation. This approach implicitly assumes that minimizing the validation error leads to improved generalization. However, since validation error estimates are inherently stochastic and depend on the resampling strategy, a natural question arises: Can excessive optimization of the validation error lead to overfitting at the HPO level, akin to overfitting in model training based on empirical risk minimization? In this paper, we investigate this phenomenon, which we term overtuning, a form of overfitting specific to HPO. Despite its practical relevance, overtuning has received limited attention in the HPO and AutoML literature. We provide a formal definition of overtuning and distinguish it from related concepts such as meta-overfitting. We then conduct a large-scale reanalysis of HPO benchmark data to assess the prevalence and severity of overtuning. Our results show that overtuning is more common than previously assumed, typically mild but occasionally severe. In approximately 10% of cases, overtuning leads to the selection of a seemingly optimal HPC with worse generalization error than the default or first configuration tried. We further analyze how factors such as performance metric, resampling strategy, dataset size, learning algorithm, and HPO method affect overtuning and discuss mitigation strategies. Our results highlight the need to raise awareness of overtuning, particularly in the small-data regime, indicating that further mitigation strategies should be studied.
carps: A Framework for Comparing N Hyperparameter Optimizers on M Benchmarks
Jun 06, 2025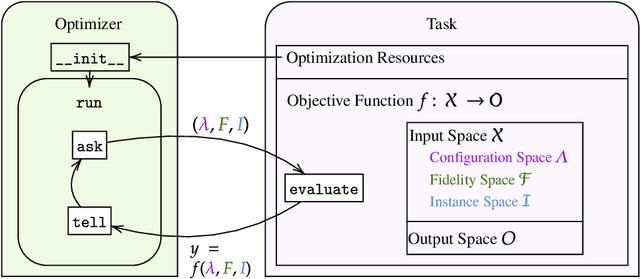

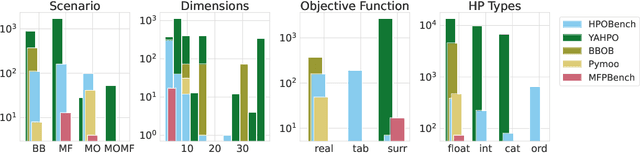
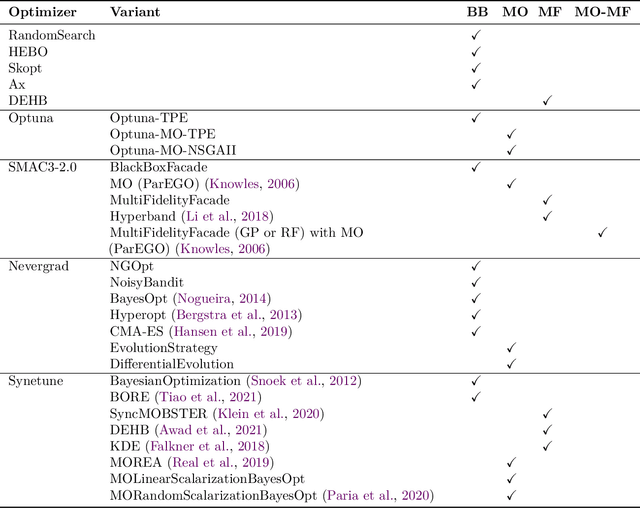
Hyperparameter Optimization (HPO) is crucial to develop well-performing machine learning models. In order to ease prototyping and benchmarking of HPO methods, we propose carps, a benchmark framework for Comprehensive Automated Research Performance Studies allowing to evaluate N optimizers on M benchmark tasks. In this first release of carps, we focus on the four most important types of HPO task types: blackbox, multi-fidelity, multi-objective and multi-fidelity-multi-objective. With 3 336 tasks from 5 community benchmark collections and 28 variants of 9 optimizer families, we offer the biggest go-to library to date to evaluate and compare HPO methods. The carps framework relies on a purpose-built, lightweight interface, gluing together optimizers and benchmark tasks. It also features an analysis pipeline, facilitating the evaluation of optimizers on benchmarks. However, navigating a huge number of tasks while developing and comparing methods can be computationally infeasible. To address this, we obtain a subset of representative tasks by minimizing the star discrepancy of the subset, in the space spanned by the full set. As a result, we propose an initial subset of 10 to 30 diverse tasks for each task type, and include functionality to re-compute subsets as more benchmarks become available, enabling efficient evaluations. We also establish a first set of baseline results on these tasks as a measure for future comparisons. With carps (https://www.github.com/automl/CARP-S), we make an important step in the standardization of HPO evaluation.
CAPO: Cost-Aware Prompt Optimization
Apr 22, 2025


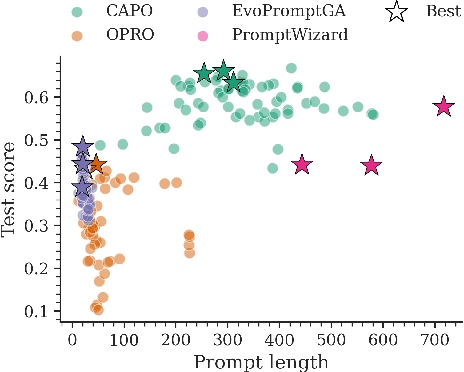
Large language models (LLMs) have revolutionized natural language processing by solving a wide range of tasks simply guided by a prompt. Yet their performance is highly sensitive to prompt formulation. While automated prompt optimization addresses this challenge by finding optimal prompts, current methods require a substantial number of LLM calls and input tokens, making prompt optimization expensive. We introduce CAPO (Cost-Aware Prompt Optimization), an algorithm that enhances prompt optimization efficiency by integrating AutoML techniques. CAPO is an evolutionary approach with LLMs as operators, incorporating racing to save evaluations and multi-objective optimization to balance performance with prompt length. It jointly optimizes instructions and few-shot examples while leveraging task descriptions for improved robustness. Our extensive experiments across diverse datasets and LLMs demonstrate that CAPO outperforms state-of-the-art discrete prompt optimization methods in 11/15 cases with improvements up to 21%p. Our algorithm achieves better performances already with smaller budgets, saves evaluations through racing, and decreases average prompt length via a length penalty, making it both cost-efficient and cost-aware. Even without few-shot examples, CAPO outperforms its competitors and generally remains robust to initial prompts. CAPO represents an important step toward making prompt optimization more powerful and accessible by improving cost-efficiency.
Position: A Call to Action for a Human-Centered AutoML Paradigm
Jun 05, 2024Automated machine learning (AutoML) was formed around the fundamental objectives of automatically and efficiently configuring machine learning (ML) workflows, aiding the research of new ML algorithms, and contributing to the democratization of ML by making it accessible to a broader audience. Over the past decade, commendable achievements in AutoML have primarily focused on optimizing predictive performance. This focused progress, while substantial, raises questions about how well AutoML has met its broader, original goals. In this position paper, we argue that a key to unlocking AutoML's full potential lies in addressing the currently underexplored aspect of user interaction with AutoML systems, including their diverse roles, expectations, and expertise. We envision a more human-centered approach in future AutoML research, promoting the collaborative design of ML systems that tightly integrates the complementary strengths of human expertise and AutoML methodologies.
Reshuffling Resampling Splits Can Improve Generalization of Hyperparameter Optimization
May 24, 2024



Hyperparameter optimization is crucial for obtaining peak performance of machine learning models. The standard protocol evaluates various hyperparameter configurations using a resampling estimate of the generalization error to guide optimization and select a final hyperparameter configuration. Without much evidence, paired resampling splits, i.e., either a fixed train-validation split or a fixed cross-validation scheme, are often recommended. We show that, surprisingly, reshuffling the splits for every configuration often improves the final model's generalization performance on unseen data. Our theoretical analysis explains how reshuffling affects the asymptotic behavior of the validation loss surface and provides a bound on the expected regret in the limiting regime. This bound connects the potential benefits of reshuffling to the signal and noise characteristics of the underlying optimization problem. We confirm our theoretical results in a controlled simulation study and demonstrate the practical usefulness of reshuffling in a large-scale, realistic hyperparameter optimization experiment. While reshuffling leads to test performances that are competitive with using fixed splits, it drastically improves results for a single train-validation holdout protocol and can often make holdout become competitive with standard CV while being computationally cheaper.
Position Paper: Rethinking Empirical Research in Machine Learning: Addressing Epistemic and Methodological Challenges of Experimentation
May 03, 2024We warn against a common but incomplete understanding of empirical research in machine learning (ML) that leads to non-replicable results, makes findings unreliable, and threatens to undermine progress in the field. To overcome this alarming situation, we call for more awareness of the plurality of ways of gaining knowledge experimentally but also of some epistemic limitations. In particular, we argue most current empirical ML research is fashioned as confirmatory research while it should rather be considered exploratory.
Interpretable Machine Learning for TabPFN
Mar 16, 2024The recently developed Prior-Data Fitted Networks (PFNs) have shown very promising results for applications in low-data regimes. The TabPFN model, a special case of PFNs for tabular data, is able to achieve state-of-the-art performance on a variety of classification tasks while producing posterior predictive distributions in mere seconds by in-context learning without the need for learning parameters or hyperparameter tuning. This makes TabPFN a very attractive option for a wide range of domain applications. However, a major drawback of the method is its lack of interpretability. Therefore, we propose several adaptations of popular interpretability methods that we specifically design for TabPFN. By taking advantage of the unique properties of the model, our adaptations allow for more efficient computations than existing implementations. In particular, we show how in-context learning facilitates the estimation of Shapley values by avoiding approximate retraining and enables the use of Leave-One-Covariate-Out (LOCO) even when working with large-scale Transformers. In addition, we demonstrate how data valuation methods can be used to address scalability challenges of TabPFN. Our proposed methods are implemented in a package tabpfn_iml and made available at https://github.com/david-rundel/tabpfn_iml.
PFNs4BO: In-Context Learning for Bayesian Optimization
Jun 09, 2023



In this paper, we use Prior-data Fitted Networks (PFNs) as a flexible surrogate for Bayesian Optimization (BO). PFNs are neural processes that are trained to approximate the posterior predictive distribution (PPD) through in-context learning on any prior distribution that can be efficiently sampled from. We describe how this flexibility can be exploited for surrogate modeling in BO. We use PFNs to mimic a naive Gaussian process (GP), an advanced GP, and a Bayesian Neural Network (BNN). In addition, we show how to incorporate further information into the prior, such as allowing hints about the position of optima (user priors), ignoring irrelevant dimensions, and performing non-myopic BO by learning the acquisition function. The flexibility underlying these extensions opens up vast possibilities for using PFNs for BO. We demonstrate the usefulness of PFNs for BO in a large-scale evaluation on artificial GP samples and three different hyperparameter optimization testbeds: HPO-B, Bayesmark, and PD1. We publish code alongside trained models at https://github.com/automl/PFNs4BO.
Can Fairness be Automated? Guidelines and Opportunities for Fairness-aware AutoML
Mar 15, 2023


The field of automated machine learning (AutoML) introduces techniques that automate parts of the development of machine learning (ML) systems, accelerating the process and reducing barriers for novices. However, decisions derived from ML models can reproduce, amplify, or even introduce unfairness in our societies, causing harm to (groups of) individuals. In response, researchers have started to propose AutoML systems that jointly optimize fairness and predictive performance to mitigate fairness-related harm. However, fairness is a complex and inherently interdisciplinary subject, and solely posing it as an optimization problem can have adverse side effects. With this work, we aim to raise awareness among developers of AutoML systems about such limitations of fairness-aware AutoML, while also calling attention to the potential of AutoML as a tool for fairness research. We present a comprehensive overview of different ways in which fairness-related harm can arise and the ensuing implications for the design of fairness-aware AutoML. We conclude that while fairness cannot be automated, fairness-aware AutoML can play an important role in the toolbox of an ML practitioner. We highlight several open technical challenges for future work in this direction. Additionally, we advocate for the creation of more user-centered assistive systems designed to tackle challenges encountered in fairness work.