 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: A Call to Action for a Human-Centered AutoML Paradigm
Jun 05, 2024Automated machine learning (AutoML) was formed around the fundamental objectives of automatically and efficiently configuring machine learning (ML) workflows, aiding the research of new ML algorithms, and contributing to the democratization of ML by making it accessible to a broader audience. Over the past decade, commendable achievements in AutoML have primarily focused on optimizing predictive performance. This focused progress, while substantial, raises questions about how well AutoML has met its broader, original goals. In this position paper, we argue that a key to unlocking AutoML's full potential lies in addressing the currently underexplored aspect of user interaction with AutoML systems, including their diverse roles, expectations, and expertise. We envision a more human-centered approach in future AutoML research, promoting the collaborative design of ML systems that tightly integrates the complementary strengths of human expertise and AutoML methodologies.
Position Paper: Bridging the Gap Between Machine Learning and Sensitivity Analysis
Dec 20, 2023We argue that interpretations of machine learning (ML) models or the model-building process can bee seen as a form of sensitivity analysis (SA), a general methodology used to explain complex systems in many fields such as environmental modeling, engineering, or economics. We address both researchers and practitioners, calling attention to the benefits of a unified SA-based view of explanations in ML and the necessity to fully credit related work. We bridge the gap between both fields by formally describing how (a) the ML process is a system suitable for SA, (b) how existing ML interpretation methods relate to this perspective, and (c) how other SA techniques could be applied to ML.
RAISE -- Radiology AI Safety, an End-to-end lifecycle approach
Nov 24, 2023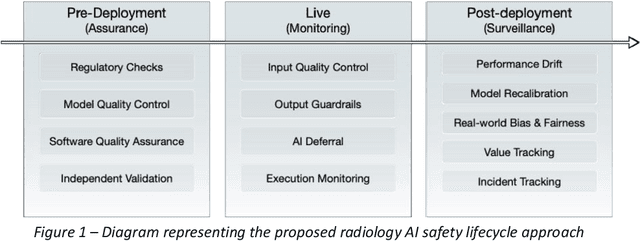
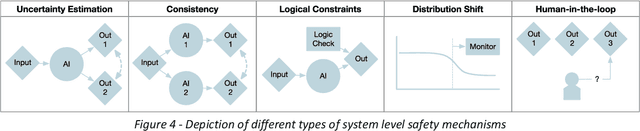
The integration of AI into radiology introduces opportunities for improved clinical care provision and efficiency but it demands a meticulous approach to mitigate potential risks as with any other new technology. Beginning with rigorous pre-deployment evaluation and validation, the focus should be on ensuring models meet the highest standards of safety, effectiveness and efficacy for their intended applications. Input and output guardrails implemented during production usage act as an additional layer of protection, identifying and addressing individual failures as they occur. Continuous post-deployment monitoring allows for tracking population-level performance (data drift), fairness, and value delivery over time. Scheduling reviews of post-deployment model performance and educating radiologists about new algorithmic-driven findings is critical for AI to be effective in clinical practice. Recognizing that no single AI solution can provide absolute assurance even when limited to its intended use, the synergistic application of quality assurance at multiple levels - regulatory, clinical, technical, and ethical - is emphasized. Collaborative efforts between stakeholders spanning healthcare systems, industry, academia, and government are imperative to address the multifaceted challenges involved. Trust in AI is an earned privilege, contingent on a broad set of goals, among them transparently demonstrating that the AI adheres to the same rigorous safety, effectiveness and efficacy standards as other established medical technologies. By doing so, developers can instil confidence among providers and patients alike, enabling the responsible scaling of AI and the realization of its potential benefits. The roadmap presented herein aims to expedite the achievement of deployable, reliable, and safe AI in radiology.
Multi-Objective Hyperparameter Optimization -- An Overview
Jun 15, 2022

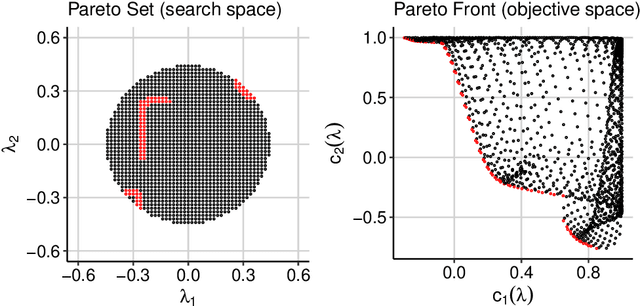
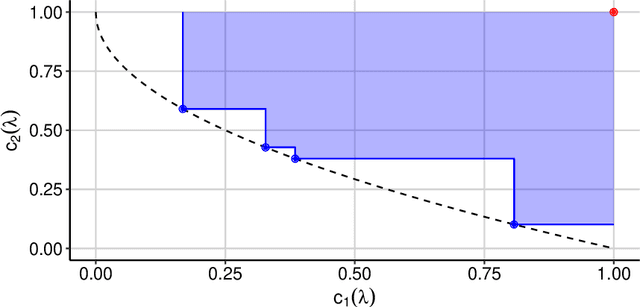
Hyperparameter optimization constitutes a large part of typical modern machine learning workflows. This arises from the fact that machine learning methods and corresponding preprocessing steps often only yield optimal performance when hyperparameters are properly tuned. But in many applications, we are not only interested in optimizing ML pipelines solely for predictive accuracy; additional metrics or constraints must be considered when determining an optimal configuration, resulting in a multi-objective optimization problem. This is often neglected in practice, due to a lack of knowledge and readily available software implementations for multi-objective hyperparameter optimization. In this work, we introduce the reader to the basics of multi- objective hyperparameter optimization and motivate its usefulness in applied ML. Furthermore, we provide an extensive survey of existing optimization strategies, both from the domain of evolutionary algorithms and Bayesian optimization. We illustrate the utility of MOO in several specific ML applications, considering objectives such as operating conditions, prediction time, sparseness, fairness, interpretability and robustness.
Enhancing Explainability of Hyperparameter Optimization via Bayesian Algorithm Execution
Jun 11, 2022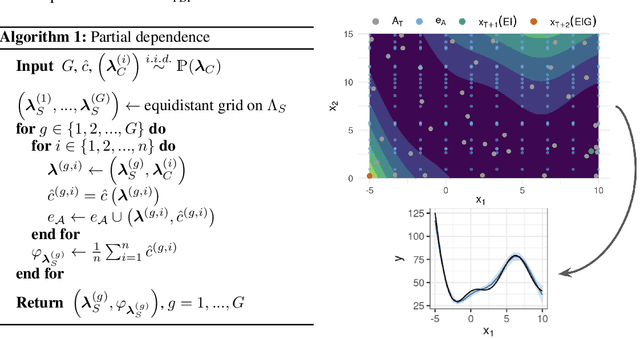
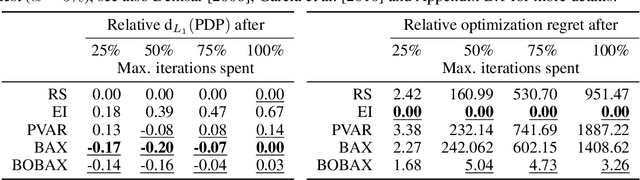


Despite all the benefits of automated hyperparameter optimization (HPO), most modern HPO algorithms are black-boxes themselves. This makes it difficult to understand the decision process which lead to the selected configuration, reduces trust in HPO, and thus hinders its broad adoption. Here, we study the combination of HPO with interpretable machine learning (IML) methods such as partial dependence plots. However, if such methods are naively applied to the experimental data of the HPO process in a post-hoc manner, the underlying sampling bias of the optimizer can distort interpretations. We propose a modified HPO method which efficiently balances the search for the global optimum w.r.t. predictive performance and the reliable estimation of IML explanations of an underlying black-box function by coupling Bayesian optimization and Bayesian Algorithm Execution. On benchmark cases of both synthetic objectives and HPO of a neural network, we demonstrate that our method returns more reliable explanations of the underlying black-box without a loss of optimization performance.
Automated Benchmark-Driven Design and Explanation of Hyperparameter Optimizers
Nov 29, 2021
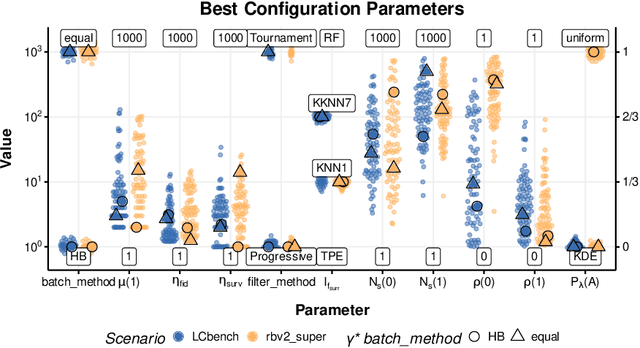

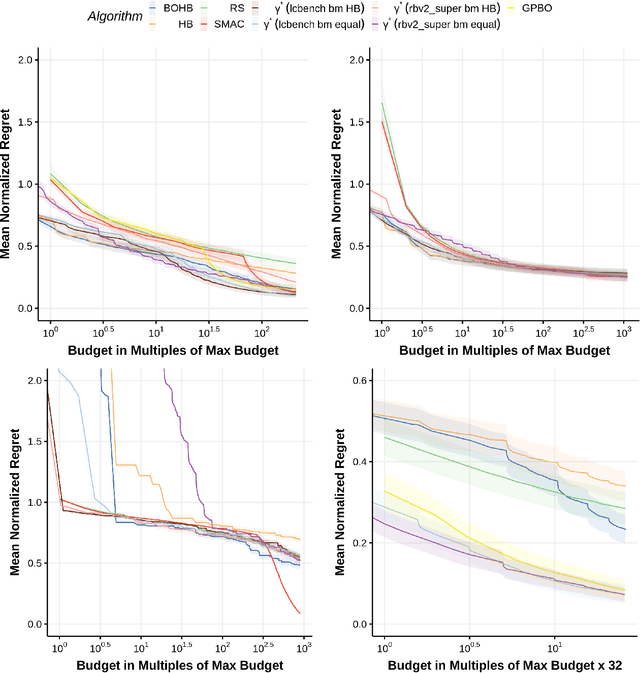
Automated hyperparameter optimization (HPO) has gained great popularity and is an important ingredient of most automated machine learning frameworks. The process of designing HPO algorithms, however, is still an unsystematic and manual process: Limitations of prior work are identified and the improvements proposed are -- even though guided by expert knowledge -- still somewhat arbitrary. This rarely allows for gaining a holistic understanding of which algorithmic components are driving performance, and carries the risk of overlooking good algorithmic design choices. We present a principled approach to automated benchmark-driven algorithm design applied to multifidelity HPO (MF-HPO): First, we formalize a rich space of MF-HPO candidates that includes, but is not limited to common HPO algorithms, and then present a configurable framework covering this space. To find the best candidate automatically and systematically, we follow a programming-by-optimization approach and search over the space of algorithm candidates via Bayesian optimization. We challenge whether the found design choices are necessary or could be replaced by more naive and simpler ones by performing an ablation analysis. We observe that using a relatively simple configuration, in some ways simpler than established methods, performs very well as long as some critical configuration parameters have the right value.
Explaining Hyperparameter Optimization via Partial Dependence Plots
Nov 08, 2021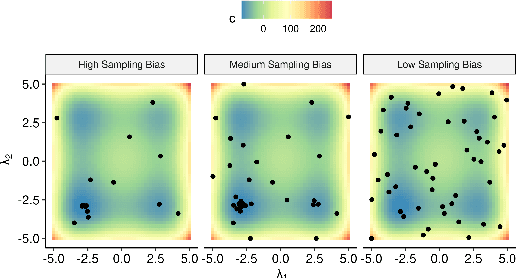
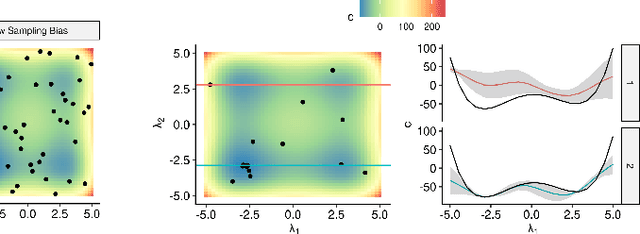
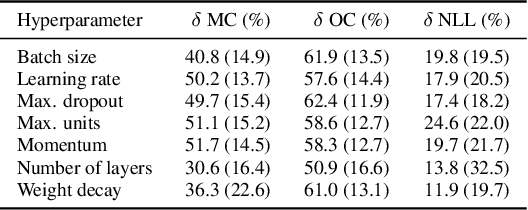
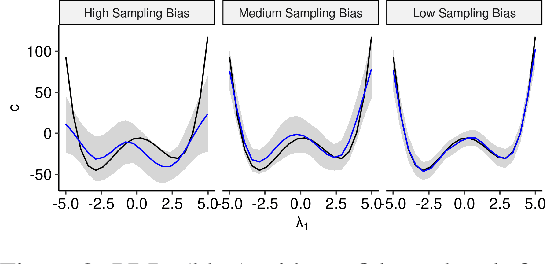
Automated hyperparameter optimization (HPO) can support practitioners to obtain peak performance in machine learning models. However, there is often a lack of valuable insights into the effects of different hyperparameters on the final model performance. This lack of explainability makes it difficult to trust and understand the automated HPO process and its results. We suggest using interpretable machine learning (IML) to gain insights from the experimental data obtained during HPO with Bayesian optimization (BO). BO tends to focus on promising regions with potential high-performance configurations and thus induces a sampling bias. Hence, many IML techniques, such as the partial dependence plot (PDP), carry the risk of generating biased interpretations. By leveraging the posterior uncertainty of the BO surrogate model, we introduce a variant of the PDP with estimated confidence bands. We propose to partition the hyperparameter space to obtain more confident and reliable PDPs in relevant sub-regions. In an experimental study, we provide quantitative evidence for the increased quality of the PDPs within sub-regions.
YAHPO Gym -- Design Criteria and a new Multifidelity Benchmark for Hyperparameter Optimization
Sep 08, 2021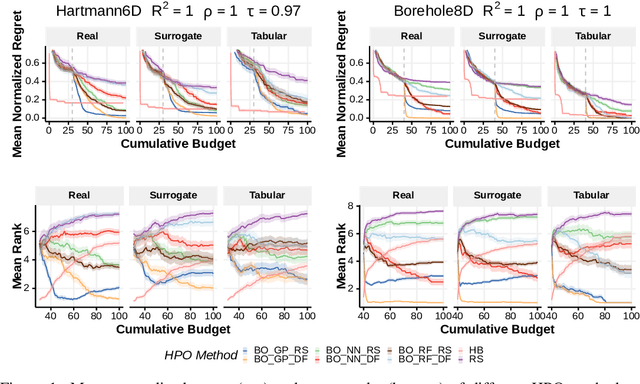

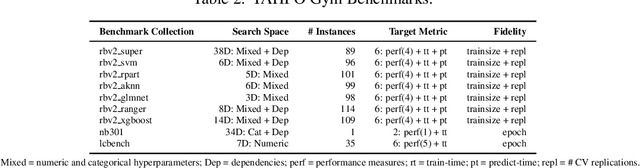
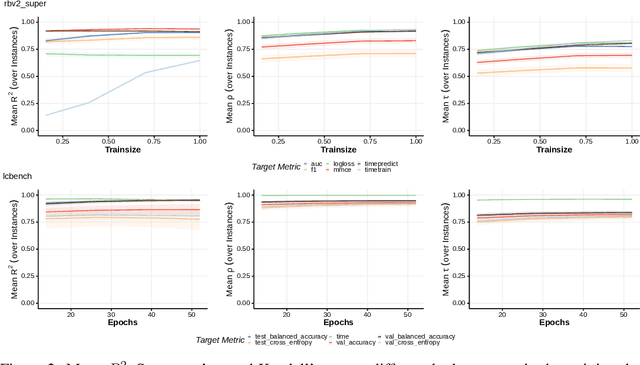
When developing and analyzing new hyperparameter optimization (HPO) methods, it is vital to empirically evaluate and compare them on well-curated benchmark suites. In this work, we list desirable properties and requirements for such benchmarks and propose a new set of challenging and relevant multifidelity HPO benchmark problems motivated by these requirements. For this, we revisit the concept of surrogate-based benchmarks and empirically compare them to more widely-used tabular benchmarks, showing that the latter ones may induce bias in performance estimation and ranking of HPO methods. We present a new surrogate-based benchmark suite for multifidelity HPO methods consisting of 9 benchmark collections that constitute over 700 multifidelity HPO problems in total. All our benchmarks also allow for querying of multiple optimization targets, enabling the benchmarking of multi-objective HPO. We examine and compare our benchmark suite with respect to the defined requirements and show that our benchmarks provide viable additions to existing suites.
Train, Learn, Expand, Repeat
Apr 19, 2020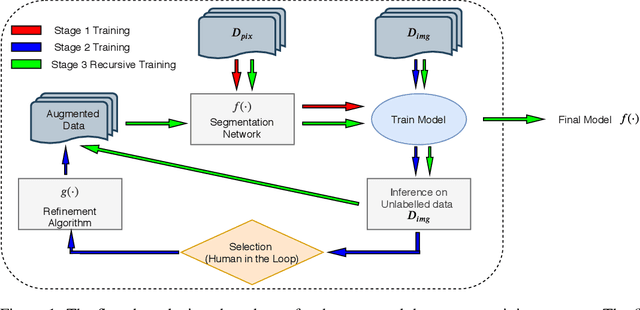
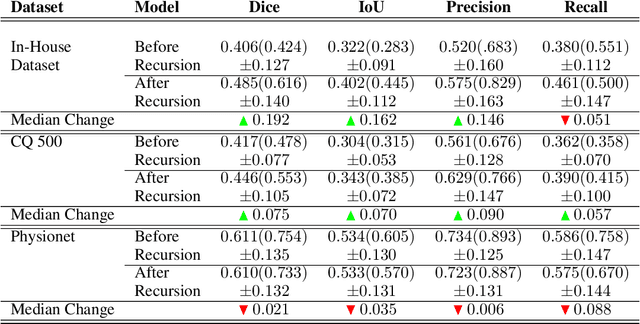
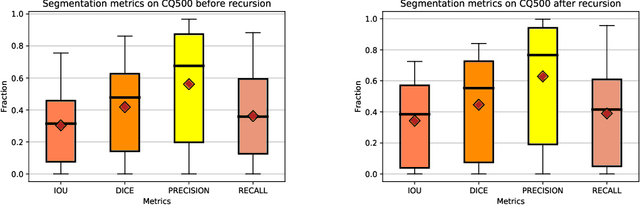
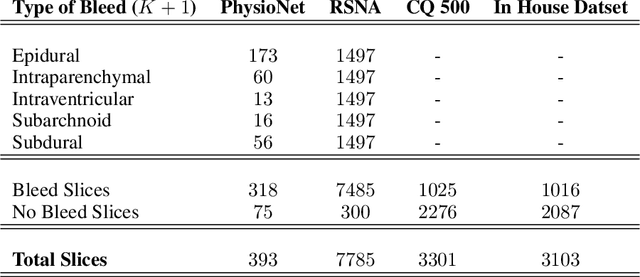
High-quality labeled data is essential to successfully train supervised machine learning models. Although a large amount of unlabeled data is present in the medical domain, labeling poses a major challenge: medical professionals who can expertly label the data are a scarce and expensive resource. Making matters worse, voxel-wise delineation of data (e.g. for segmentation tasks) is tedious and suffers from high inter-rater variance, thus dramatically limiting available training data. We propose a recursive training strategy to perform the task of semantic segmentation given only very few training samples with pixel-level annotations. We expand on this small training set having cheaper image-level annotations using a recursive training strategy. We apply this technique on the segmentation of intracranial hemorrhage (ICH) in CT (computed tomography) scans of the brain, where typically few annotated data is available.
Multi-Objective Hyperparameter Tuning and Feature Selection using Filter Ensembles
Feb 13, 2020
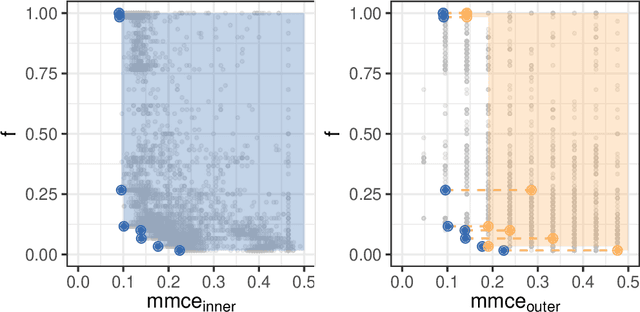
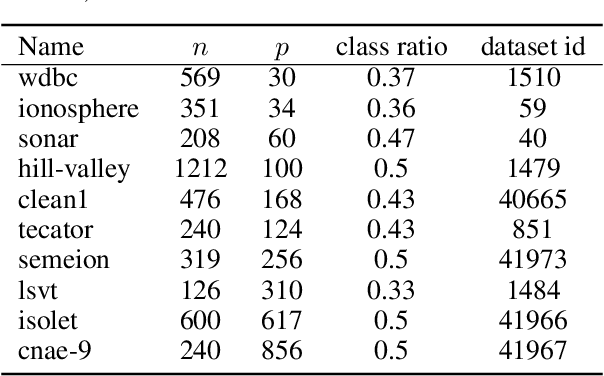
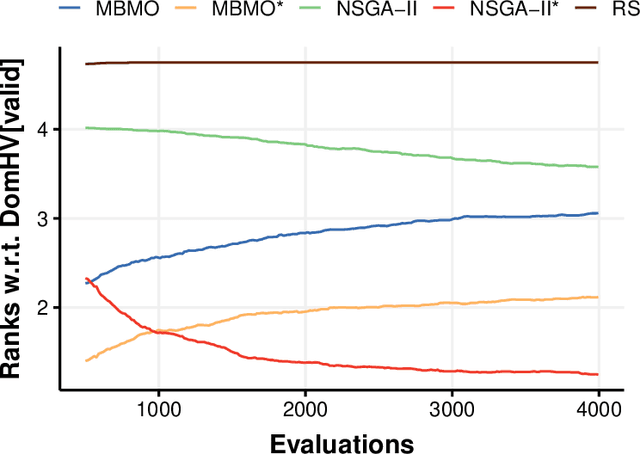
Both feature selection and hyperparameter tuning are key tasks in machine learning. Hyperparameter tuning is often useful to increase model performance, while feature selection is undertaken to attain sparse models. Sparsity may yield better model interpretability and lower cost of data acquisition, data handling and model inference. While sparsity may have a beneficial or detrimental effect on predictive performance, a small drop in performance may be acceptable in return for a substantial gain in sparseness. We therefore treat feature selection as a multi-objective optimization task. We perform hyperparameter tuning and feature selection simultaneously because the choice of features of a model may influence what hyperparameters perform well. We present, benchmark, and compare two different approaches for multi-objective joint hyperparameter optimization and feature selection: The first uses multi-objective model-based optimization. The second is an evolutionary NSGA-II-based wrapper approach to feature selection which incorporates specialized sampling, mutation and recombination operators. Both methods make use of parameterized filter ensembles. While model-based optimization needs fewer objective evaluations to achieve good performance, it incurs computational overhead compared to the NSGA-II, so the preferred choice depends on the cost of evaluating a model on given data.