 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Probabilistic Neural Twin for Treatment Planning in Peripheral Pulmonary Artery Stenosis
Dec 01, 2023The substantial computational cost of high-fidelity models in numerical hemodynamics has, so far, relegated their use mainly to offline treatment planning. New breakthroughs in data-driven architectures and optimization techniques for fast surrogate modeling provide an exciting opportunity to overcome these limitations, enabling the use of such technology for time-critical decisions. We discuss an application to the repair of multiple stenosis in peripheral pulmonary artery disease through either transcatheter pulmonary artery rehabilitation or surgery, where it is of interest to achieve desired pressures and flows at specific locations in the pulmonary artery tree, while minimizing the risk for the patient. Since different degrees of success can be achieved in practice during treatment, we formulate the problem in probability, and solve it through a sample-based approach. We propose a new offline-online pipeline for probabilsitic real-time treatment planning which combines offline assimilation of boundary conditions, model reduction, and training dataset generation with online estimation of marginal probabilities, possibly conditioned on the degree of augmentation observed in already repaired lesions. Moreover, we propose a new approach for the parametrization of arbitrarily shaped vascular repairs through iterative corrections of a zero-dimensional approximant. We demonstrate this pipeline for a diseased model of the pulmonary artery tree available through the Vascular Model Repository.
Multi-Objective Hyperparameter Optimization -- An Overview
Jun 15, 2022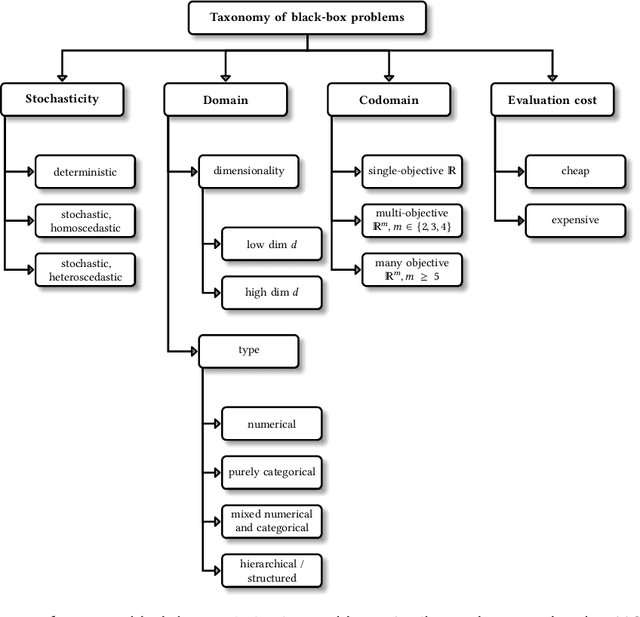

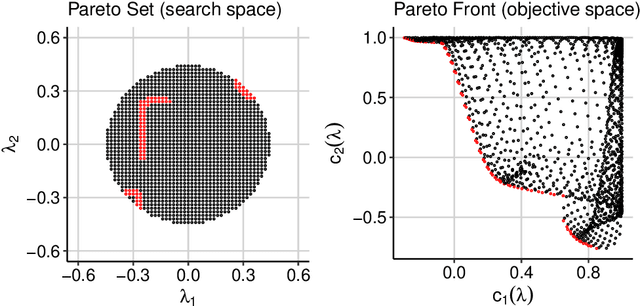
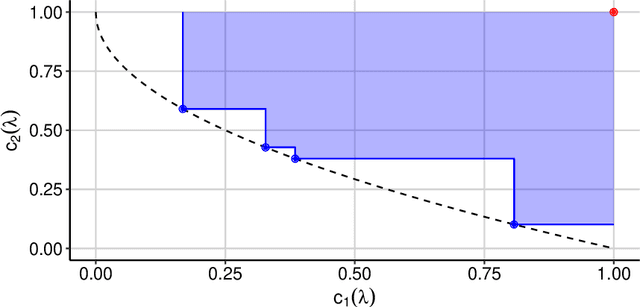
Hyperparameter optimization constitutes a large part of typical modern machine learning workflows. This arises from the fact that machine learning methods and corresponding preprocessing steps often only yield optimal performance when hyperparameters are properly tuned. But in many applications, we are not only interested in optimizing ML pipelines solely for predictive accuracy; additional metrics or constraints must be considered when determining an optimal configuration, resulting in a multi-objective optimization problem. This is often neglected in practice, due to a lack of knowledge and readily available software implementations for multi-objective hyperparameter optimization. In this work, we introduce the reader to the basics of multi- objective hyperparameter optimization and motivate its usefulness in applied ML. Furthermore, we provide an extensive survey of existing optimization strategies, both from the domain of evolutionary algorithms and Bayesian optimization. We illustrate the utility of MOO in several specific ML applications, considering objectives such as operating conditions, prediction time, sparseness, fairness, interpretability and robustness.
Hyperparameter Optimization: Foundations, Algorithms, Best Practices and Open Challenges
Jul 14, 2021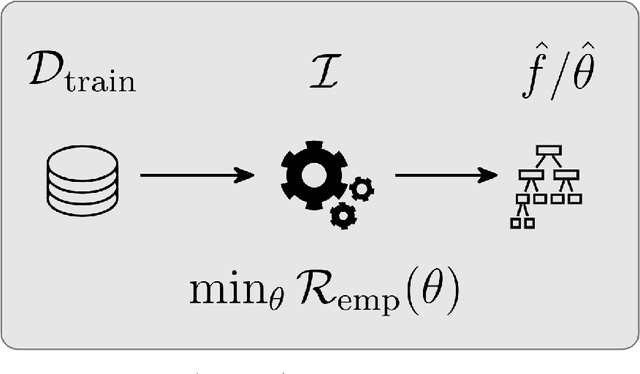
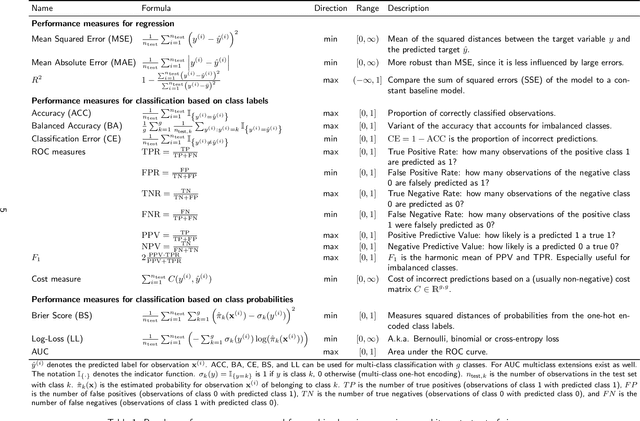
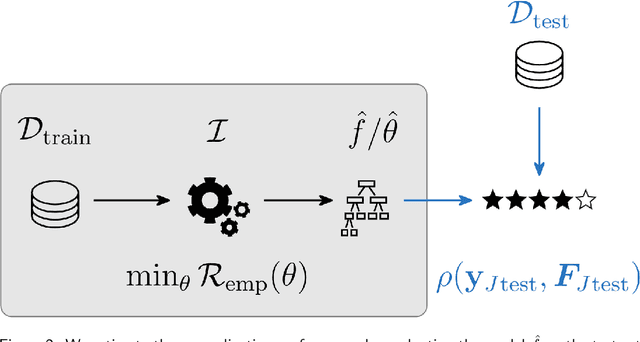
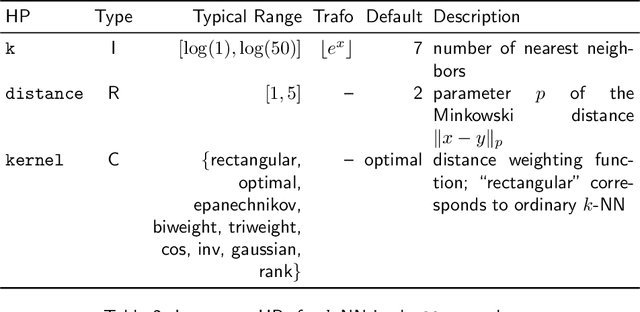
Most machine learning algorithms are configured by one or several hyperparameters that must be carefully chosen and often considerably impact performance. To avoid a time consuming and unreproducible manual trial-and-error process to find well-performing hyperparameter configurations, various automatic hyperparameter optimization (HPO) methods, e.g., based on resampling error estimation for supervised machine learning, can be employed. After introducing HPO from a general perspective, this paper reviews important HPO methods such as grid or random search, evolutionary algorithms, Bayesian optimization, Hyperband and racing. It gives practical recommendations regarding important choices to be made when conducting HPO, including the HPO algorithms themselves, performance evaluation, how to combine HPO with ML pipelines, runtime improvements, and parallelization.
Performance evaluation and hyperparameter tuning of statistical and machine-learning models using spatial data
Mar 29, 2018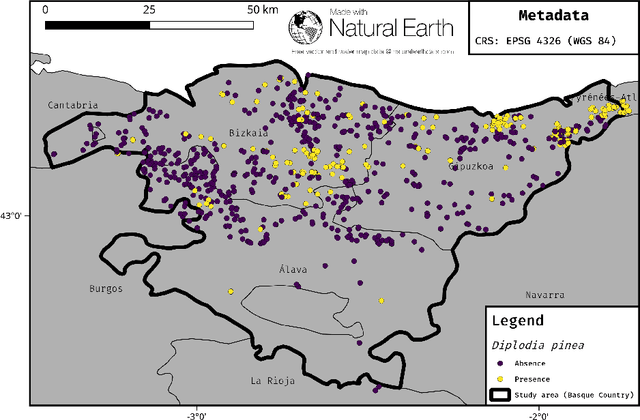
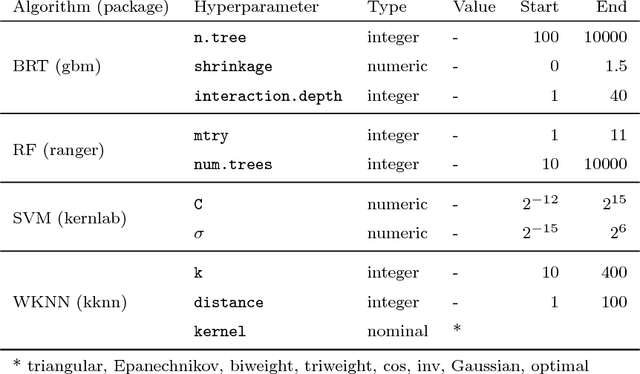
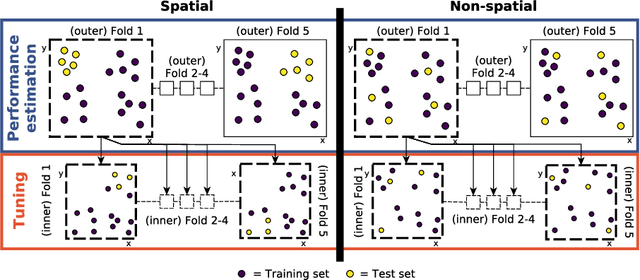
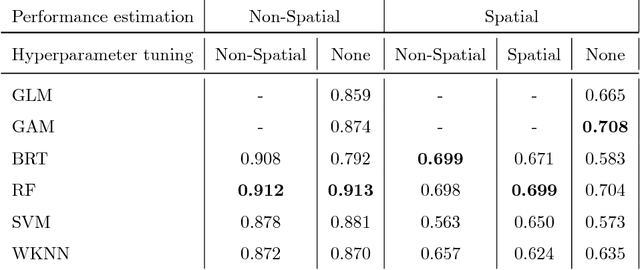
Machine-learning algorithms have gained popularity in recent years in the field of ecological modeling due to their promising results in predictive performance of classification problems. While the application of such algorithms has been highly simplified in the last years due to their well-documented integration in commonly used statistical programming languages such as R, there are several practical challenges in the field of ecological modeling related to unbiased performance estimation, optimization of algorithms using hyperparameter tuning and spatial autocorrelation. We address these issues in the comparison of several widely used machine-learning algorithms such as Boosted Regression Trees (BRT), k-Nearest Neighbor (WKNN), Random Forest (RF) and Support Vector Machine (SVM) to traditional parametric algorithms such as logistic regression (GLM) and semi-parametric ones like generalized additive models (GAM). Different nested cross-validation methods including hyperparameter tuning methods are used to evaluate model performances with the aim to receive bias-reduced performance estimates. As a case study the spatial distribution of forest disease Diplodia sapinea in the Basque Country in Spain is investigated using common environmental variables such as temperature, precipitation, soil or lithology as predictors. Results show that GAM and RF (mean AUROC estimates 0.708 and 0.699) outperform all other methods in predictive accuracy. The effect of hyperparameter tuning saturates at around 50 iterations for this data set. The AUROC differences between the bias-reduced (spatial cross-validation) and overoptimistic (non-spatial cross-validation) performance estimates of the GAM and RF are 0.167 (24%) and 0.213 (30%), respectively. It is recommended to also use spatial partitioning for cross-validation hyperparameter tuning of spatial data.
mlrMBO: A Modular Framework for Model-Based Optimization of Expensive Black-Box Functions
Mar 15, 2017
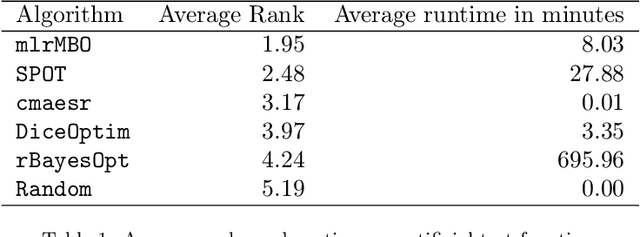
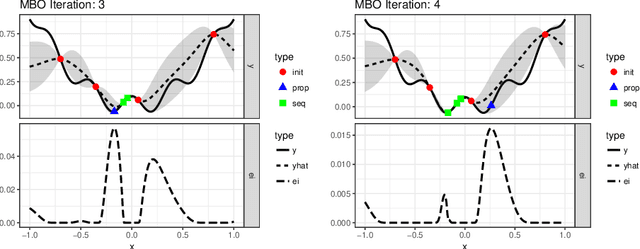

We present mlrMBO, a flexible and comprehensive R toolbox for model-based optimization (MBO), also known as Bayesian optimization, which addresses the problem of expensive black-box optimization by approximating the given objective function through a surrogate regression model. It is designed for both single- and multi-objective optimization with mixed continuous, categorical and conditional parameters. Additional features include multi-point batch proposal, parallelization, visualization, logging and error-handling. mlrMBO is implemented in a modular fashion, such that single components can be easily replaced or adapted by the user for specific use cases, e.g., any regression learner from the mlr toolbox for machine learning can be used, and infill criteria and infill optimizers are easily exchangeable. We empirically demonstrate that mlrMBO provides state-of-the-art performance by comparing it on different benchmark scenarios against a wide range of other optimizers, including DiceOptim, rBayesianOptimization, SPOT, SMAC, Spearmint, and Hyperopt.
mlr Tutorial
Sep 18, 2016This document provides and in-depth introduction to the mlr framework for machine learning experiments in R.