 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb scraping: a promising tool for geographic data acquisition
May 31, 2023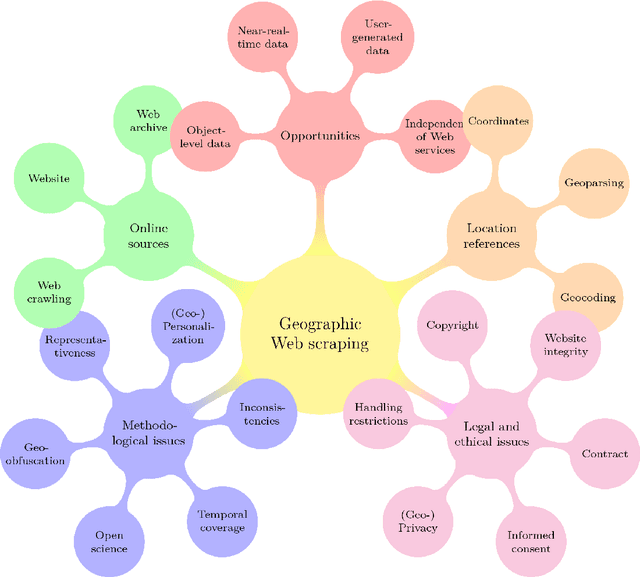
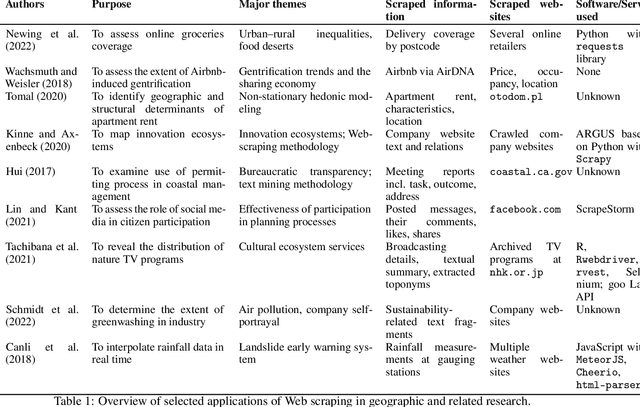
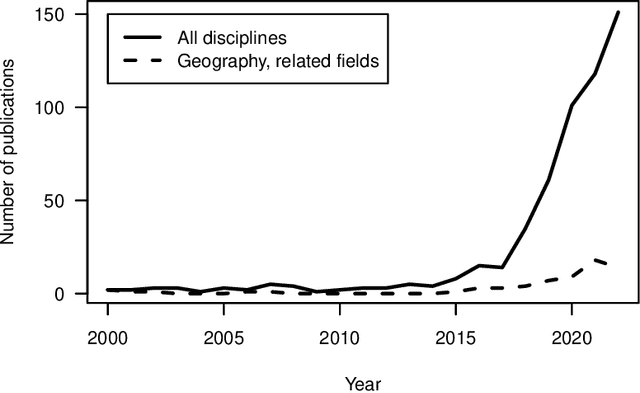
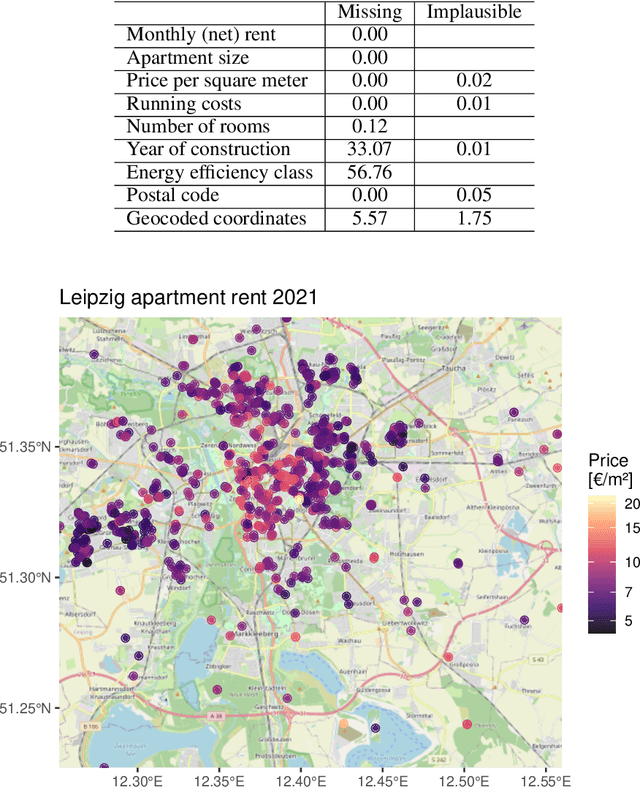
With much of our lives taking place online, researchers are increasingly turning to information from the World Wide Web to gain insights into geographic patterns and processes. Web scraping as an online data acquisition technique allows us to gather intelligence especially on social and economic actions for which the Web serves as a platform. Specific opportunities relate to near-real-time access to object-level geolocated data, which can be captured in a cost-effective way. The studied geographic phenomena include, but are not limited to, the rental market and associated processes such as gentrification, entrepreneurial ecosystems, or spatial planning processes. Since the information retrieved from the Web is not made available for that purpose, Web scraping faces several unique challenges, several of which relate to location. Ethical and legal issues mainly relate to intellectual property rights, informed consent and (geo-) privacy, and website integrity and contract. These issues also effect the practice of open science. In addition, there are technical and statistical challenges that relate to dependability and incompleteness, data inconsistencies and bias, as well as the limited historical coverage. Geospatial analyses furthermore usually require the automated extraction and subsequent resolution of toponyms or addresses (geoparsing, geocoding). A study on apartment rent in Leipzig, Germany is used to illustrate the use of Web scraping and its challenges. We conclude that geographic researchers should embrace Web scraping as a powerful and affordable digital fieldwork tool while paying special attention to its legal, ethical, and methodological challenges.
Spatial machine-learning model diagnostics: a model-agnostic distance-based approach
Nov 13, 2021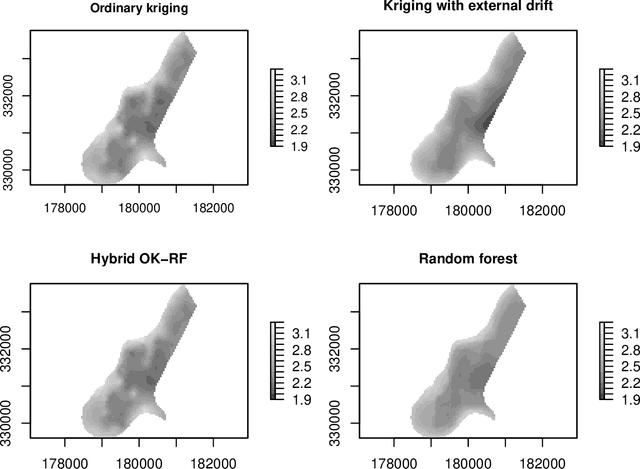
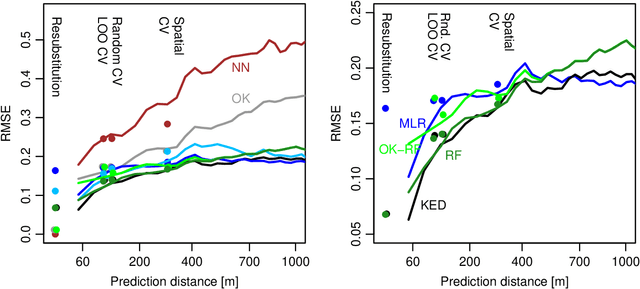
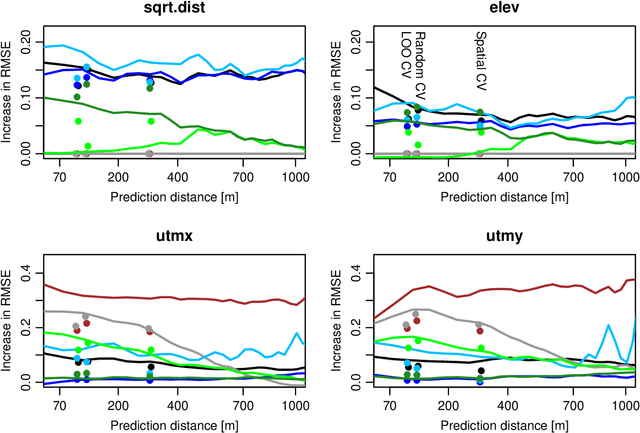
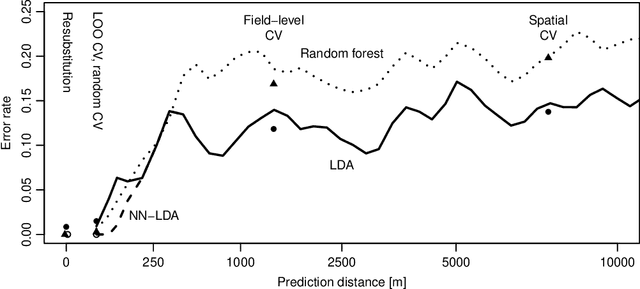
While significant progress has been made towards explaining black-box machine-learning (ML) models, there is still a distinct lack of diagnostic tools that elucidate the spatial behaviour of ML models in terms of predictive skill and variable importance. This contribution proposes spatial prediction error profiles (SPEPs) and spatial variable importance profiles (SVIPs) as novel model-agnostic assessment and interpretation tools for spatial prediction models with a focus on prediction distance. Their suitability is demonstrated in two case studies representing a regionalization task in an environmental-science context, and a classification task from remotely-sensed land cover classification. In these case studies, the SPEPs and SVIPs of geostatistical methods, linear models, random forest, and hybrid algorithms show striking differences but also relevant similarities. Limitations of related cross-validation techniques are outlined, and the case is made that modelers should focus their model assessment and interpretation on the intended spatial prediction horizon. The range of autocorrelation, in contrast, is not a suitable criterion for defining spatial cross-validation test sets. The novel diagnostic tools enrich the toolkit of spatial data science, and may improve ML model interpretation, selection, and design.
Mlr3spatiotempcv: Spatiotemporal resampling methods for machine learning in R
Oct 25, 2021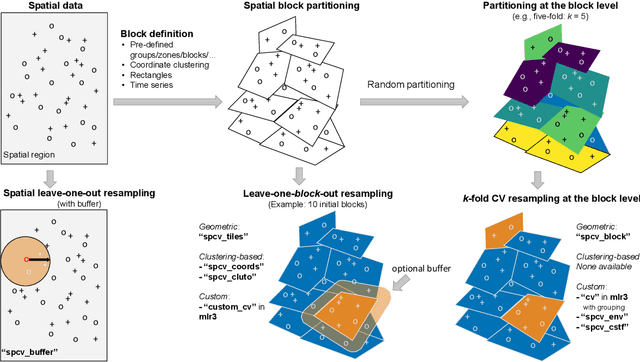
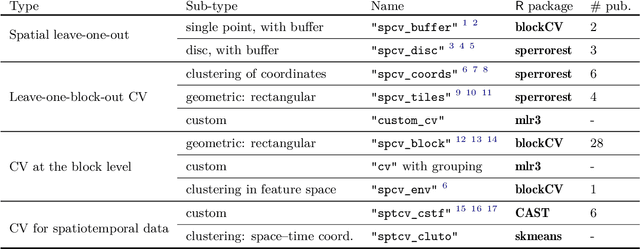
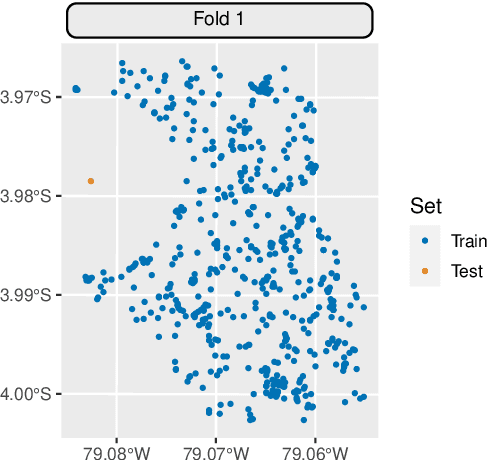
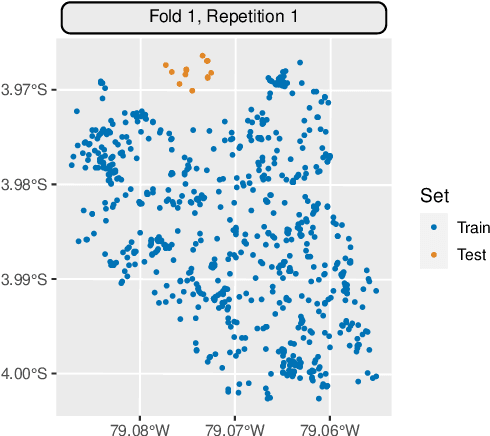
Spatial and spatiotemporal machine-learning models require a suitable framework for their model assessment, model selection, and hyperparameter tuning, in order to avoid error estimation bias and over-fitting. This contribution reviews the state-of-the-art in spatial and spatiotemporal CV, and introduces the \proglang{R} package mlr3spatiotempcv as an extension package of the machine-learning framework \textbf{mlr3}. Currently various \proglang{R} packages implementing different spatiotemporal partitioning strategies exist: \pkg{blockCV}, \pkg{CAST}, \pkg{kmeans} and \pkg{sperrorest}. The goal of \pkg{mlr3spatiotempcv} is to gather the available spatiotemporal resampling methods in \proglang{R} and make them available to users through a simple and common interface. This is made possible by integrating the package directly into the \pkg{mlr3} machine-learning framework, which already has support for generic non-spatiotemporal resampling methods such as random partitioning. One advantage is the use of a consistent nomenclature in an overarching machine-learning toolkit instead of a varying package-specific syntax, making it easier for users to choose from a variety of spatiotemporal resampling methods. This package avoids giving recommendations which method to use in practice as this decision depends on the predictive task at hand, the autocorrelation within the data, and the spatial structure of the sampling design or geographic objects being studied.
Transforming Feature Space to Interpret Machine Learning Models
Apr 09, 2021
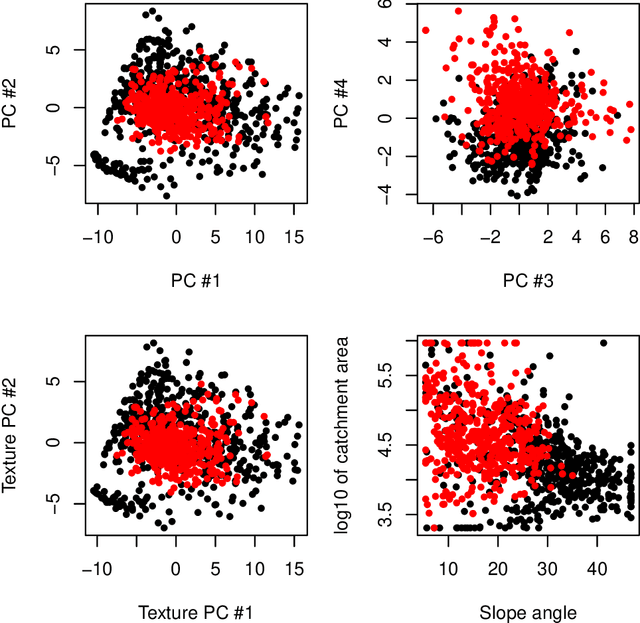
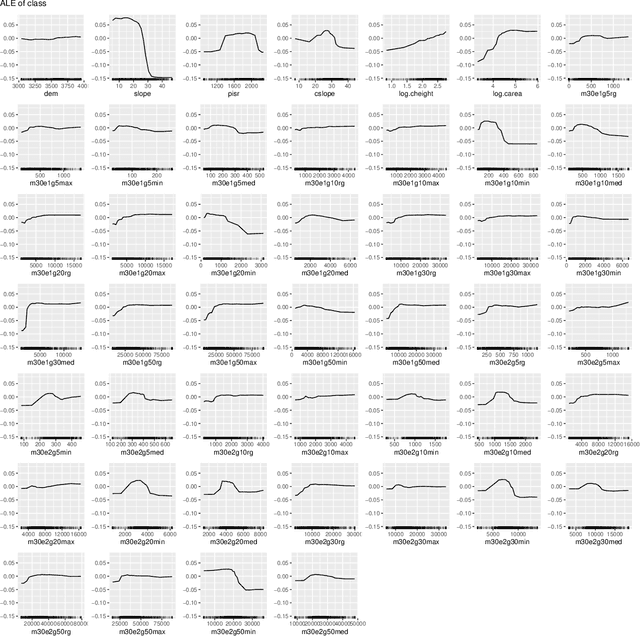
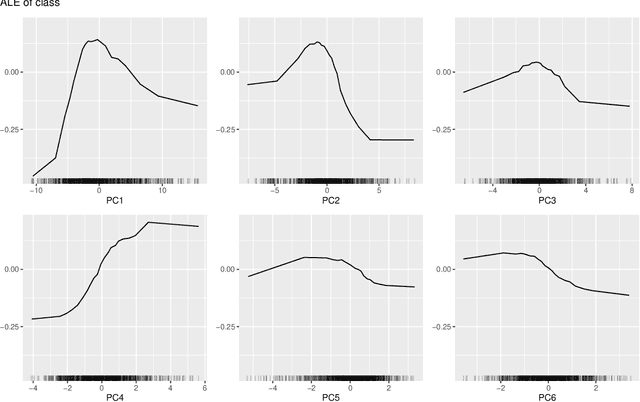
Model-agnostic tools for interpreting machine-learning models struggle to summarize the joint effects of strongly dependent features in high-dimensional feature spaces, which play an important role in pattern recognition, for example in remote sensing of landcover. This contribution proposes a novel approach that interprets machine-learning models through the lens of feature space transformations. It can be used to enhance unconditional as well as conditional post-hoc diagnostic tools including partial dependence plots, accumulated local effects plots, or permutation feature importance assessments. While the approach can also be applied to nonlinear transformations, we focus on linear ones, including principal component analysis (PCA) and a partial orthogonalization technique. Structured PCA and diagnostics along paths offer opportunities for representing domain knowledge. The new approach is implemented in the R package `wiml`, which can be combined with existing explainable machine-learning packages. A case study on remote-sensing landcover classification with 46 features is used to demonstrate the potential of the proposed approach for model interpretation by domain experts.
Performance evaluation and hyperparameter tuning of statistical and machine-learning models using spatial data
Mar 29, 2018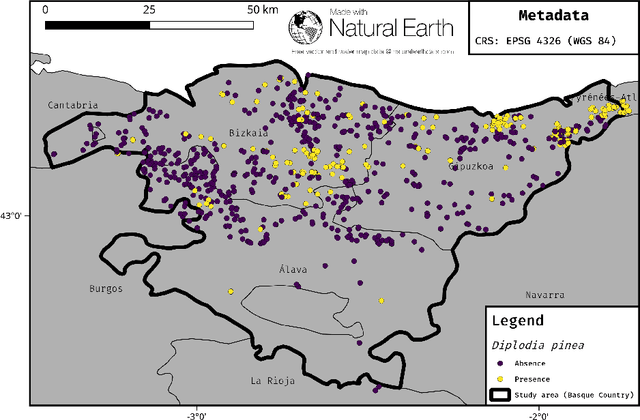
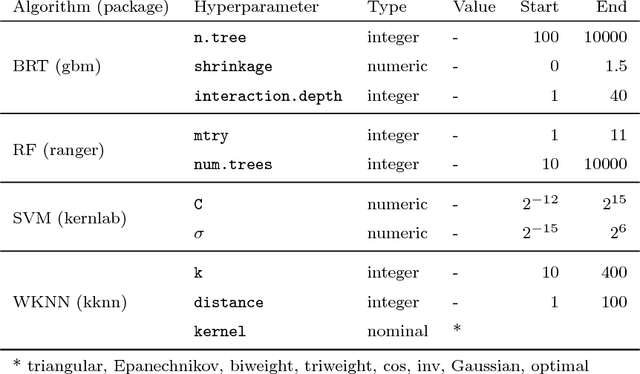
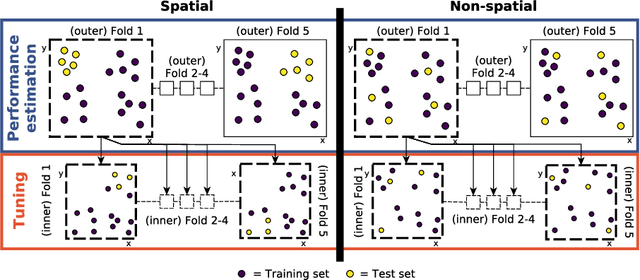
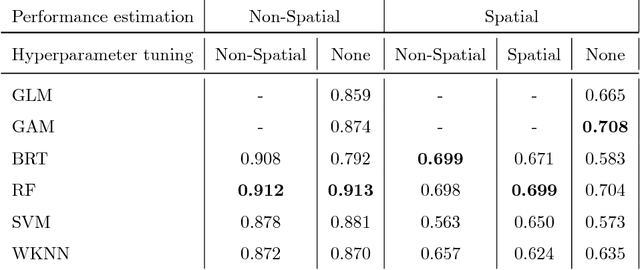
Machine-learning algorithms have gained popularity in recent years in the field of ecological modeling due to their promising results in predictive performance of classification problems. While the application of such algorithms has been highly simplified in the last years due to their well-documented integration in commonly used statistical programming languages such as R, there are several practical challenges in the field of ecological modeling related to unbiased performance estimation, optimization of algorithms using hyperparameter tuning and spatial autocorrelation. We address these issues in the comparison of several widely used machine-learning algorithms such as Boosted Regression Trees (BRT), k-Nearest Neighbor (WKNN), Random Forest (RF) and Support Vector Machine (SVM) to traditional parametric algorithms such as logistic regression (GLM) and semi-parametric ones like generalized additive models (GAM). Different nested cross-validation methods including hyperparameter tuning methods are used to evaluate model performances with the aim to receive bias-reduced performance estimates. As a case study the spatial distribution of forest disease Diplodia sapinea in the Basque Country in Spain is investigated using common environmental variables such as temperature, precipitation, soil or lithology as predictors. Results show that GAM and RF (mean AUROC estimates 0.708 and 0.699) outperform all other methods in predictive accuracy. The effect of hyperparameter tuning saturates at around 50 iterations for this data set. The AUROC differences between the bias-reduced (spatial cross-validation) and overoptimistic (non-spatial cross-validation) performance estimates of the GAM and RF are 0.167 (24%) and 0.213 (30%), respectively. It is recommended to also use spatial partitioning for cross-validation hyperparameter tuning of spatial data.