 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR-Sieve Bootstrap for the Random Forest and a simulation-based comparison with rangerts time series prediction
Oct 01, 2024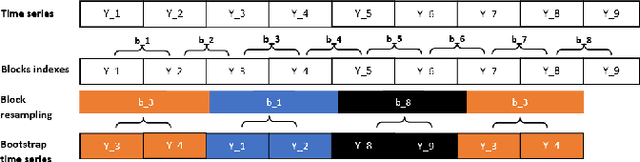
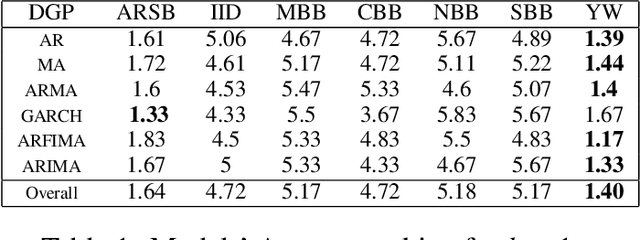
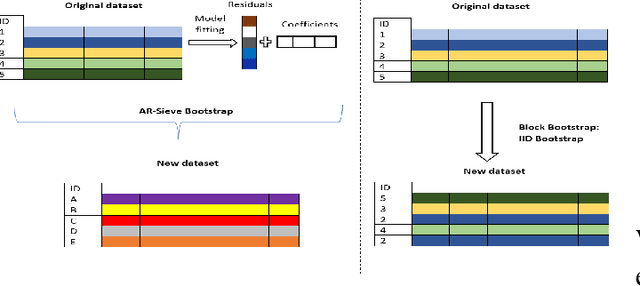
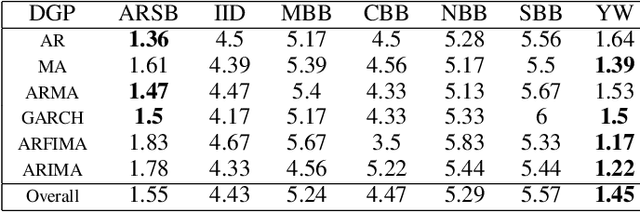
The Random Forest (RF) algorithm can be applied to a broad spectrum of problems, including time series prediction. However, neither the classical IID (Independent and Identically distributed) bootstrap nor block bootstrapping strategies (as implemented in rangerts) completely account for the nature of the Data Generating Process (DGP) while resampling the observations. We propose the combination of RF with a residual bootstrapping technique where we replace the IID bootstrap with the AR-Sieve Bootstrap (ARSB), which assumes the DGP to be an autoregressive process. To assess the new model's predictive performance, we conduct a simulation study using synthetic data generated from different types of DGPs. It turns out that ARSB provides more variation amongst the trees in the forest. Moreover, RF with ARSB shows greater accuracy compared to RF with other bootstrap strategies. However, these improvements are achieved at some efficiency costs.
TREE: Tree Regularization for Efficient Execution
Jun 18, 2024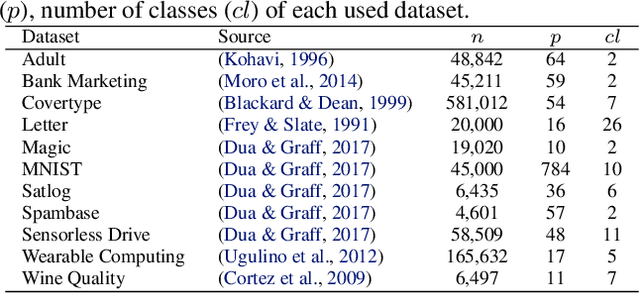
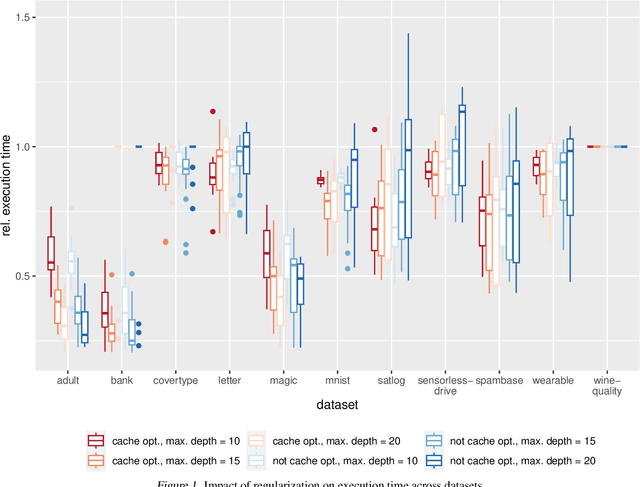
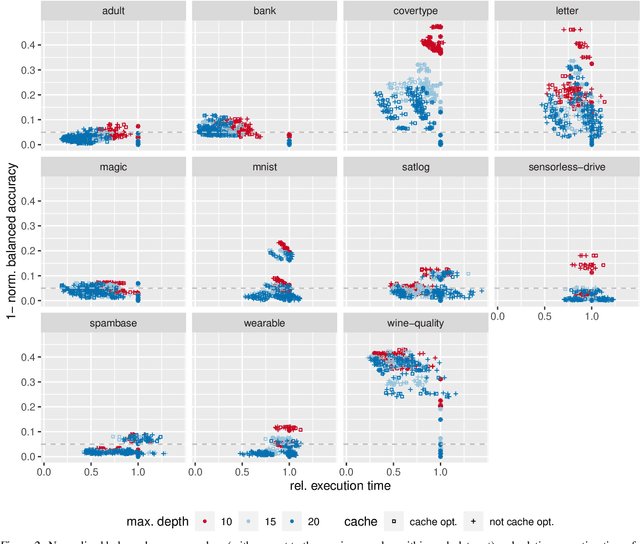

The rise of machine learning methods on heavily resource constrained devices requires not only the choice of a suitable model architecture for the target platform, but also the optimization of the chosen model with regard to execution time consumption for inference in order to optimally utilize the available resources. Random forests and decision trees are shown to be a suitable model for such a scenario, since they are not only heavily tunable towards the total model size, but also offer a high potential for optimizing their executions according to the underlying memory architecture. In addition to the straightforward strategy of enforcing shorter paths through decision trees and hence reducing the execution time for inference, hardware-aware implementations can optimize the execution time in an orthogonal manner. One particular hardware-aware optimization is to layout the memory of decision trees in such a way, that higher probably paths are less likely to be evicted from system caches. This works particularly well when splits within tree nodes are uneven and have a high probability to visit one of the child nodes. In this paper, we present a method to reduce path lengths by rewarding uneven probability distributions during the training of decision trees at the cost of a minimal accuracy degradation. Specifically, we regularize the impurity computation of the CART algorithm in order to favor not only low impurity, but also highly asymmetric distributions for the evaluation of split criteria and hence offer a high optimization potential for a memory architecture-aware implementation. We show that especially for binary classification data sets and data sets with many samples, this form of regularization can lead to an reduction of up to approximately four times in the execution time with a minimal accuracy degradation.
Multi-Objective Hyperparameter Optimization -- An Overview
Jun 15, 2022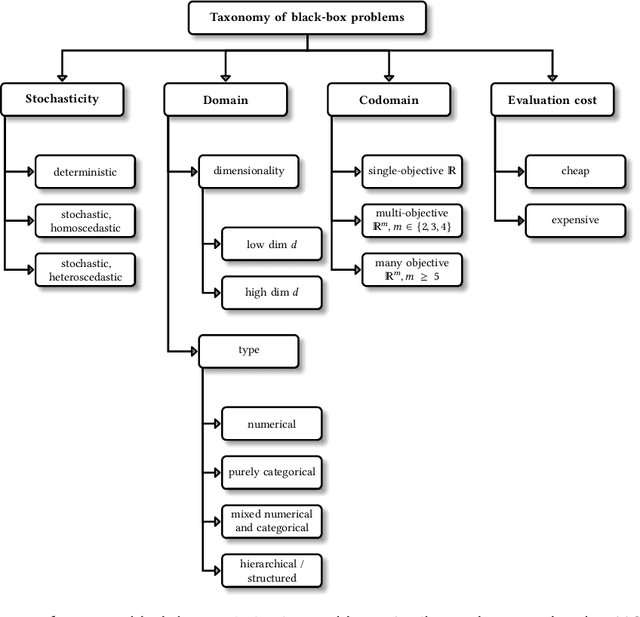

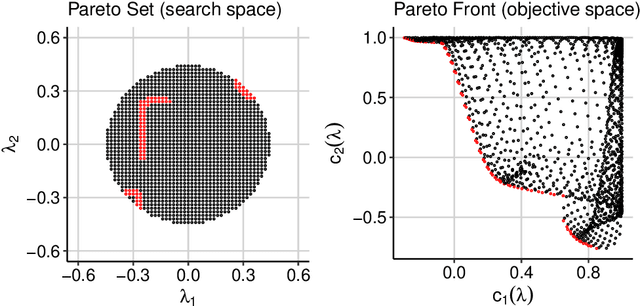
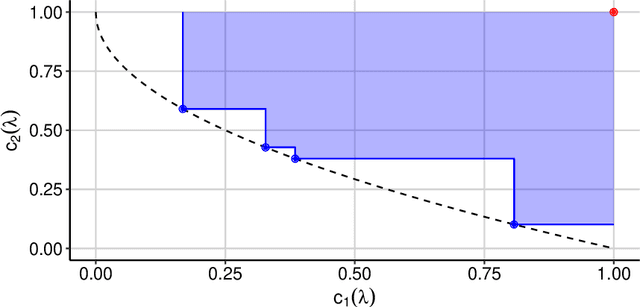
Hyperparameter optimization constitutes a large part of typical modern machine learning workflows. This arises from the fact that machine learning methods and corresponding preprocessing steps often only yield optimal performance when hyperparameters are properly tuned. But in many applications, we are not only interested in optimizing ML pipelines solely for predictive accuracy; additional metrics or constraints must be considered when determining an optimal configuration, resulting in a multi-objective optimization problem. This is often neglected in practice, due to a lack of knowledge and readily available software implementations for multi-objective hyperparameter optimization. In this work, we introduce the reader to the basics of multi- objective hyperparameter optimization and motivate its usefulness in applied ML. Furthermore, we provide an extensive survey of existing optimization strategies, both from the domain of evolutionary algorithms and Bayesian optimization. We illustrate the utility of MOO in several specific ML applications, considering objectives such as operating conditions, prediction time, sparseness, fairness, interpretability and robustness.
Automated Benchmark-Driven Design and Explanation of Hyperparameter Optimizers
Nov 29, 2021
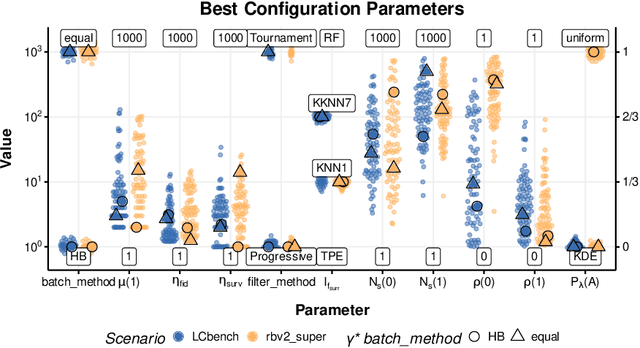

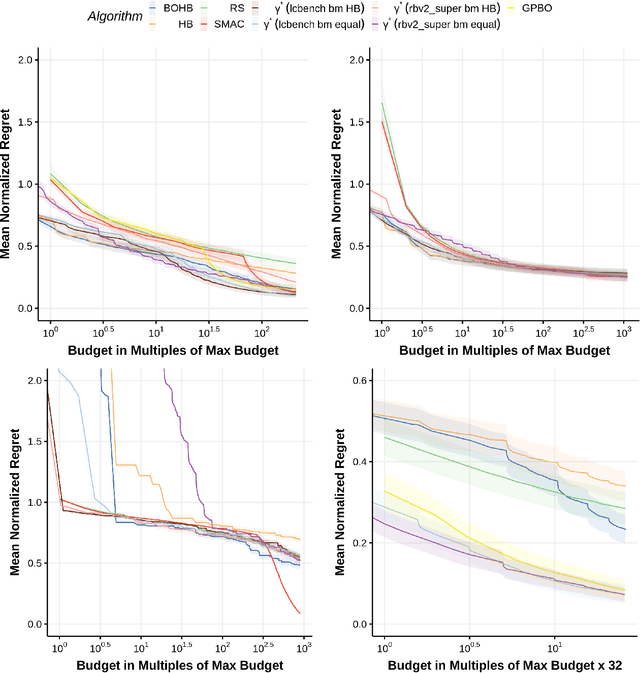
Automated hyperparameter optimization (HPO) has gained great popularity and is an important ingredient of most automated machine learning frameworks. The process of designing HPO algorithms, however, is still an unsystematic and manual process: Limitations of prior work are identified and the improvements proposed are -- even though guided by expert knowledge -- still somewhat arbitrary. This rarely allows for gaining a holistic understanding of which algorithmic components are driving performance, and carries the risk of overlooking good algorithmic design choices. We present a principled approach to automated benchmark-driven algorithm design applied to multifidelity HPO (MF-HPO): First, we formalize a rich space of MF-HPO candidates that includes, but is not limited to common HPO algorithms, and then present a configurable framework covering this space. To find the best candidate automatically and systematically, we follow a programming-by-optimization approach and search over the space of algorithm candidates via Bayesian optimization. We challenge whether the found design choices are necessary or could be replaced by more naive and simpler ones by performing an ablation analysis. We observe that using a relatively simple configuration, in some ways simpler than established methods, performs very well as long as some critical configuration parameters have the right value.
Mlr3spatiotempcv: Spatiotemporal resampling methods for machine learning in R
Oct 25, 2021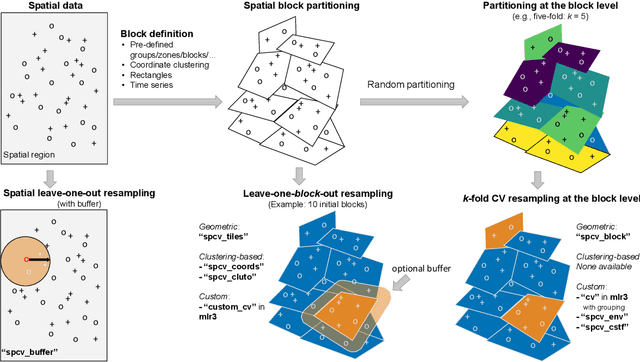
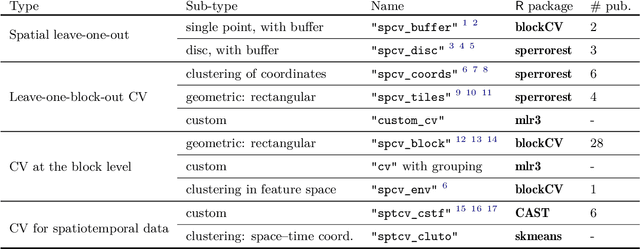
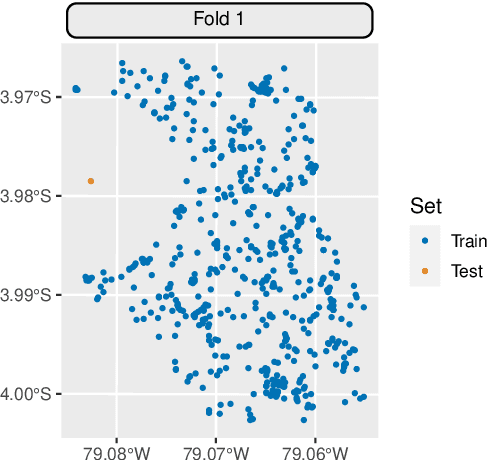
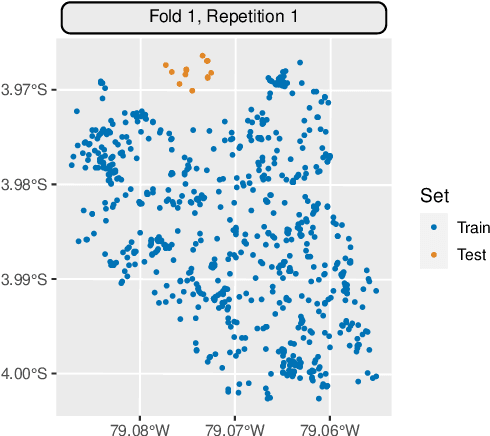
Spatial and spatiotemporal machine-learning models require a suitable framework for their model assessment, model selection, and hyperparameter tuning, in order to avoid error estimation bias and over-fitting. This contribution reviews the state-of-the-art in spatial and spatiotemporal CV, and introduces the \proglang{R} package mlr3spatiotempcv as an extension package of the machine-learning framework \textbf{mlr3}. Currently various \proglang{R} packages implementing different spatiotemporal partitioning strategies exist: \pkg{blockCV}, \pkg{CAST}, \pkg{kmeans} and \pkg{sperrorest}. The goal of \pkg{mlr3spatiotempcv} is to gather the available spatiotemporal resampling methods in \proglang{R} and make them available to users through a simple and common interface. This is made possible by integrating the package directly into the \pkg{mlr3} machine-learning framework, which already has support for generic non-spatiotemporal resampling methods such as random partitioning. One advantage is the use of a consistent nomenclature in an overarching machine-learning toolkit instead of a varying package-specific syntax, making it easier for users to choose from a variety of spatiotemporal resampling methods. This package avoids giving recommendations which method to use in practice as this decision depends on the predictive task at hand, the autocorrelation within the data, and the spatial structure of the sampling design or geographic objects being studied.
Hyperparameter Optimization: Foundations, Algorithms, Best Practices and Open Challenges
Jul 14, 2021
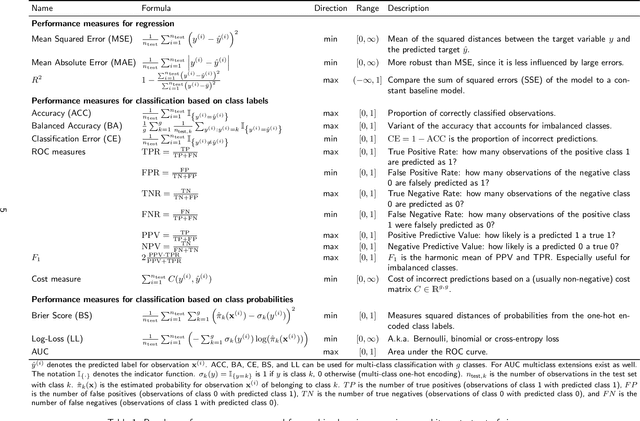
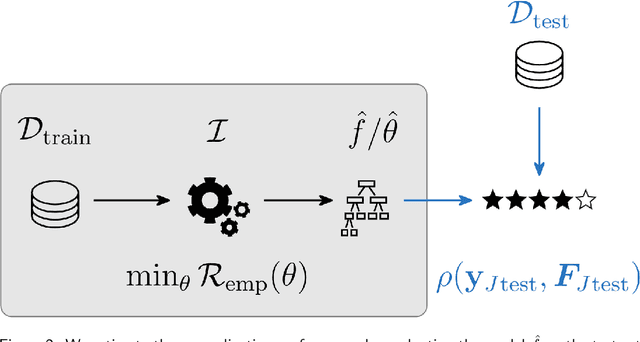
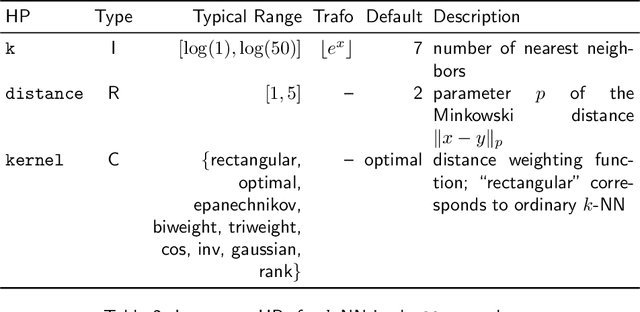
Most machine learning algorithms are configured by one or several hyperparameters that must be carefully chosen and often considerably impact performance. To avoid a time consuming and unreproducible manual trial-and-error process to find well-performing hyperparameter configurations, various automatic hyperparameter optimization (HPO) methods, e.g., based on resampling error estimation for supervised machine learning, can be employed. After introducing HPO from a general perspective, this paper reviews important HPO methods such as grid or random search, evolutionary algorithms, Bayesian optimization, Hyperband and racing. It gives practical recommendations regarding important choices to be made when conducting HPO, including the HPO algorithms themselves, performance evaluation, how to combine HPO with ML pipelines, runtime improvements, and parallelization.
Employing an Adjusted Stability Measure for Multi-Criteria Model Fitting on Data Sets with Similar Features
Jun 15, 2021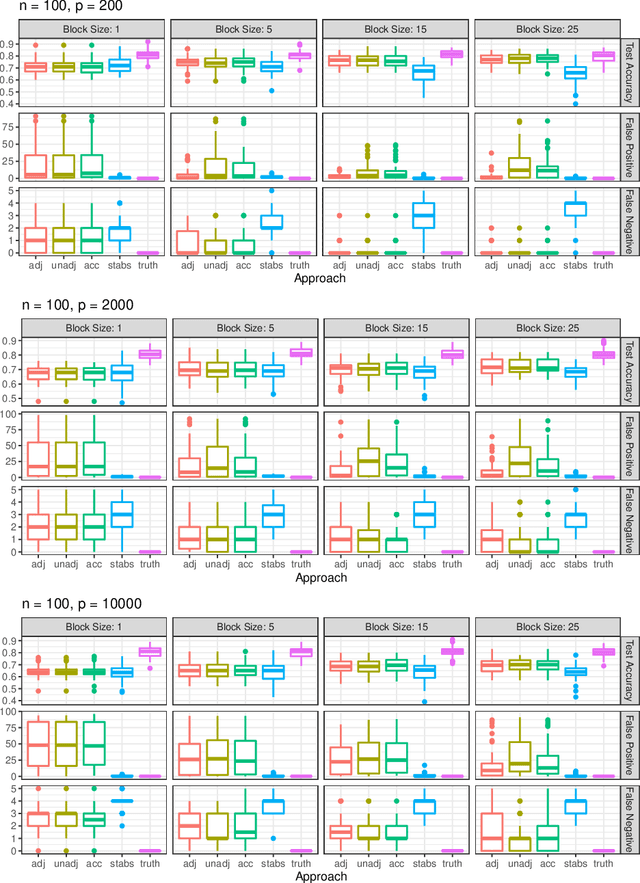
Fitting models with high predictive accuracy that include all relevant but no irrelevant or redundant features is a challenging task on data sets with similar (e.g. highly correlated) features. We propose the approach of tuning the hyperparameters of a predictive model in a multi-criteria fashion with respect to predictive accuracy and feature selection stability. We evaluate this approach based on both simulated and real data sets and we compare it to the standard approach of single-criteria tuning of the hyperparameters as well as to the state-of-the-art technique "stability selection". We conclude that our approach achieves the same or better predictive performance compared to the two established approaches. Considering the stability during tuning does not decrease the predictive accuracy of the resulting models. Our approach succeeds at selecting the relevant features while avoiding irrelevant or redundant features. The single-criteria approach fails at avoiding irrelevant or redundant features and the stability selection approach fails at selecting enough relevant features for achieving acceptable predictive accuracy. For our approach, for data sets with many similar features, the feature selection stability must be evaluated with an adjusted stability measure, that is, a measure that considers similarities between features. For data sets with only few similar features, an unadjusted stability measure suffices and is faster to compute.
mlr3proba: Machine Learning Survival Analysis in R
Aug 18, 2020As machine learning has become increasingly popular over the last few decades, so too has the number of machine learning interfaces for implementing these models. However, no consistent interface for evaluation and modelling of survival analysis has emerged despite its vital importance in many fields, including medicine, economics, and engineering. \texttt{mlr3proba} is part of the \texttt{mlr3} ecosystem of machine learning packages for R and facilitates \texttt{mlr3}'s general model tuning and benchmarking by providing a multitude of performance measures and learners for survival analysis with a clean and systematic infrastructure for their evaluation. \texttt{mlr3proba} provides a comprehensive machine learning interface for survival analysis, which allows survival modelling to finally be up to the state-of-art.
Feature Selection Methods for Cost-Constrained Classification in Random Forests
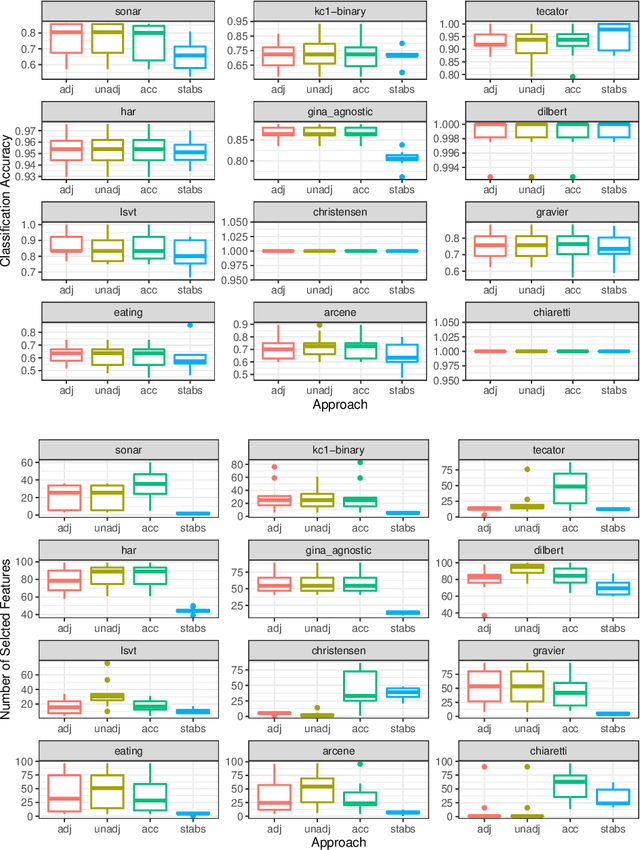
Aug 17, 2020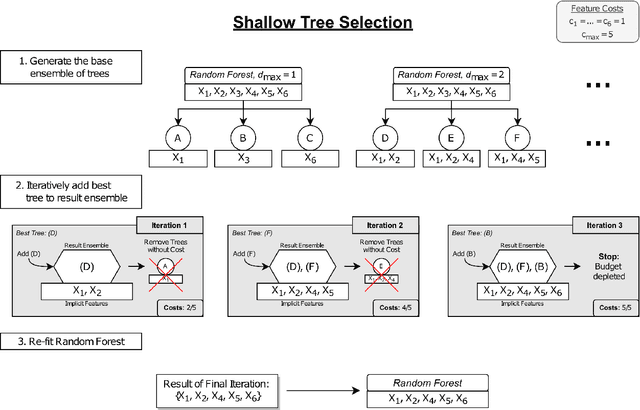

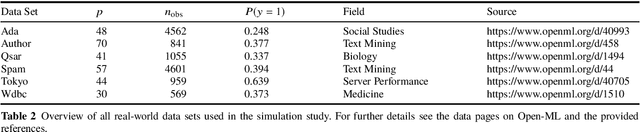
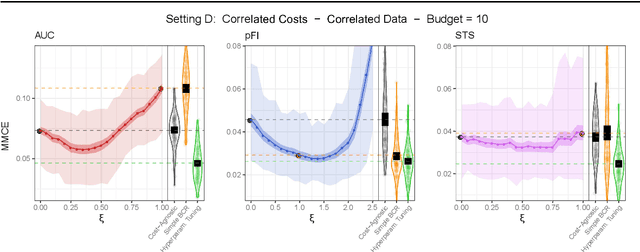
Cost-sensitive feature selection describes a feature selection problem, where features raise individual costs for inclusion in a model. These costs allow to incorporate disfavored aspects of features, e.g. failure rates of as measuring device, or patient harm, in the model selection process. Random Forests define a particularly challenging problem for feature selection, as features are generally entangled in an ensemble of multiple trees, which makes a post hoc removal of features infeasible. Feature selection methods therefore often either focus on simple pre-filtering methods, or require many Random Forest evaluations along their optimization path, which drastically increases the computational complexity. To solve both issues, we propose Shallow Tree Selection, a novel fast and multivariate feature selection method that selects features from small tree structures. Additionally, we also adapt three standard feature selection algorithms for cost-sensitive learning by introducing a hyperparameter-controlled benefit-cost ratio criterion (BCR) for each method. In an extensive simulation study, we assess this criterion, and compare the proposed methods to multiple performance-based baseline alternatives on four artificial data settings and seven real-world data settings. We show that all methods using a hyperparameterized BCR criterion outperform the baseline alternatives. In a direct comparison between the proposed methods, each method indicates strengths in certain settings, but no one-fits-all solution exists. On a global average, we could identify preferable choices among our BCR based methods. Nevertheless, we conclude that a practical analysis should never rely on a single method only, but always compare different approaches to obtain the best results.
High Dimensional Restrictive Federated Model Selection with multi-objective Bayesian Optimization over shifted distributions
Feb 24, 2019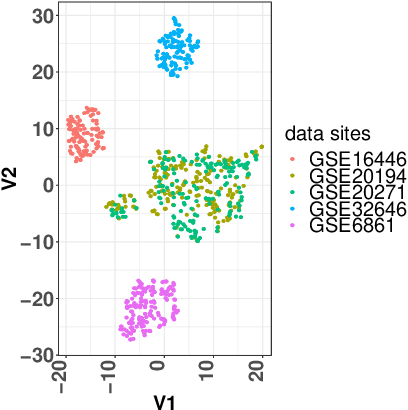
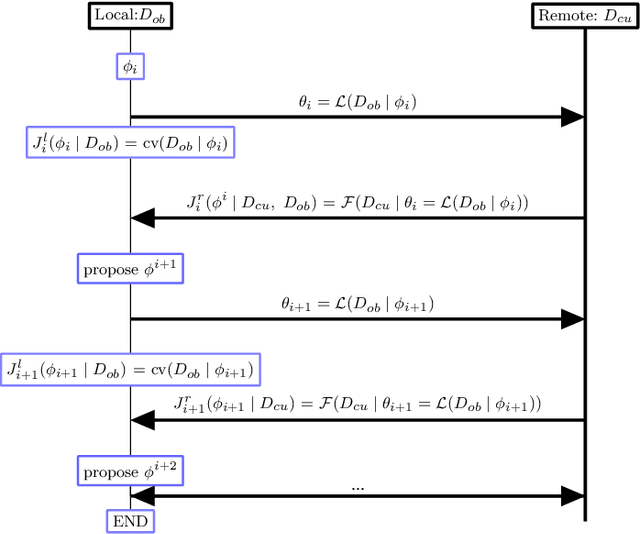

A novel machine learning optimization process coined Restrictive Federated Model Selection (RFMS) is proposed under the scenario, for example, when data from healthcare units can not leave the site it is situated on and it is forbidden to carry out training algorithms on remote data sites due to either technical or privacy and trust concerns. To carry out a clinical research under this scenario, an analyst could train a machine learning model only on local data site, but it is still possible to execute a statistical query at a certain cost in the form of sending a machine learning model to some of the remote data sites and get the performance measures as feedback, maybe due to prediction being usually much cheaper. Compared to federated learning, which is optimizing the model parameters directly by carrying out training across all data sites, RFMS trains model parameters only on one local data site but optimizes hyper-parameters across other data sites jointly since hyper-parameters play an important role in machine learning performance. The aim is to get a Pareto optimal model with respective to both local and remote unseen prediction losses, which could generalize well across data sites. In this work, we specifically consider high dimensional data with shifted distributions over data sites. As an initial investigation, Bayesian Optimization especially multi-objective Bayesian Optimization is used to guide an adaptive hyper-parameter optimization process to select models under the RFMS scenario. Empirical results show that solely using the local data site to tune hyper-parameters generalizes poorly across data sites, compared to methods that utilize the local and remote performances. Furthermore, in terms of dominated hypervolumes, multi-objective Bayesian Optimization algorithms show increased performance across multiple data sites among other candidates.