 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJump Like A Squirrel: Optimized Execution Step Order for Anytime Random Forest Inference
Mar 02, 2026Due to their efficiency and small size, decision trees and random forests are popular machine learning models used for classification on resource-constrained systems. In such systems, the available execution time for inference in a random forest might not be sufficient for a complete model execution. Ideally, the already gained prediction confidence should be retained. An anytime algorithm is designed to be able to be aborted anytime, while giving a result with an increasing quality over time. Previous approaches have realized random forests as anytime algorithms on the granularity of trees, stopping after some but not all trees of a forest have been executed. However, due to the way decision trees subdivide the sample space in every step, an increase in prediction quality is achieved with every additional step in one tree. In this paper, we realize decision trees and random forest as anytime algorithms on the granularity of single steps in trees. This approach opens a design space to define the step order in a forest, which has the potential to optimize the mean accuracy. We propose the Optimal Order, which finds a step order with a maximal mean accuracy in exponential runtime and the polynomial runtime heuristics Forward Squirrel Order and Backward Squirrel Order, which greedily maximize the accuracy for each additional step taken down and up the trees, respectively. Our evaluation shows, that the Backward Squirrel Order performs $\sim94\%$ as well as the Optimal Order and $\sim99\%$ as well as all other step orders.
TREE: Tree Regularization for Efficient Execution
Jun 18, 2024
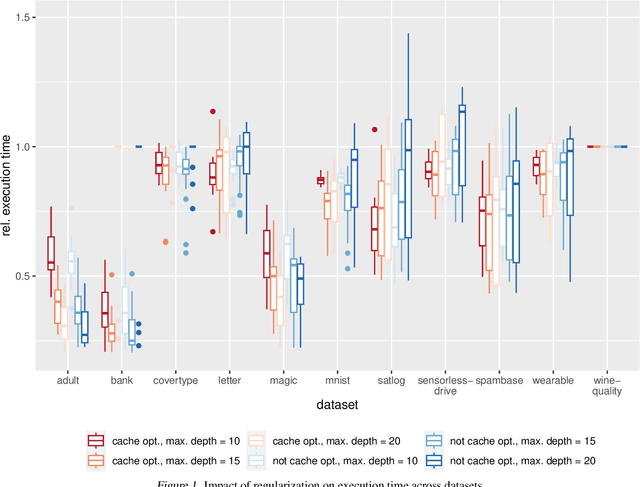
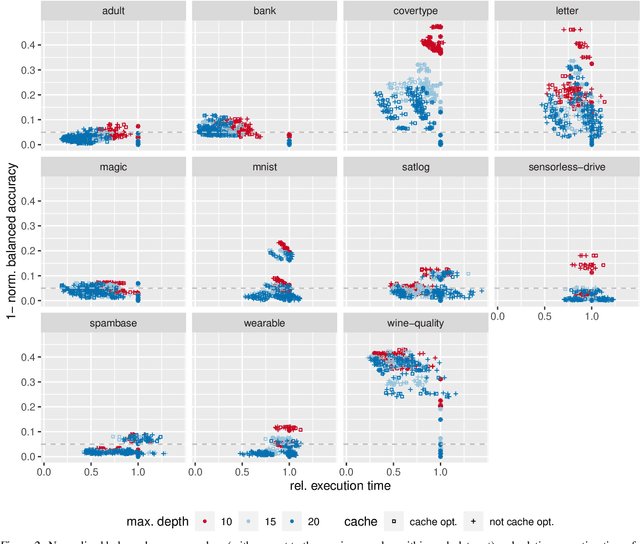

The rise of machine learning methods on heavily resource constrained devices requires not only the choice of a suitable model architecture for the target platform, but also the optimization of the chosen model with regard to execution time consumption for inference in order to optimally utilize the available resources. Random forests and decision trees are shown to be a suitable model for such a scenario, since they are not only heavily tunable towards the total model size, but also offer a high potential for optimizing their executions according to the underlying memory architecture. In addition to the straightforward strategy of enforcing shorter paths through decision trees and hence reducing the execution time for inference, hardware-aware implementations can optimize the execution time in an orthogonal manner. One particular hardware-aware optimization is to layout the memory of decision trees in such a way, that higher probably paths are less likely to be evicted from system caches. This works particularly well when splits within tree nodes are uneven and have a high probability to visit one of the child nodes. In this paper, we present a method to reduce path lengths by rewarding uneven probability distributions during the training of decision trees at the cost of a minimal accuracy degradation. Specifically, we regularize the impurity computation of the CART algorithm in order to favor not only low impurity, but also highly asymmetric distributions for the evaluation of split criteria and hence offer a high optimization potential for a memory architecture-aware implementation. We show that especially for binary classification data sets and data sets with many samples, this form of regularization can lead to an reduction of up to approximately four times in the execution time with a minimal accuracy degradation.
Register Your Forests: Decision Tree Ensemble Optimization by Explicit CPU Register Allocation
Apr 10, 2024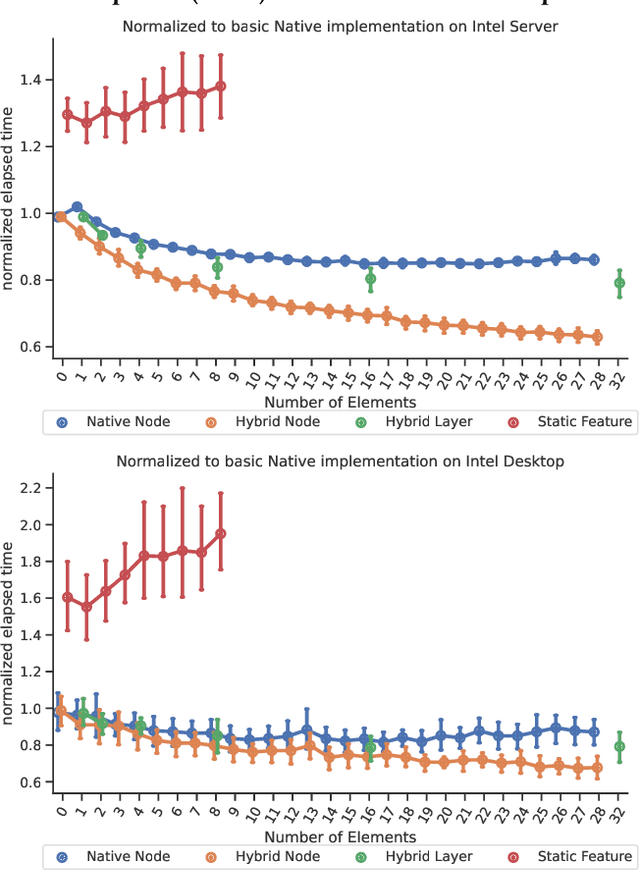
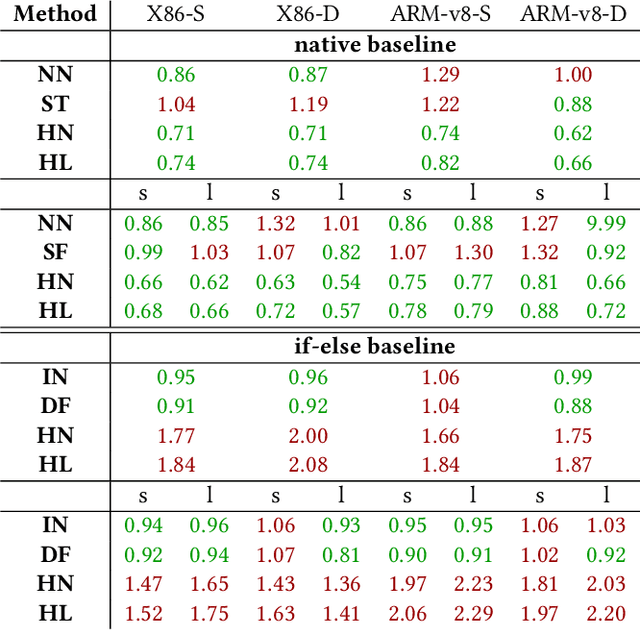

Bringing high-level machine learning models to efficient and well-suited machine implementations often invokes a bunch of tools, e.g.~code generators, compilers, and optimizers. Along such tool chains, abstractions have to be applied. This leads to not optimally used CPU registers. This is a shortcoming, especially in resource constrained embedded setups. In this work, we present a code generation approach for decision tree ensembles, which produces machine assembly code within a single conversion step directly from the high-level model representation. Specifically, we develop various approaches to effectively allocate registers for the inference of decision tree ensembles. Extensive evaluations of the proposed method are conducted in comparison to the basic realization of C code from the high-level machine learning model and succeeding compilation. The results show that the performance of decision tree ensemble inference can be significantly improved (by up to $\approx1.6\times$), if the methods are applied carefully to the appropriate scenario.