 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-Scale Neutral Comparison Study of Survival Models on Low-Dimensional Data
Jun 06, 2024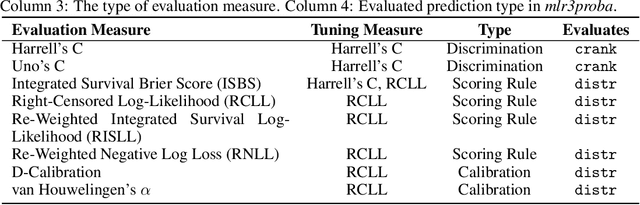

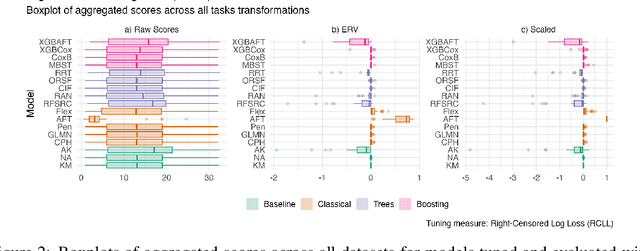
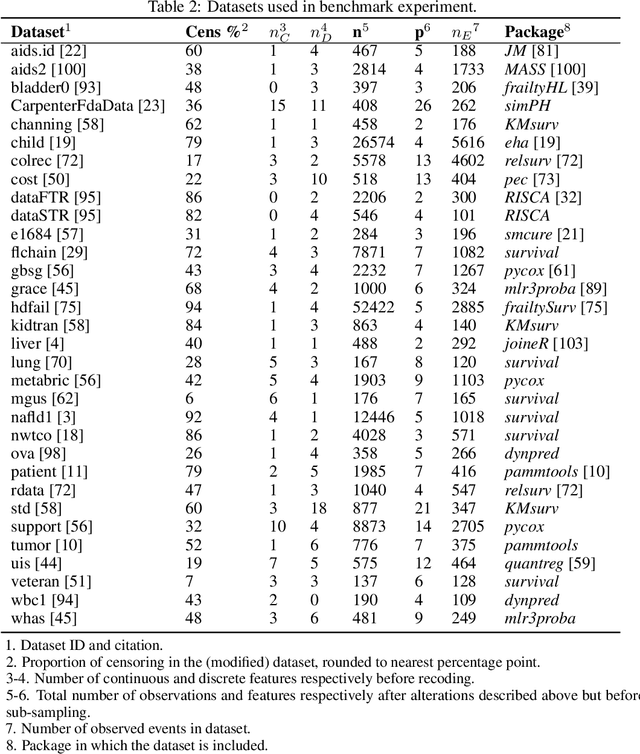
This work presents the first large-scale neutral benchmark experiment focused on single-event, right-censored, low-dimensional survival data. Benchmark experiments are essential in methodological research to scientifically compare new and existing model classes through proper empirical evaluation. Existing benchmarks in the survival literature are often narrow in scope, focusing, for example, on high-dimensional data. Additionally, they may lack appropriate tuning or evaluation procedures, or are qualitative reviews, rather than quantitative comparisons. This comprehensive study aims to fill the gap by neutrally evaluating a broad range of methods and providing generalizable conclusions. We benchmark 18 models, ranging from classical statistical approaches to many common machine learning methods, on 32 publicly available datasets. The benchmark tunes for both a discrimination measure and a proper scoring rule to assess performance in different settings. Evaluating on 8 survival metrics, we assess discrimination, calibration, and overall predictive performance of the tested models. Using discrimination measures, we find that no method significantly outperforms the Cox model. However, (tuned) Accelerated Failure Time models were able to achieve significantly better results with respect to overall predictive performance as measured by the right-censored log-likelihood. Machine learning methods that performed comparably well include Oblique Random Survival Forests under discrimination, and Cox-based likelihood-boosting under overall predictive performance. We conclude that for predictive purposes in the standard survival analysis setting of low-dimensional, right-censored data, the Cox Proportional Hazards model remains a simple and robust method, sufficient for practitioners.
Training Survival Models using Scoring Rules
Mar 19, 2024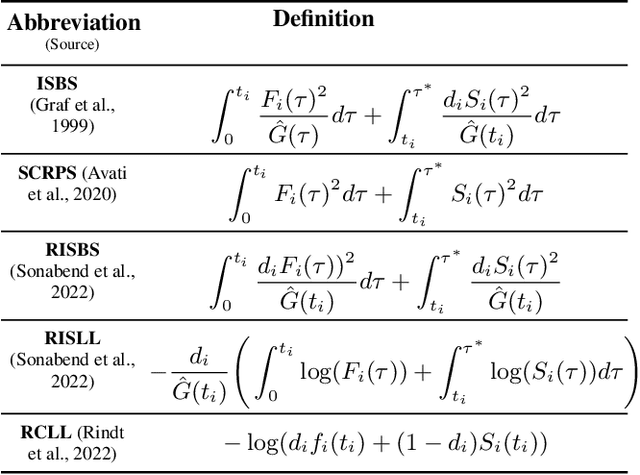



Survival Analysis provides critical insights for partially incomplete time-to-event data in various domains. It is also an important example of probabilistic machine learning. The probabilistic nature of the predictions can be exploited by using (proper) scoring rules in the model fitting process instead of likelihood-based optimization. Our proposal does so in a generic manner and can be used for a variety of model classes. We establish different parametric and non-parametric sub-frameworks that allow different degrees of flexibility. Incorporated into neural networks, it leads to a computationally efficient and scalable optimization routine, yielding state-of-the-art predictive performance. Finally, we show that using our framework, we can recover various parametric models and demonstrate that optimization works equally well when compared to likelihood-based methods.
Deep Learning for Survival Analysis: A Review
May 24, 2023The influx of deep learning (DL) techniques into the field of survival analysis in recent years, coupled with the increasing availability of high-dimensional omics data and unstructured data like images or text, has led to substantial methodological progress; for instance, learning from such high-dimensional or unstructured data. Numerous modern DL-based survival methods have been developed since the mid-2010s; however, they often address only a small subset of scenarios in the time-to-event data setting - e.g., single-risk right-censored survival tasks - and neglect to incorporate more complex (and common) settings. Partially, this is due to a lack of exchange between experts in the respective fields. In this work, we provide a comprehensive systematic review of DL-based methods for time-to-event analysis, characterizing them according to both survival- and DL-related attributes. In doing so, we hope to provide a helpful overview to practitioners who are interested in DL techniques applicable to their specific use case as well as to enable researchers from both fields to identify directions for future investigation. We provide a detailed characterization of the methods included in this review as an open-source, interactive table: https://survival-org.github.io/DL4Survival. As this research area is advancing rapidly, we encourage the research community to contribute to keeping the information up to date.
Scoring rules in survival analysis
Dec 10, 2022Scoring rules promote rational and good decision making and predictions by models, this is increasingly important for automated procedures of `auto-ML'. The Brier score and Log loss are well-established scoring rules for classification and regression and possess the `strict properness' property that encourages optimal predictions. In this paper we survey proposed scoring rules for survival analysis, establish the first clear definition of `(strict) properness' for survival scoring rules, and determine which losses are proper and improper. We prove that commonly utilised scoring rules that are claimed to be proper are in fact improper. We further prove that under a strict set of assumptions a class of scoring rules is strictly proper for, what we term, `approximate' survival losses. We hope these findings encourage further research into robust validation of survival models and promote honest evaluation.
Flexible Group Fairness Metrics for Survival Analysis
May 26, 2022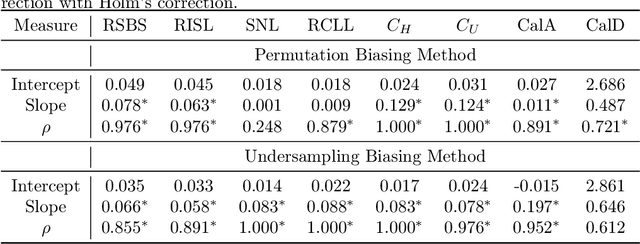
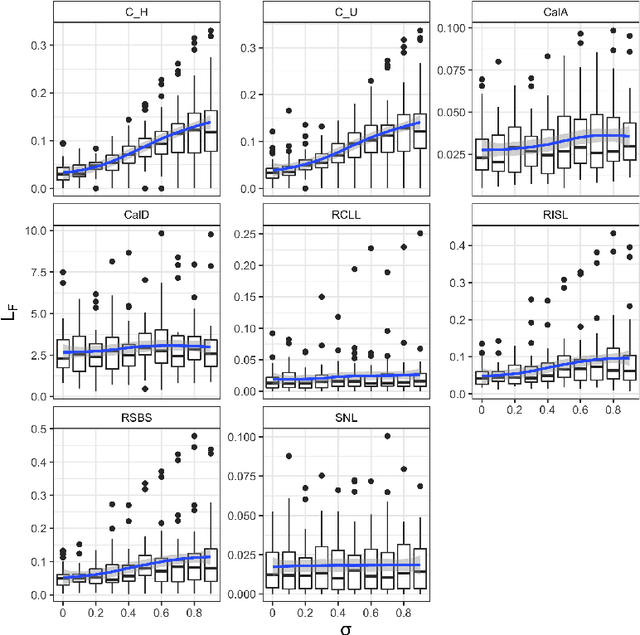
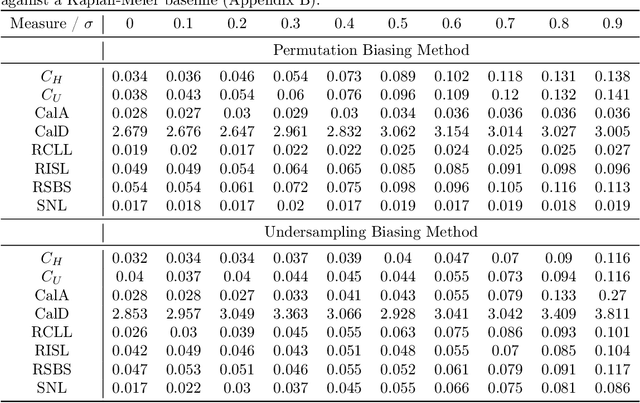
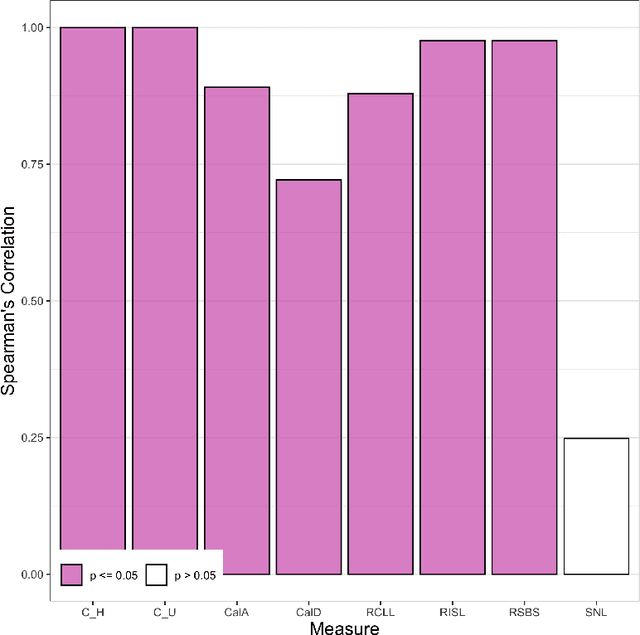
Algorithmic fairness is an increasingly important field concerned with detecting and mitigating biases in machine learning models. There has been a wealth of literature for algorithmic fairness in regression and classification however there has been little exploration of the field for survival analysis. Survival analysis is the prediction task in which one attempts to predict the probability of an event occurring over time. Survival predictions are particularly important in sensitive settings such as when utilising machine learning for diagnosis and prognosis of patients. In this paper we explore how to utilise existing survival metrics to measure bias with group fairness metrics. We explore this in an empirical experiment with 29 survival datasets and 8 measures. We find that measures of discrimination are able to capture bias well whereas there is less clarity with measures of calibration and scoring rules. We suggest further areas for research including prediction-based fairness metrics for distribution predictions.
Evaluation of survival distribution predictions with discrimination measures
Dec 09, 2021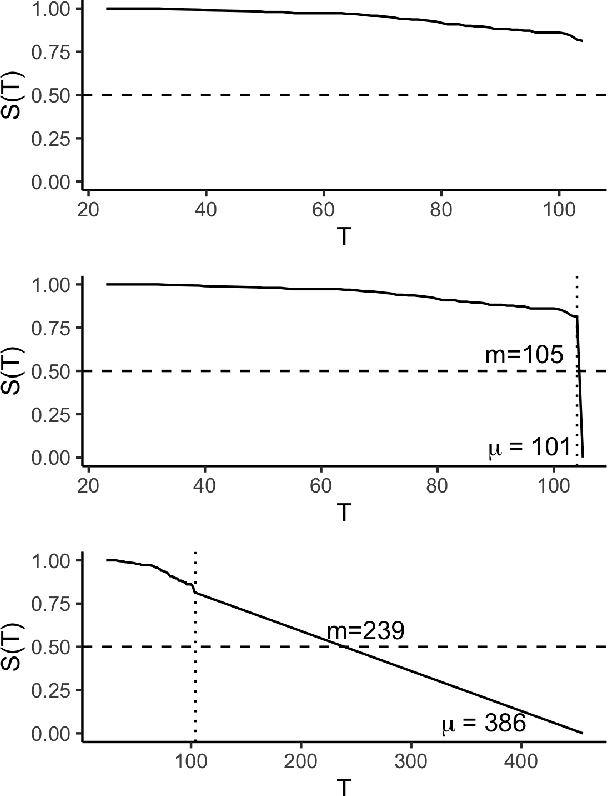
In this paper we consider how to evaluate survival distribution predictions with measures of discrimination. This is a non-trivial problem as discrimination measures are the most commonly used in survival analysis and yet there is no clear method to derive a risk prediction from a distribution prediction. We survey methods proposed in literature and software and consider their respective advantages and disadvantages. Whilst distributions are frequently evaluated by discrimination measures, we find that the method for doing so is rarely described in the literature and often leads to unfair comparisons. We find that the most robust method of reducing a distribution to a risk is to sum over the predicted cumulative hazard. We recommend that machine learning survival analysis software implements clear transformations between distribution and risk predictions in order to allow more transparent and accessible model evaluation.
Designing Machine Learning Toolboxes: Concepts, Principles and Patterns
Jan 13, 2021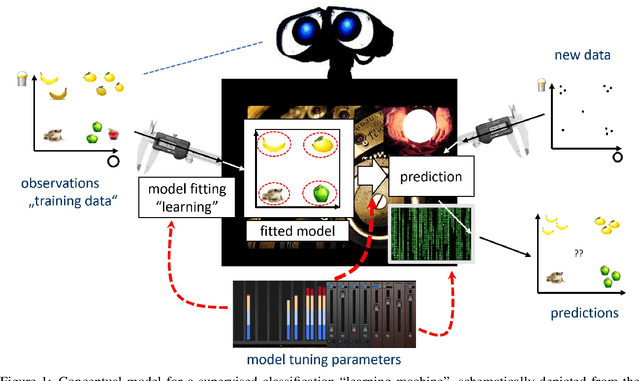



Machine learning (ML) and AI toolboxes such as scikit-learn or Weka are workhorses of contemporary data scientific practice -- their central role being enabled by usable yet powerful designs that allow to easily specify, train and validate complex modeling pipelines. However, despite their universal success, the key design principles in their construction have never been fully analyzed. In this paper, we attempt to provide an overview of key patterns in the design of AI modeling toolboxes, taking inspiration, in equal parts, from the field of software engineering, implementation patterns found in contemporary toolboxes, and our own experience from developing ML toolboxes. In particular, we develop a conceptual model for the AI/ML domain, with a new type system, called scientific types, at its core. Scientific types capture the scientific meaning of common elements in ML workflows based on the set of operations that we usually perform with them (i.e. their interface) and their statistical properties. From our conceptual analysis, we derive a set of design principles and patterns. We illustrate that our analysis can not only explain the design of existing toolboxes, but also guide the development of new ones. We intend our contribution to be a state-of-art reference for future toolbox engineers, a summary of best practices, a collection of ML design patterns which may become useful for future research, and, potentially, the first steps towards a higher-level programming paradigm for constructing AI.
mlr3proba: Machine Learning Survival Analysis in R
Aug 18, 2020As machine learning has become increasingly popular over the last few decades, so too has the number of machine learning interfaces for implementing these models. However, no consistent interface for evaluation and modelling of survival analysis has emerged despite its vital importance in many fields, including medicine, economics, and engineering. \texttt{mlr3proba} is part of the \texttt{mlr3} ecosystem of machine learning packages for R and facilitates \texttt{mlr3}'s general model tuning and benchmarking by providing a multitude of performance measures and learners for survival analysis with a clean and systematic infrastructure for their evaluation. \texttt{mlr3proba} provides a comprehensive machine learning interface for survival analysis, which allows survival modelling to finally be up to the state-of-art.
NIPS - Not Even Wrong? A Systematic Review of Empirically Complete Demonstrations of Algorithmic Effectiveness in the Machine Learning and Artificial Intelligence Literature
Dec 18, 2018
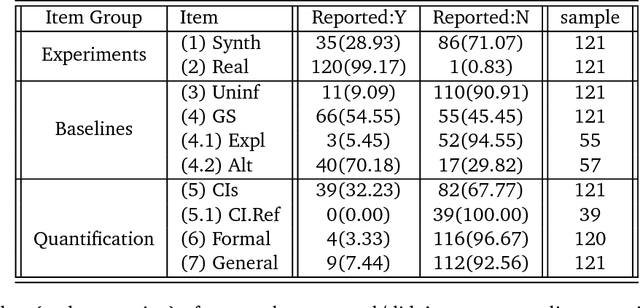
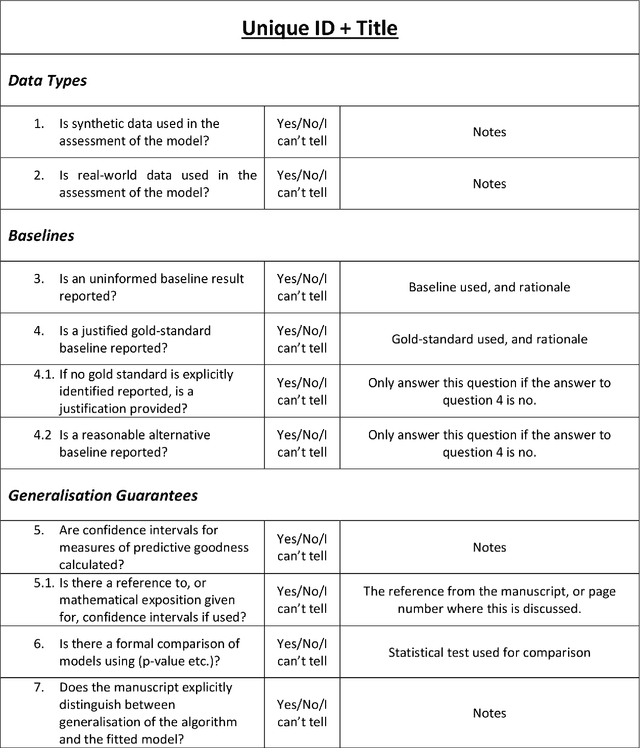
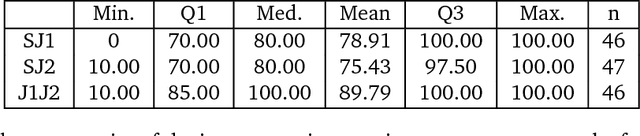
Objective: To determine the completeness of argumentative steps necessary to conclude effectiveness of an algorithm in a sample of current ML/AI supervised learning literature. Data Sources: Papers published in the Neural Information Processing Systems (NeurIPS, n\'ee NIPS) journal where the official record showed a 2017 year of publication. Eligibility Criteria: Studies reporting a (semi-)supervised model, or pre-processing fused with (semi-)supervised models for tabular data. Study Appraisal: Three reviewers applied the assessment criteria to determine argumentative completeness. The criteria were split into three groups, including: experiments (e.g real and/or synthetic data), baselines (e.g uninformed and/or state-of-art) and quantitative comparison (e.g. performance quantifiers with confidence intervals and formal comparison of the algorithm against baselines). Results: Of the 121 eligible manuscripts (from the sample of 679 abstracts), 99\% used real-world data and 29\% used synthetic data. 91\% of manuscripts did not report an uninformed baseline and 55\% reported a state-of-art baseline. 32\% reported confidence intervals for performance but none provided references or exposition for how these were calculated. 3\% reported formal comparisons. Limitations: The use of one journal as the primary information source may not be representative of all ML/AI literature. However, the NeurIPS conference is recognised to be amongst the top tier concerning ML/AI studies, so it is reasonable to consider its corpus to be representative of high-quality research. Conclusion: Using the 2017 sample of the NeurIPS supervised learning corpus as an indicator for the quality and trustworthiness of current ML/AI research, it appears that complete argumentative chains in demonstrations of algorithmic effectiveness are rare.