 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Machine Learning Toolboxes: Concepts, Principles and Patterns
Jan 13, 2021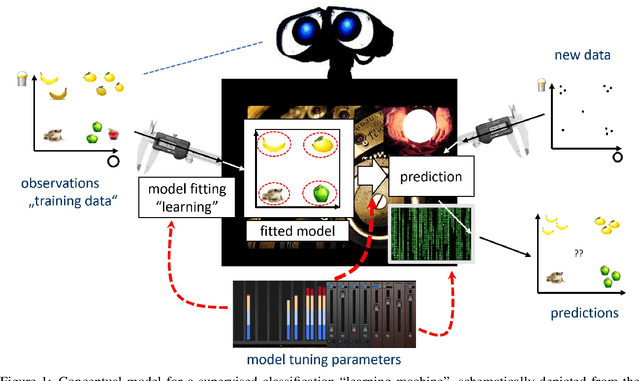



Machine learning (ML) and AI toolboxes such as scikit-learn or Weka are workhorses of contemporary data scientific practice -- their central role being enabled by usable yet powerful designs that allow to easily specify, train and validate complex modeling pipelines. However, despite their universal success, the key design principles in their construction have never been fully analyzed. In this paper, we attempt to provide an overview of key patterns in the design of AI modeling toolboxes, taking inspiration, in equal parts, from the field of software engineering, implementation patterns found in contemporary toolboxes, and our own experience from developing ML toolboxes. In particular, we develop a conceptual model for the AI/ML domain, with a new type system, called scientific types, at its core. Scientific types capture the scientific meaning of common elements in ML workflows based on the set of operations that we usually perform with them (i.e. their interface) and their statistical properties. From our conceptual analysis, we derive a set of design principles and patterns. We illustrate that our analysis can not only explain the design of existing toolboxes, but also guide the development of new ones. We intend our contribution to be a state-of-art reference for future toolbox engineers, a summary of best practices, a collection of ML design patterns which may become useful for future research, and, potentially, the first steps towards a higher-level programming paradigm for constructing AI.
Forecasting with sktime: Designing sktime's New Forecasting API and Applying It to Replicate and Extend the M4 Study
Jun 08, 2020
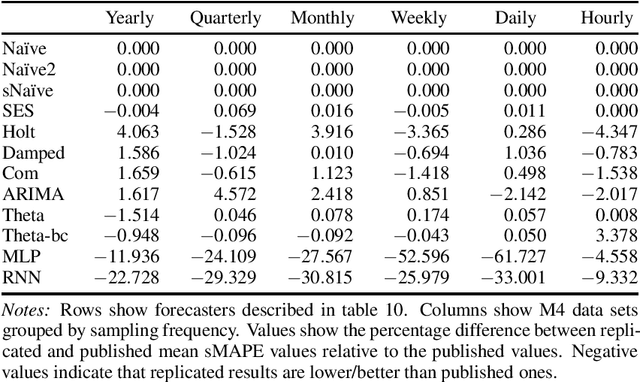


We present a new open-source framework for forecasting in Python. Our framework forms part of sktime, a more general machine learning toolbox for time series with scikit-learn compatible interfaces for different learning tasks. Our new framework provides dedicated forecasting algorithms and tools to build, tune and evaluate composite models. We use sktime to both replicate and extend key results from the M4 forecasting study. In particular, we further investigate the potential of simple off-the-shelf machine learning approaches for univariate forecasting. Our main results are that simple hybrid approaches can boost the performance of statistical models, and that simple pure approaches can achieve competitive performance on the hourly data set, outperforming the statistical algorithms and coming close to the M4 winner.
A tale of two toolkits, report the first: benchmarking time series classification algorithms for correctness and efficiency
Oct 07, 2019
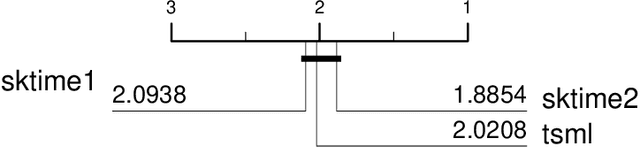
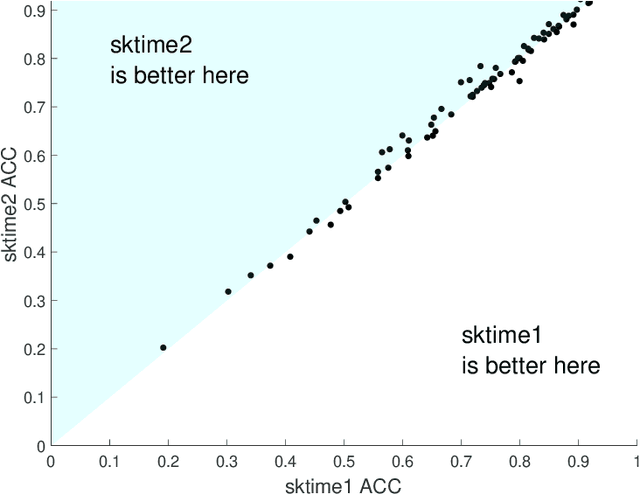
sktime is an open source, Python based, sklearn compatible toolkit for time series analysis developed by researchers at the University of East Anglia (UEA), University College London and the Alan Turing Institute. A key initial goal for sktime was to provide time series classification functionality equivalent to that available in a related java package, tsml, also developed at UEA. We describe the implementation of six such classifiers in sktime and compare them to their tsml equivalents. We demonstrate correctness through equivalence of accuracy on a range of standard test problems and compare the build time of the different implementations. We find that there is significant difference in accuracy on only one of the six algorithms we look at (Proximity Forest). This difference is causing us some pain in debugging. We found a much wider range of difference in efficiency. Again, this was not unexpected, but it does highlight ways both toolkits could be improved.
sktime: A Unified Interface for Machine Learning with Time Series
Sep 17, 2019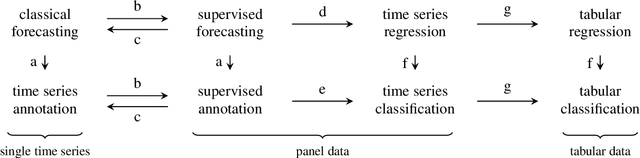
We present sktime -- a new scikit-learn compatible Python library with a unified interface for machine learning with time series. Time series data gives rise to various distinct but closely related learning tasks, such as forecasting and time series classification, many of which can be solved by reducing them to related simpler tasks. We discuss the main rationale for creating a unified interface, including reduction, as well as the design of sktime's core API, supported by a clear overview of common time series tasks and reduction approaches.