 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn time series clustering with k-means
Oct 18, 2024

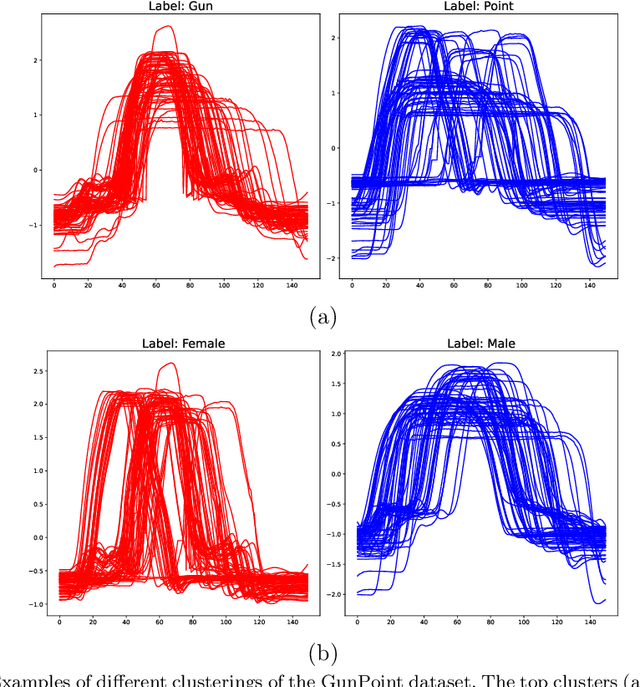

There is a long history of research into time series clustering using distance-based partitional clustering. Many of the most popular algorithms adapt k-means (also known as Lloyd's algorithm) to exploit time dependencies in the data by specifying a time series distance function. However, these algorithms are often presented with k-means configured in various ways, altering key parameters such as the initialisation strategy. This variability makes it difficult to compare studies because k-means is known to be highly sensitive to its configuration. To address this, we propose a standard Lloyd's-based model for TSCL that adopts an end-to-end approach, incorporating a specialised distance function not only in the assignment step but also in the initialisation and stopping criteria. By doing so, we create a unified structure for comparing seven popular Lloyd's-based TSCL algorithms. This common framework enables us to more easily attribute differences in clustering performance to the distance function itself, rather than variations in the k-means configuration.
HIVE-COTE 2.0: a new meta ensemble for time series classification
Apr 15, 2021



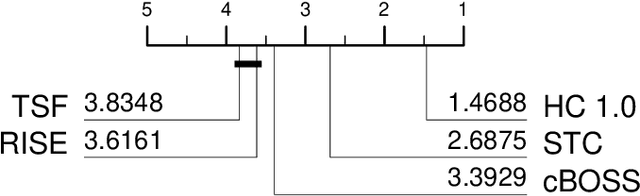
The Hierarchical Vote Collective of Transformation-based Ensembles (HIVE-COTE) is a heterogeneous meta ensemble for time series classification. HIVE-COTE forms its ensemble from classifiers of multiple domains, including phase-independent shapelets, bag-of-words based dictionaries and phase-dependent intervals. Since it was first proposed in 2016, the algorithm has remained state of the art for accuracy on the UCR time series classification archive. Over time it has been incrementally updated, culminating in its current state, HIVE-COTE 1.0. During this time a number of algorithms have been proposed which match the accuracy of HIVE-COTE. We propose comprehensive changes to the HIVE-COTE algorithm which significantly improve its accuracy and usability, presenting this upgrade as HIVE-COTE 2.0. We introduce two novel classifiers, the Temporal Dictionary Ensemble (TDE) and Diverse Representation Canonical Interval Forest (DrCIF), which replace existing ensemble members. Additionally, we introduce the Arsenal, an ensemble of ROCKET classifiers as a new HIVE-COTE 2.0 constituent. We demonstrate that HIVE-COTE 2.0 is significantly more accurate than the current state of the art on 112 univariate UCR archive datasets and 26 multivariate UEA archive datasets.
A tale of two toolkits, report the third: on the usage and performance of HIVE-COTE v1.0
Apr 25, 2020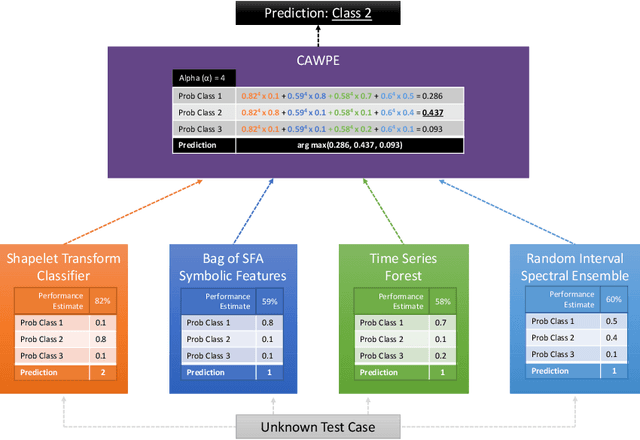
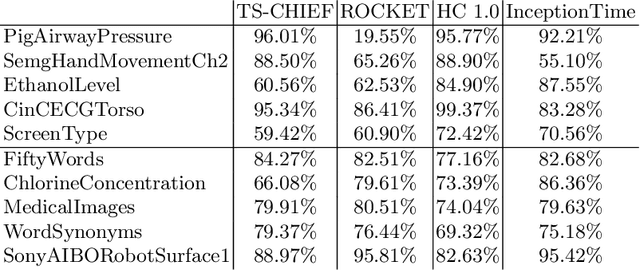

The Hierarchical Vote Collective of Transformation-based Ensembles (HIVE-COTE) is a heterogeneous meta ensemble for time series classification. Since it was first proposed in 2016, the algorithm has undergone some minor changes and there is now a configurable, scalable and easy to use version available in two open source repositories. We present an overview of the latest stable HIVE-COTE, version 1.0, and describe how it differs to the original. We provide a walkthrough guide of how to use the classifier, and conduct extensive experimental evaluation of its predictive performance and resource usage. We compare the performance of HIVE-COTE to three recently proposed algorithms.
sktime: A Unified Interface for Machine Learning with Time Series
Sep 17, 2019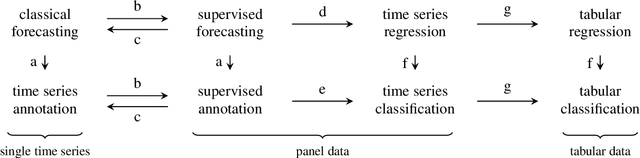
We present sktime -- a new scikit-learn compatible Python library with a unified interface for machine learning with time series. Time series data gives rise to various distinct but closely related learning tasks, such as forecasting and time series classification, many of which can be solved by reducing them to related simpler tasks. We discuss the main rationale for creating a unified interface, including reduction, as well as the design of sktime's core API, supported by a clear overview of common time series tasks and reduction approaches.
The UEA multivariate time series classification archive, 2018
Oct 31, 2018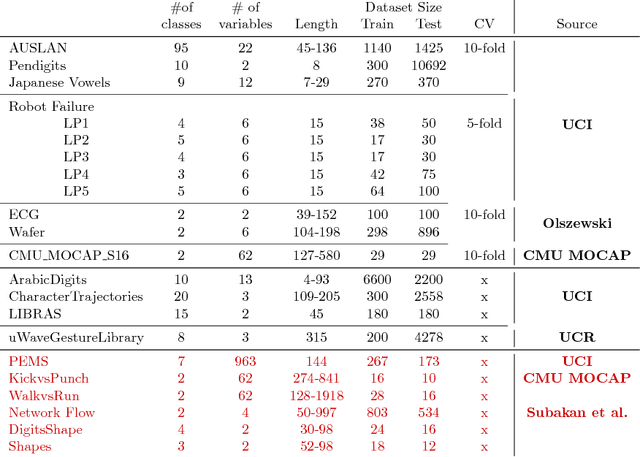
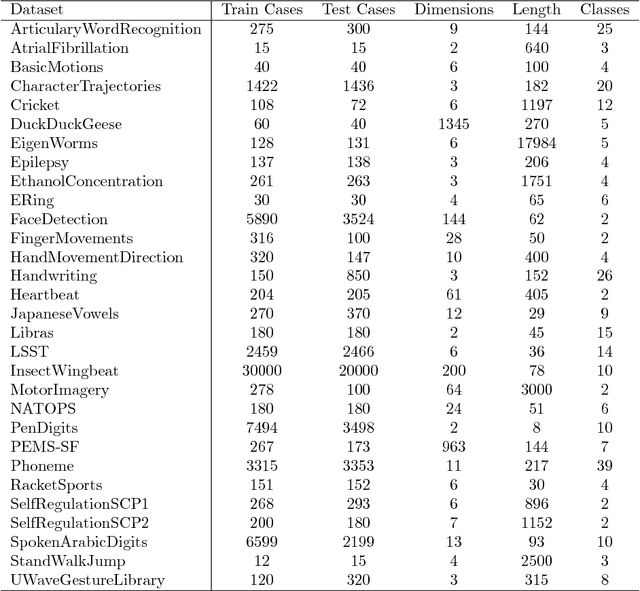
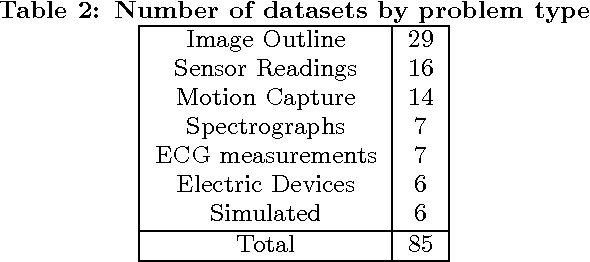
In 2002, the UCR time series classification archive was first released with sixteen datasets. It gradually expanded, until 2015 when it increased in size from 45 datasets to 85 datasets. In October 2018 more datasets were added, bringing the total to 128. The new archive contains a wide range of problems, including variable length series, but it still only contains univariate time series classification problems. One of the motivations for introducing the archive was to encourage researchers to perform a more rigorous evaluation of newly proposed time series classification (TSC) algorithms. It has worked: most recent research into TSC uses all 85 datasets to evaluate algorithmic advances. Research into multivariate time series classification, where more than one series are associated with each class label, is in a position where univariate TSC research was a decade ago. Algorithms are evaluated using very few datasets and claims of improvement are not based on statistical comparisons. We aim to address this problem by forming the first iteration of the MTSC archive, to be hosted at the website www.timeseriesclassification.com. Like the univariate archive, this formulation was a collaborative effort between researchers at the University of East Anglia (UEA) and the University of California, Riverside (UCR). The 2018 vintage consists of 30 datasets with a wide range of cases, dimensions and series lengths. For this first iteration of the archive we format all data to be of equal length, include no series with missing data and provide train/test splits.
The Heterogeneous Ensembles of Standard Classification Algorithms (HESCA): the Whole is Greater than the Sum of its Parts
Oct 25, 2017
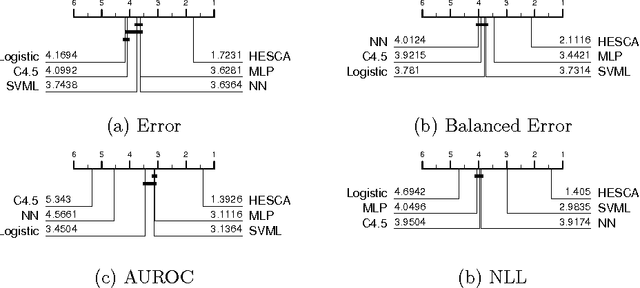


Building classification models is an intrinsically practical exercise that requires many design decisions prior to deployment. We aim to provide some guidance in this decision making process. Specifically, given a classification problem with real valued attributes, we consider which classifier or family of classifiers should one use. Strong contenders are tree based homogeneous ensembles, support vector machines or deep neural networks. All three families of model could claim to be state-of-the-art, and yet it is not clear when one is preferable to the others. Our extensive experiments with over 200 data sets from two distinct archives demonstrate that, rather than choose a single family and expend computing resources on optimising that model, it is significantly better to build simpler versions of classifiers from each family and ensemble. We show that the Heterogeneous Ensembles of Standard Classification Algorithms (HESCA), which ensembles based on error estimates formed on the train data, is significantly better (in terms of error, balanced error, negative log likelihood and area under the ROC curve) than its individual components, picking the component that is best on train data, and a support vector machine tuned over 1089 different parameter configurations. We demonstrate HESCA+, which contains a deep neural network, a support vector machine and two decision tree forests, is significantly better than its components, picking the best component, and HESCA. We analyse the results further and find that HESCA and HESCA+ are of particular value when the train set size is relatively small and the problem has multiple classes. HESCA is a fast approach that is, on average, as good as state-of-the-art classifiers, whereas HESCA+ is significantly better than average and represents a strong benchmark for future research.
Simulated Data Experiments for Time Series Classification Part 1: Accuracy Comparison with Default Settings
Mar 28, 2017


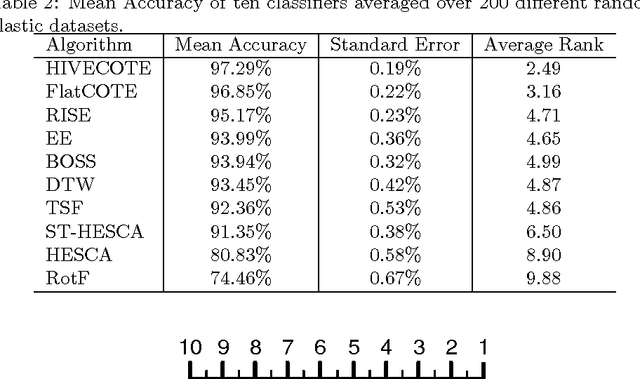
There are now a broad range of time series classification (TSC) algorithms designed to exploit different representations of the data. These have been evaluated on a range of problems hosted at the UCR-UEA TSC Archive (www.timeseriesclassification.com), and there have been extensive comparative studies. However, our understanding of why one algorithm outperforms another is still anecdotal at best. This series of experiments is meant to help provide insights into what sort of discriminatory features in the data lead one set of algorithms that exploit a particular representation to be better than other algorithms. We categorise five different feature spaces exploited by TSC algorithms then design data simulators to generate randomised data from each representation. We describe what results we expected from each class of algorithm and data representation, then observe whether these prior beliefs are supported by the experimental evidence. We provide an open source implementation of all the simulators to allow for the controlled testing of hypotheses relating to classifier performance on different data representations. We identify many surprising results that confounded our expectations, and use these results to highlight how an over simplified view of classifier structure can often lead to erroneous prior beliefs. We believe ensembling can often overcome prior bias, and our results support the belief by showing that the ensemble approach adopted by the Hierarchical Collective of Transform based Ensembles (HIVE-COTE) is significantly better than the alternatives when the data representation is unknown, and is significantly better than, or not significantly significantly better than, or not significantly worse than, the best other approach on three out of five of the individual simulators.
The Great Time Series Classification Bake Off: An Experimental Evaluation of Recently Proposed Algorithms. Extended Version
Feb 04, 2016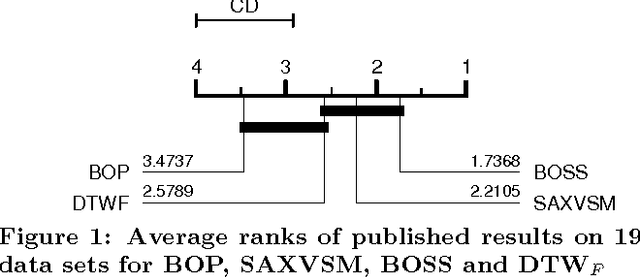


In the last five years there have been a large number of new time series classification algorithms proposed in the literature. These algorithms have been evaluated on subsets of the 47 data sets in the University of California, Riverside time series classification archive. The archive has recently been expanded to 85 data sets, over half of which have been donated by researchers at the University of East Anglia. Aspects of previous evaluations have made comparisons between algorithms difficult. For example, several different programming languages have been used, experiments involved a single train/test split and some used normalised data whilst others did not. The relaunch of the archive provides a timely opportunity to thoroughly evaluate algorithms on a larger number of datasets. We have implemented 18 recently proposed algorithms in a common Java framework and compared them against two standard benchmark classifiers (and each other) by performing 100 resampling experiments on each of the 85 datasets. We use these results to test several hypotheses relating to whether the algorithms are significantly more accurate than the benchmarks and each other. Our results indicate that only 9 of these algorithms are significantly more accurate than both benchmarks and that one classifier, the Collective of Transformation Ensembles, is significantly more accurate than all of the others. All of our experiments and results are reproducible: we release all of our code, results and experimental details and we hope these experiments form the basis for more rigorous testing of new algorithms in the future.
Finding Motif Sets in Time Series
Jul 14, 2014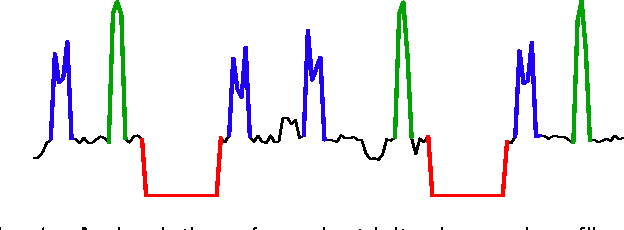



Time-series motifs are representative subsequences that occur frequently in a time series; a motif set is the set of subsequences deemed to be instances of a given motif. We focus on finding motif sets. Our motivation is to detect motif sets in household electricity-usage profiles, representing repeated patterns of household usage. We propose three algorithms for finding motif sets. Two are greedy algorithms based on pairwise comparison, and the third uses a heuristic measure of set quality to find the motif set directly. We compare these algorithms on simulated datasets and on electricity-usage data. We show that Scan MK, the simplest way of using the best-matching pair to find motif sets, is less accurate on our synthetic data than Set Finder and Cluster MK, although the latter is very sensitive to parameter settings. We qualitatively analyse the outputs for the electricity-usage data and demonstrate that both Scan MK and Set Finder can discover useful motif sets in such data.
An Experimental Evaluation of Nearest Neighbour Time Series Classification
Jun 18, 2014


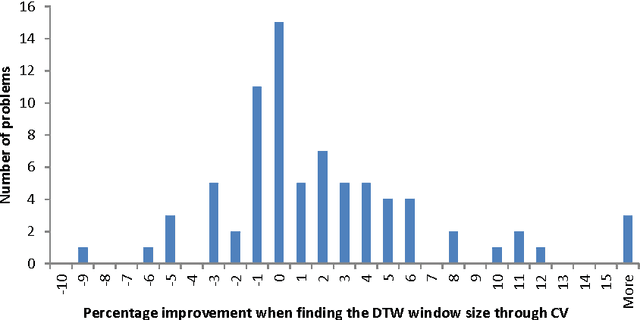
Data mining research into time series classification (TSC) has focussed on alternative distance measures for nearest neighbour classifiers. It is standard practice to use 1-NN with Euclidean or dynamic time warping (DTW) distance as a straw man for comparison. As part of a wider investigation into elastic distance measures for TSC~\cite{lines14elastic}, we perform a series of experiments to test whether this standard practice is valid. Specifically, we compare 1-NN classifiers with Euclidean and DTW distance to standard classifiers, examine whether the performance of 1-NN Euclidean approaches that of 1-NN DTW as the number of cases increases, assess whether there is any benefit of setting $k$ for $k$-NN through cross validation whether it is worth setting the warping path for DTW through cross validation and finally is it better to use a window or weighting for DTW. Based on experiments on 77 problems, we conclude that 1-NN with Euclidean distance is fairly easy to beat but 1-NN with DTW is not, if window size is set through cross validation.