 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulated Data Experiments for Time Series Classification Part 1: Accuracy Comparison with Default Settings
Paper and Code



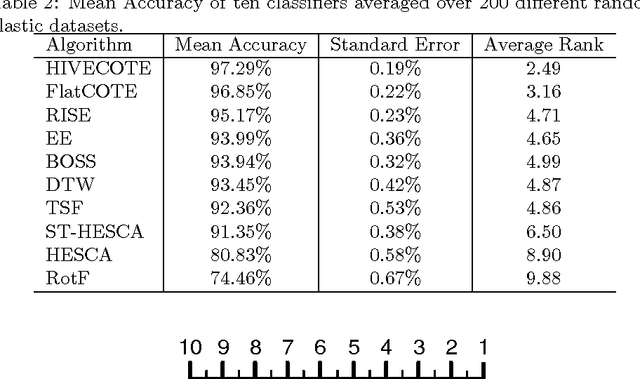
There are now a broad range of time series classification (TSC) algorithms designed to exploit different representations of the data. These have been evaluated on a range of problems hosted at the UCR-UEA TSC Archive (www.timeseriesclassification.com), and there have been extensive comparative studies. However, our understanding of why one algorithm outperforms another is still anecdotal at best. This series of experiments is meant to help provide insights into what sort of discriminatory features in the data lead one set of algorithms that exploit a particular representation to be better than other algorithms. We categorise five different feature spaces exploited by TSC algorithms then design data simulators to generate randomised data from each representation. We describe what results we expected from each class of algorithm and data representation, then observe whether these prior beliefs are supported by the experimental evidence. We provide an open source implementation of all the simulators to allow for the controlled testing of hypotheses relating to classifier performance on different data representations. We identify many surprising results that confounded our expectations, and use these results to highlight how an over simplified view of classifier structure can often lead to erroneous prior beliefs. We believe ensembling can often overcome prior bias, and our results support the belief by showing that the ensemble approach adopted by the Hierarchical Collective of Transform based Ensembles (HIVE-COTE) is significantly better than the alternatives when the data representation is unknown, and is significantly better than, or not significantly significantly better than, or not significantly worse than, the best other approach on three out of five of the individual simulators.