 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Electric Devices in 3D Images of Bags
Apr 25, 2020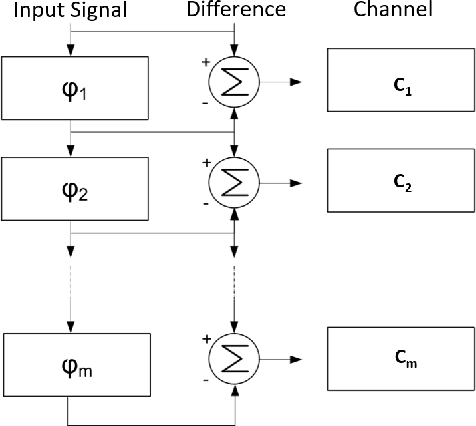



The aviation and transport security industries face the challenge of screening high volumes of baggage for threats and contraband in the minimum time possible. Automation and semi-automation of this procedure offers the potential to increase security by detecting more threats and improve the customer experience by speeding up the process. Traditional 2D x-ray images are often extremely difficult to examine due to the fact that they are tightly packed and contain a wide variety of cluttered and occluded objects. Because of these limitations, major airports are introducing 3D x-ray Computed Tomography (CT) baggage scanning. We investigate whether we can automate the process of detecting electric devices in these 3D images of luggage. Detecting electrical devices is of particular concern as they can be used to conceal explosives. Given the massive volume of luggage that needs to be screened for this threat, the best way to automate the detection is to first filter whether a bag contains an electric device or not, and if it does, to identify the number of devices and their location. We present an algorithm, Unpack, Predict, eXtract, Repack (UXPR), which involves unpacking through segmenting the data at a range of scales using an algorithm known as the Sieve, predicting whether a segment is electrical or not based on the histogram of voxel intensities, then repacking the bag by ensembling the segments and predictions to identify the devices in bags. Through a range of experiments using data provided by ALERT (Awareness and Localization of Explosives-Related Threats) we show that this system can find a high proportion of devices with unsupervised segmentation if a similar device has been seen before, and shows promising results for detecting devices not seen at all based on the properties of its constituent parts.
Can automated smoothing significantly improve benchmark time series classification algorithms?
Nov 01, 2018
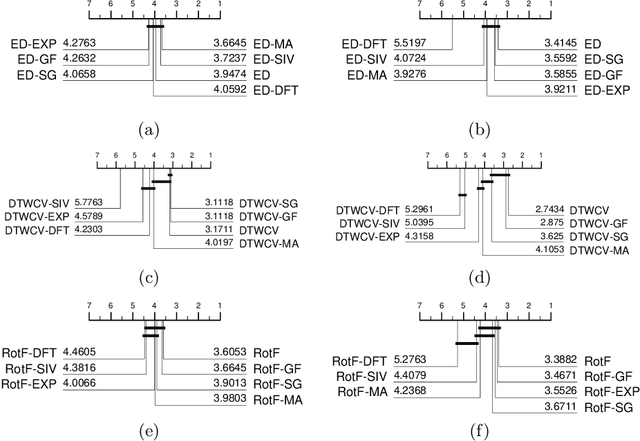

tl;dr: no, it cannot, at least not on average on the standard archive problems. We assess whether using six smoothing algorithms (moving average, exponential smoothing, Gaussian filter, Savitzky-Golay filter, Fourier approximation and a recursive median sieve) could be automatically applied to time series classification problems as a preprocessing step to improve the performance of three benchmark classifiers (1-Nearest Neighbour with Euclidean and Dynamic Time Warping distances, and Rotation Forest). We found no significant improvement over unsmoothed data even when we set the smoothing parameter through cross validation. We are not claiming smoothing has no worth. It has an important role in exploratory analysis and helps with specific classification problems where domain knowledge can be exploited. What we observe is that the automatic application does not help and that we cannot explain the improvement of other time series classification algorithms over the baseline classifiers simply as a function of the absence of smoothing.
The UEA multivariate time series classification archive, 2018
Oct 31, 2018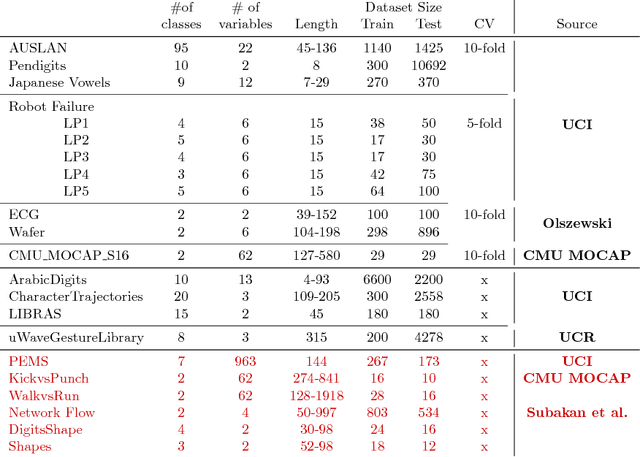
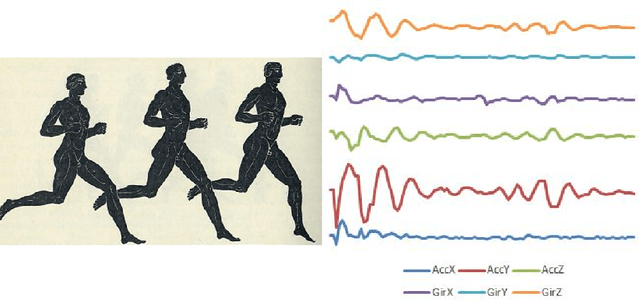
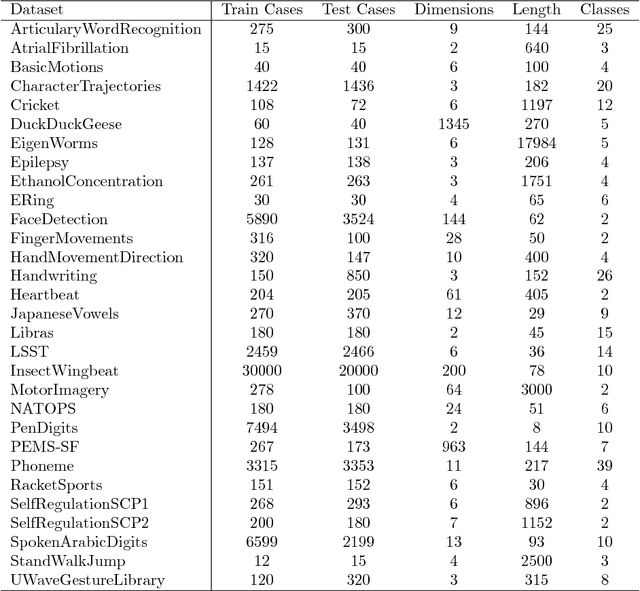
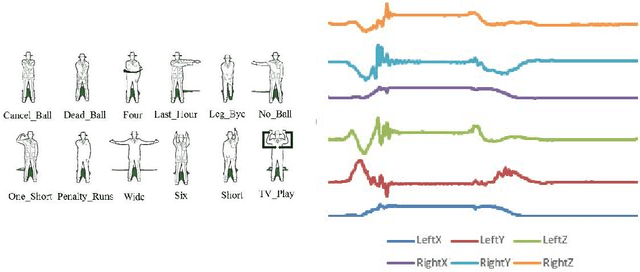
In 2002, the UCR time series classification archive was first released with sixteen datasets. It gradually expanded, until 2015 when it increased in size from 45 datasets to 85 datasets. In October 2018 more datasets were added, bringing the total to 128. The new archive contains a wide range of problems, including variable length series, but it still only contains univariate time series classification problems. One of the motivations for introducing the archive was to encourage researchers to perform a more rigorous evaluation of newly proposed time series classification (TSC) algorithms. It has worked: most recent research into TSC uses all 85 datasets to evaluate algorithmic advances. Research into multivariate time series classification, where more than one series are associated with each class label, is in a position where univariate TSC research was a decade ago. Algorithms are evaluated using very few datasets and claims of improvement are not based on statistical comparisons. We aim to address this problem by forming the first iteration of the MTSC archive, to be hosted at the website www.timeseriesclassification.com. Like the univariate archive, this formulation was a collaborative effort between researchers at the University of East Anglia (UEA) and the University of California, Riverside (UCR). The 2018 vintage consists of 30 datasets with a wide range of cases, dimensions and series lengths. For this first iteration of the archive we format all data to be of equal length, include no series with missing data and provide train/test splits.