 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Electric Devices in 3D Images of Bags
Apr 25, 2020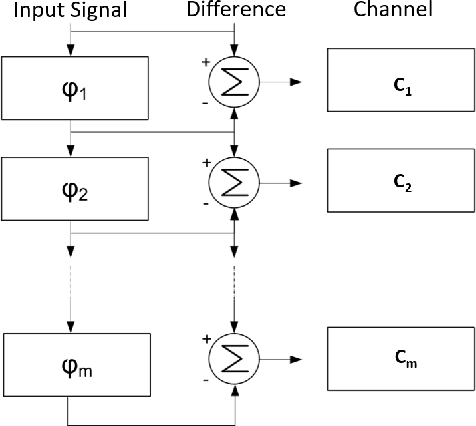



The aviation and transport security industries face the challenge of screening high volumes of baggage for threats and contraband in the minimum time possible. Automation and semi-automation of this procedure offers the potential to increase security by detecting more threats and improve the customer experience by speeding up the process. Traditional 2D x-ray images are often extremely difficult to examine due to the fact that they are tightly packed and contain a wide variety of cluttered and occluded objects. Because of these limitations, major airports are introducing 3D x-ray Computed Tomography (CT) baggage scanning. We investigate whether we can automate the process of detecting electric devices in these 3D images of luggage. Detecting electrical devices is of particular concern as they can be used to conceal explosives. Given the massive volume of luggage that needs to be screened for this threat, the best way to automate the detection is to first filter whether a bag contains an electric device or not, and if it does, to identify the number of devices and their location. We present an algorithm, Unpack, Predict, eXtract, Repack (UXPR), which involves unpacking through segmenting the data at a range of scales using an algorithm known as the Sieve, predicting whether a segment is electrical or not based on the histogram of voxel intensities, then repacking the bag by ensembling the segments and predictions to identify the devices in bags. Through a range of experiments using data provided by ALERT (Awareness and Localization of Explosives-Related Threats) we show that this system can find a high proportion of devices with unsupervised segmentation if a similar device has been seen before, and shows promising results for detecting devices not seen at all based on the properties of its constituent parts.
Comparing heterogeneous visual gestures for measuring the diversity of visual speech signals
May 08, 2018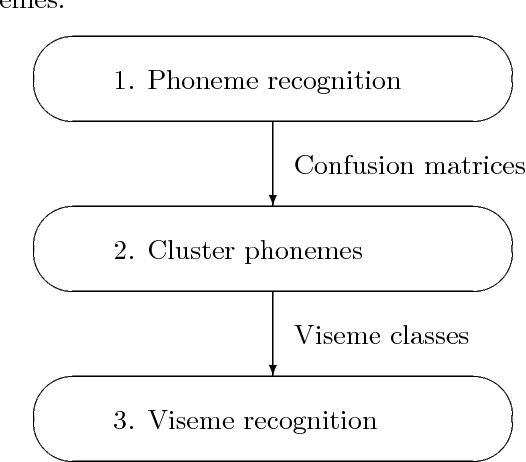
Visual lip gestures observed whilst lipreading have a few working definitions, the most common two are; `the visual equivalent of a phoneme' and `phonemes which are indistinguishable on the lips'. To date there is no formal definition, in part because to date we have not established a two-way relationship or mapping between visemes and phonemes. Some evidence suggests that visual speech is highly dependent upon the speaker. So here, we use a phoneme-clustering method to form new phoneme-to-viseme maps for both individual and multiple speakers. We test these phoneme to viseme maps to examine how similarly speakers talk visually and we use signed rank tests to measure the distance between individuals. We conclude that broadly speaking, speakers have the same repertoire of mouth gestures, where they differ is in the use of the gestures.
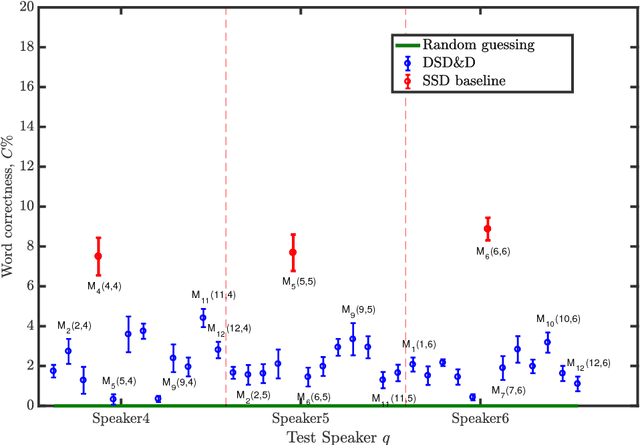
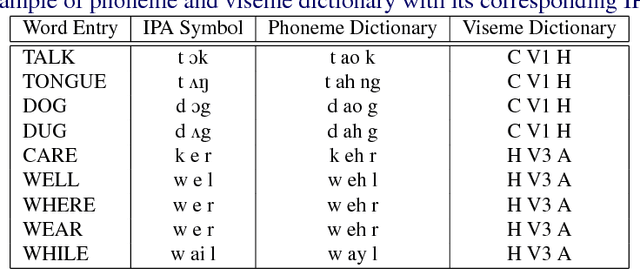
Phoneme-to-viseme mappings: the good, the bad, and the ugly
May 08, 2018


Visemes are the visual equivalent of phonemes. Although not precisely defined, a working definition of a viseme is "a set of phonemes which have identical appearance on the lips". Therefore a phoneme falls into one viseme class but a viseme may represent many phonemes: a many to one mapping. This mapping introduces ambiguity between phonemes when using viseme classifiers. Not only is this ambiguity damaging to the performance of audio-visual classifiers operating on real expressive speech, there is also considerable choice between possible mappings. In this paper we explore the issue of this choice of viseme-to-phoneme map. We show that there is definite difference in performance between viseme-to-phoneme mappings and explore why some maps appear to work better than others. We also devise a new algorithm for constructing phoneme-to-viseme mappings from labeled speech data. These new visemes, `Bear' visemes, are shown to perform better than previously known units.
Comparing phonemes and visemes with DNN-based lipreading
May 08, 2018


There is debate if phoneme or viseme units are the most effective for a lipreading system. Some studies use phoneme units even though phonemes describe unique short sounds; other studies tried to improve lipreading accuracy by focusing on visemes with varying results. We compare the performance of a lipreading system by modeling visual speech using either 13 viseme or 38 phoneme units. We report the accuracy of our system at both word and unit levels. The evaluation task is large vocabulary continuous speech using the TCD-TIMIT corpus. We complete our visual speech modeling via hybrid DNN-HMMs and our visual speech decoder is a Weighted Finite-State Transducer (WFST). We use DCT and Eigenlips as a representation of mouth ROI image. The phoneme lipreading system word accuracy outperforms the viseme based system word accuracy. However, the phoneme system achieved lower accuracy at the unit level which shows the importance of the dictionary for decoding classification outputs into words.
Decoding visemes: improving machine lipreading
Oct 03, 2017


To undertake machine lip-reading, we try to recognise speech from a visual signal. Current work often uses viseme classification supported by language models with varying degrees of success. A few recent works suggest phoneme classification, in the right circumstances, can outperform viseme classification. In this work we present a novel two-pass method of training phoneme classifiers which uses previously trained visemes in the first pass. With our new training algorithm, we show classification performance which significantly improves on previous lip-reading results.
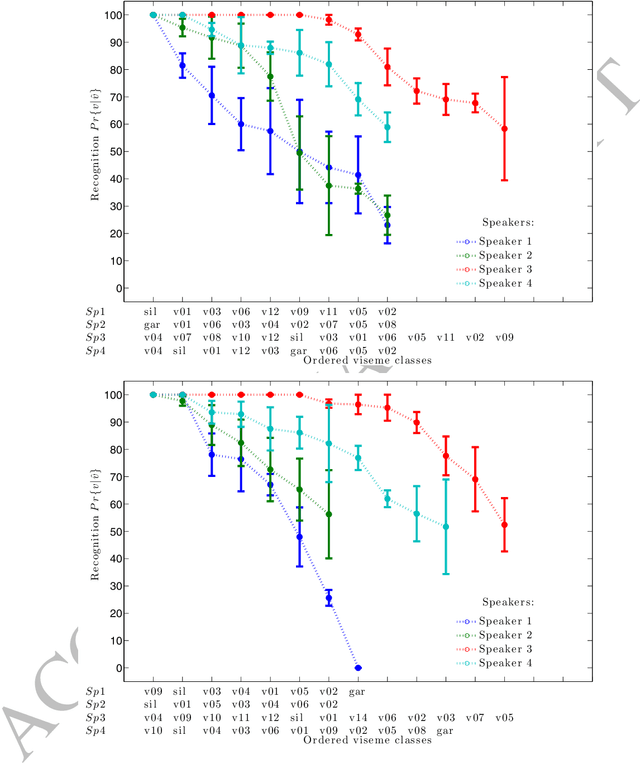
Some observations on computer lip-reading: moving from the dream to the reality
Oct 03, 2017In the quest for greater computer lip-reading performance there are a number of tacit assumptions which are either present in the datasets (high resolution for example) or in the methods (recognition of spoken visual units called visemes for example). Here we review these and other assumptions and show the surprising result that computer lip-reading is not heavily constrained by video resolution, pose, lighting and other practical factors. However, the working assumption that visemes, which are the visual equivalent of phonemes, are the best unit for recognition does need further examination. We conclude that visemes, which were defined over a century ago, are unlikely to be optimal for a modern computer lip-reading system.
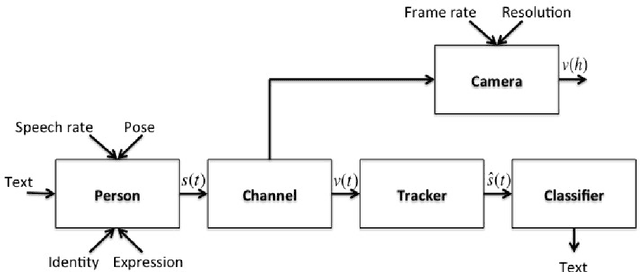
Resolution limits on visual speech recognition
Oct 03, 2017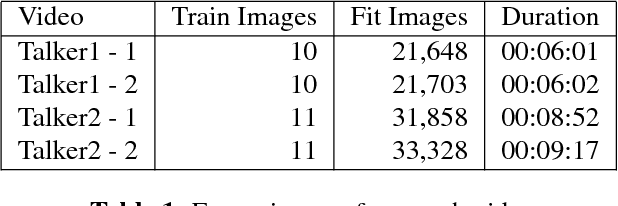

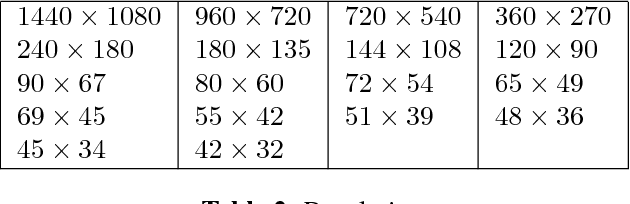
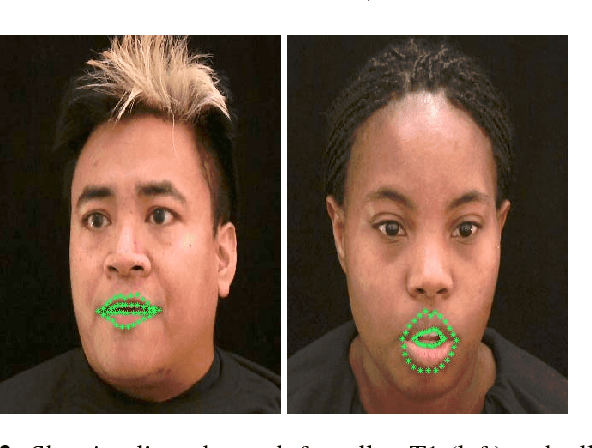
Visual-only speech recognition is dependent upon a number of factors that can be difficult to control, such as: lighting; identity; motion; emotion and expression. But some factors, such as video resolution are controllable, so it is surprising that there is not yet a systematic study of the effect of resolution on lip-reading. Here we use a new data set, the Rosetta Raven data, to train and test recognizers so we can measure the affect of video resolution on recognition accuracy. We conclude that, contrary to common practice, resolution need not be that great for automatic lip-reading. However it is highly unlikely that automatic lip-reading can work reliably when the distance between the bottom of the lower lip and the top of the upper lip is less than four pixels at rest.