 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing heterogeneous visual gestures for measuring the diversity of visual speech signals
May 08, 2018
Visual lip gestures observed whilst lipreading have a few working definitions, the most common two are; `the visual equivalent of a phoneme' and `phonemes which are indistinguishable on the lips'. To date there is no formal definition, in part because to date we have not established a two-way relationship or mapping between visemes and phonemes. Some evidence suggests that visual speech is highly dependent upon the speaker. So here, we use a phoneme-clustering method to form new phoneme-to-viseme maps for both individual and multiple speakers. We test these phoneme to viseme maps to examine how similarly speakers talk visually and we use signed rank tests to measure the distance between individuals. We conclude that broadly speaking, speakers have the same repertoire of mouth gestures, where they differ is in the use of the gestures.
Phoneme-to-viseme mappings: the good, the bad, and the ugly
May 08, 2018


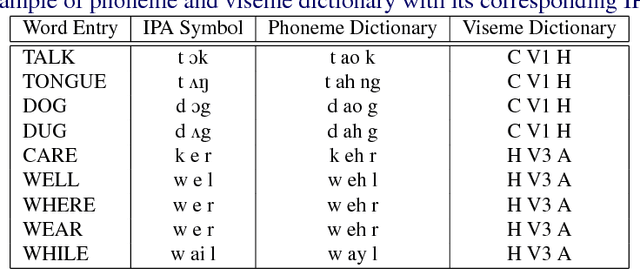
Visemes are the visual equivalent of phonemes. Although not precisely defined, a working definition of a viseme is "a set of phonemes which have identical appearance on the lips". Therefore a phoneme falls into one viseme class but a viseme may represent many phonemes: a many to one mapping. This mapping introduces ambiguity between phonemes when using viseme classifiers. Not only is this ambiguity damaging to the performance of audio-visual classifiers operating on real expressive speech, there is also considerable choice between possible mappings. In this paper we explore the issue of this choice of viseme-to-phoneme map. We show that there is definite difference in performance between viseme-to-phoneme mappings and explore why some maps appear to work better than others. We also devise a new algorithm for constructing phoneme-to-viseme mappings from labeled speech data. These new visemes, `Bear' visemes, are shown to perform better than previously known units.
Comparing phonemes and visemes with DNN-based lipreading
May 08, 2018


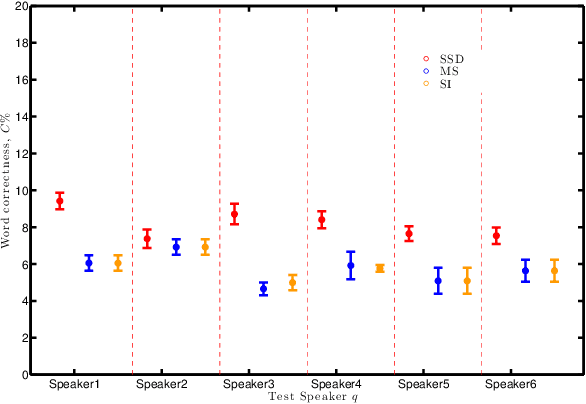
There is debate if phoneme or viseme units are the most effective for a lipreading system. Some studies use phoneme units even though phonemes describe unique short sounds; other studies tried to improve lipreading accuracy by focusing on visemes with varying results. We compare the performance of a lipreading system by modeling visual speech using either 13 viseme or 38 phoneme units. We report the accuracy of our system at both word and unit levels. The evaluation task is large vocabulary continuous speech using the TCD-TIMIT corpus. We complete our visual speech modeling via hybrid DNN-HMMs and our visual speech decoder is a Weighted Finite-State Transducer (WFST). We use DCT and Eigenlips as a representation of mouth ROI image. The phoneme lipreading system word accuracy outperforms the viseme based system word accuracy. However, the phoneme system achieved lower accuracy at the unit level which shows the importance of the dictionary for decoding classification outputs into words.
Understanding the visual speech signal
Oct 03, 2017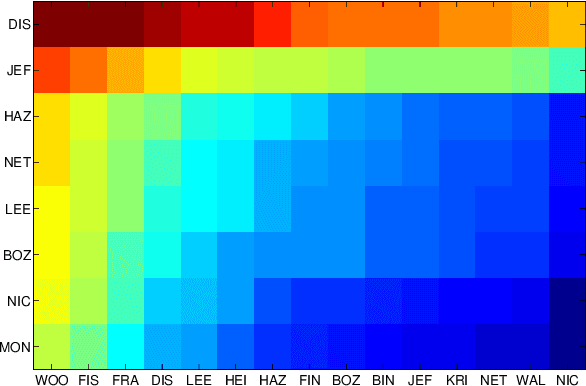

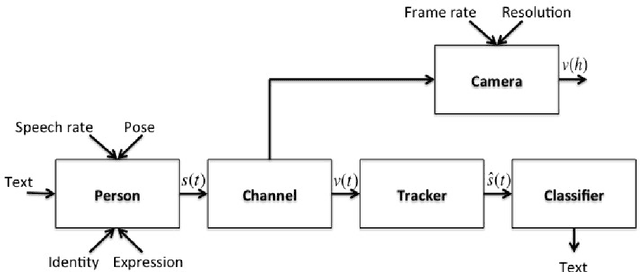
For machines to lipread, or understand speech from lip movement, they decode lip-motions (known as visemes) into the spoken sounds. We investigate the visual speech channel to further our understanding of visemes. This has applications beyond machine lipreading; speech therapists, animators, and psychologists can benefit from this work. We explain the influence of speaker individuality, and demonstrate how one can use visemes to boost lipreading.
Visual gesture variability between talkers in continuous visual speech
Oct 03, 2017


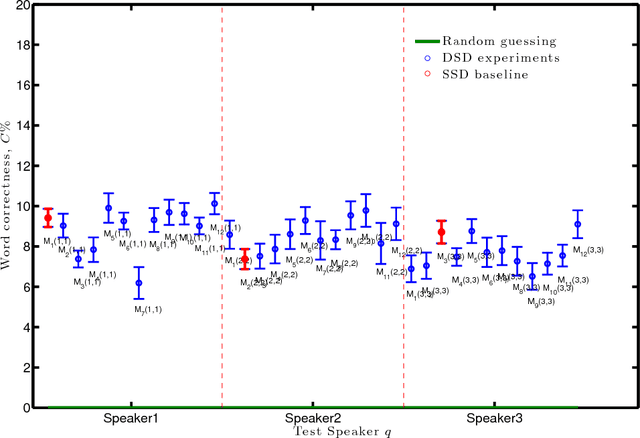
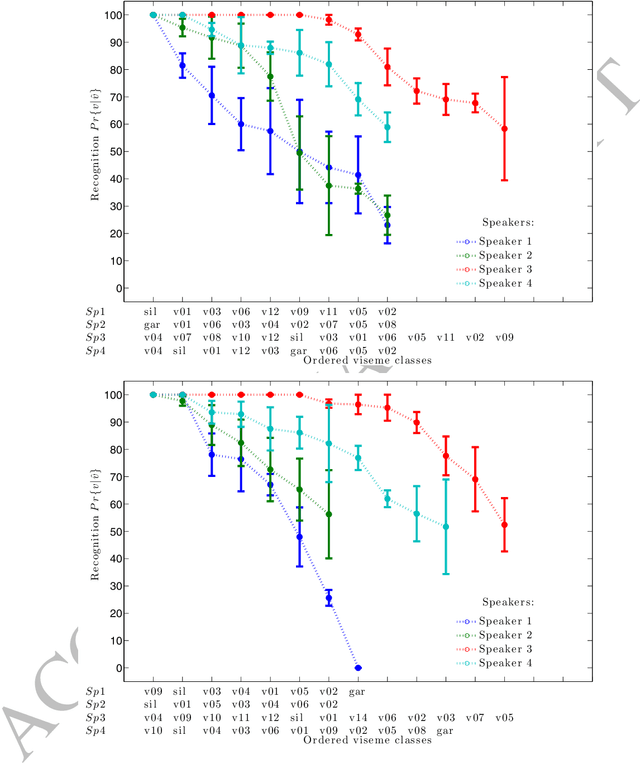
Recent adoption of deep learning methods to the field of machine lipreading research gives us two options to pursue to improve system performance. Either, we develop end-to-end systems holistically or, we experiment to further our understanding of the visual speech signal. The latter option is more difficult but this knowledge would enable researchers to both improve systems and apply the new knowledge to other domains such as speech therapy. One challenge in lipreading systems is the correct labeling of the classifiers. These labels map an estimated function between visemes on the lips and the phonemes uttered. Here we ask if such maps are speaker-dependent? Prior work investigated isolated word recognition from speaker-dependent (SD) visemes, we extend this to continuous speech. Benchmarked against SD results, and the isolated words performance, we test with RMAV dataset speakers and observe that with continuous speech, the trajectory between visemes has a greater negative effect on the speaker differentiation.
Visual speech recognition: aligning terminologies for better understanding
Oct 03, 2017



We are at an exciting time for machine lipreading. Traditional research stemmed from the adaptation of audio recognition systems. But now, the computer vision community is also participating. This joining of two previously disparate areas with different perspectives on computer lipreading is creating opportunities for collaborations, but in doing so the literature is experiencing challenges in knowledge sharing due to multiple uses of terms and phrases and the range of methods for scoring results. In particular we highlight three areas with the intention to improve communication between those researching lipreading; the effects of interchanging between speech reading and lipreading; speaker dependence across train, validation, and test splits; and the use of accuracy, correctness, errors, and varying units (phonemes, visemes, words, and sentences) to measure system performance. We make recommendations as to how we can be more consistent.
Decoding visemes: improving machine lipreading
Oct 03, 2017


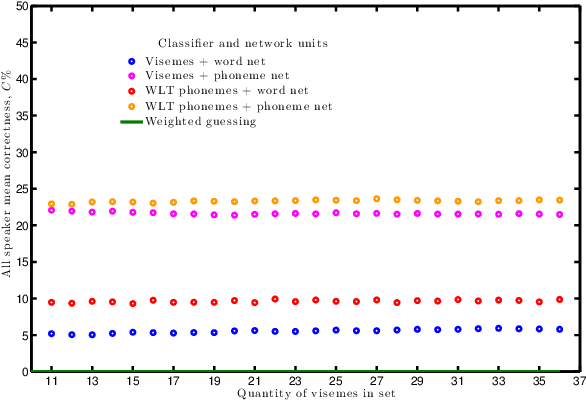
Machine lipreading (MLR) is speech recognition from visual cues and a niche research problem in speech processing & computer vision. Current challenges fall into two groups: the content of the video, such as rate of speech or; the parameters of the video recording e.g, video resolution. We show that HD video is not needed to successfully lipread with a computer. The term "viseme" is used in machine lipreading to represent a visual cue or gesture which corresponds to a subgroup of phonemes where the phonemes are visually indistinguishable. A phoneme is the smallest sound one can utter, because there are more phonemes per viseme, maps between units show a many-to-one relationship. Many maps have been presented, we compare these and our results show Lee's is best. We propose a new method of speaker-dependent phoneme-to-viseme maps and compare these to Lee's. Our results show the sensitivity of phoneme clustering and we use our new knowledge to augment a conventional MLR system. It has been observed in MLR, that classifiers need training on test subjects to achieve accuracy. Thus machine lipreading is highly speaker-dependent. Conversely speaker independence is robust classification of non-training speakers. We investigate the dependence of phoneme-to-viseme maps between speakers and show there is not a high variability of visemes, but there is high variability in trajectory between visemes of individual speakers with the same ground truth. This implies a dependency upon the number of visemes within each set for each individual. We show that prior phoneme-to-viseme maps rarely have enough visemes and the optimal size, which varies by speaker, ranges from 11-35. Finally we decode from visemes back to phonemes and into words. Our novel approach uses the optimum range visemes within hierarchical training of phoneme classifiers and demonstrates a significant increase in classification accuracy.
* PhD thesis. Computer Vision and Pattern Recognition (CVPR), Women in Computer Vision (WiCV) Workshop 2017