 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLAniMAtion: LLAMA Driven Gesture Animation
May 13, 2024

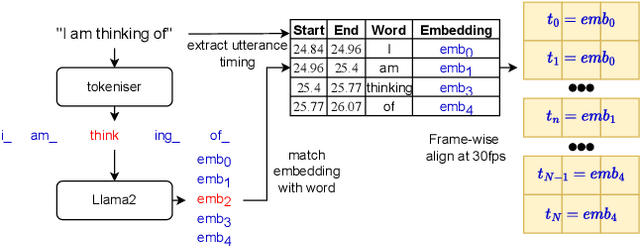

Co-speech gesturing is an important modality in conversation, providing context and social cues. In character animation, appropriate and synchronised gestures add realism, and can make interactive agents more engaging. Historically, methods for automatically generating gestures were predominantly audio-driven, exploiting the prosodic and speech-related content that is encoded in the audio signal. In this paper we instead experiment with using LLM features for gesture generation that are extracted from text using LLAMA2. We compare against audio features, and explore combining the two modalities in both objective tests and a user study. Surprisingly, our results show that LLAMA2 features on their own perform significantly better than audio features and that including both modalities yields no significant difference to using LLAMA2 features in isolation. We demonstrate that the LLAMA2 based model can generate both beat and semantic gestures without any audio input, suggesting LLMs can provide rich encodings that are well suited for gesture generation.
SUB-Depth: Self-distillation and Uncertainty Boosting Self-supervised Monocular Depth Estimation
Nov 19, 2021
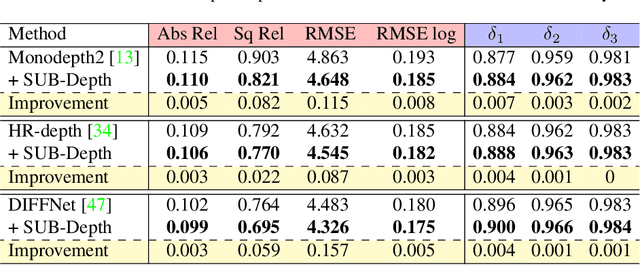
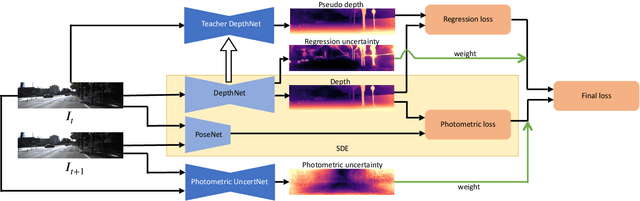
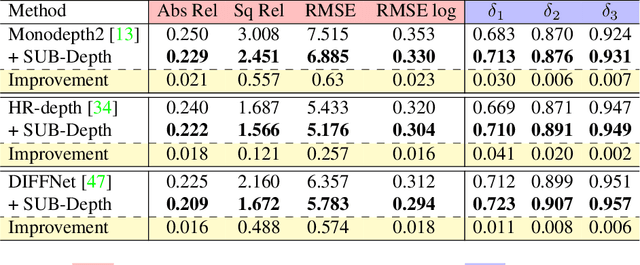
We propose SUB-Depth, a universal multi-task training framework for self-supervised monocular depth estimation (SDE). Depth models trained with SUB-Depth outperform the same models trained in a standard single-task SDE framework. By introducing an additional self-distillation task into a standard SDE training framework, SUB-Depth trains a depth network, not only to predict the depth map for an image reconstruction task, but also to distill knowledge from a trained teacher network with unlabelled data. To take advantage of this multi-task setting, we propose homoscedastic uncertainty formulations for each task to penalize areas likely to be affected by teacher network noise, or violate SDE assumptions. We present extensive evaluations on KITTI to demonstrate the improvements achieved by training a range of existing networks using the proposed framework, and we achieve state-of-the-art performance on this task. Additionally, SUB-Depth enables models to estimate uncertainty on depth output.
Self-Supervised Monocular Depth Estimation with Internal Feature Fusion
Oct 20, 2021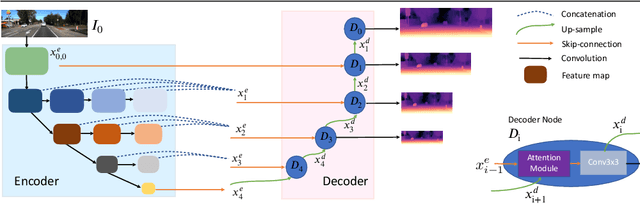
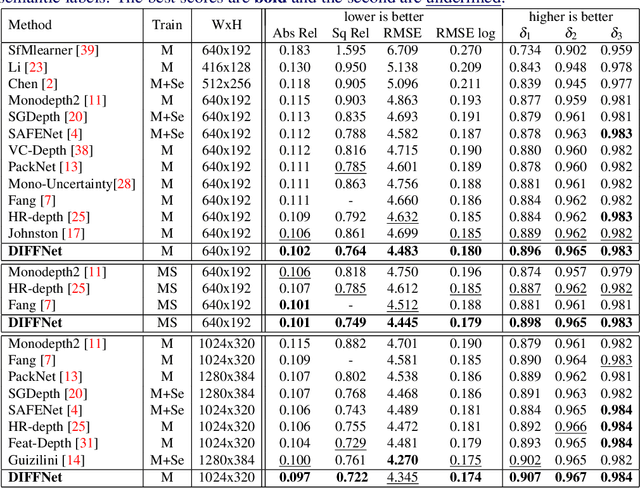

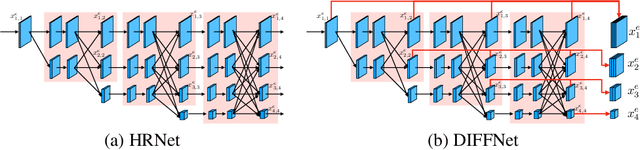
Self-supervised learning for depth estimation uses geometry in image sequences for supervision and shows promising results. Like many computer vision tasks, depth network performance is determined by the capability to learn accurate spatial and semantic representations from images. Therefore, it is natural to exploit semantic segmentation networks for depth estimation. In this work, based on a well-developed semantic segmentation network HRNet, we propose a novel depth estimation networkDIFFNet, which can make use of semantic information in down and upsampling procedures. By applying feature fusion and an attention mechanism, our proposed method outperforms the state-of-the-art monocular depth estimation methods on the KITTI benchmark. Our method also demonstrates greater potential on higher resolution training data. We propose an additional extended evaluation strategy by establishing a test set of challenging cases, empirically derived from the standard benchmark.
Visual speech recognition: aligning terminologies for better understanding
Oct 03, 2017



We are at an exciting time for machine lipreading. Traditional research stemmed from the adaptation of audio recognition systems. But now, the computer vision community is also participating. This joining of two previously disparate areas with different perspectives on computer lipreading is creating opportunities for collaborations, but in doing so the literature is experiencing challenges in knowledge sharing due to multiple uses of terms and phrases and the range of methods for scoring results. In particular we highlight three areas with the intention to improve communication between those researching lipreading; the effects of interchanging between speech reading and lipreading; speaker dependence across train, validation, and test splits; and the use of accuracy, correctness, errors, and varying units (phonemes, visemes, words, and sentences) to measure system performance. We make recommendations as to how we can be more consistent.