 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgefNeRF: High Quality Radiance Fields from Practical Cameras
Jun 15, 2024
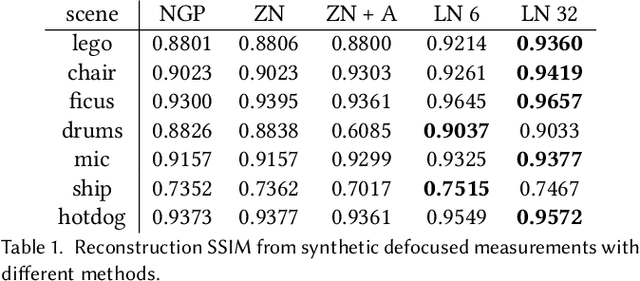

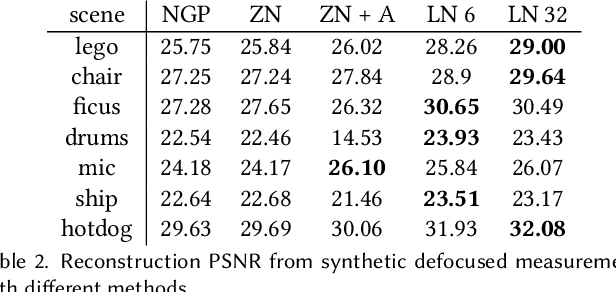
In recent years, the development of Neural Radiance Fields has enabled a previously unseen level of photo-realistic 3D reconstruction of scenes and objects from multi-view camera data. However, previous methods use an oversimplified pinhole camera model resulting in defocus blur being `baked' into the reconstructed radiance field. We propose a modification to the ray casting that leverages the optics of lenses to enhance scene reconstruction in the presence of defocus blur. This allows us to improve the quality of radiance field reconstructions from the measurements of a practical camera with finite aperture. We show that the proposed model matches the defocus blur behavior of practical cameras more closely than pinhole models and other approximations of defocus blur models, particularly in the presence of partial occlusions. This allows us to achieve sharper reconstructions, improving the PSNR on validation of all-in-focus images, on both synthetic and real datasets, by up to 3 dB.
LLAniMAtion: LLAMA Driven Gesture Animation
May 13, 2024

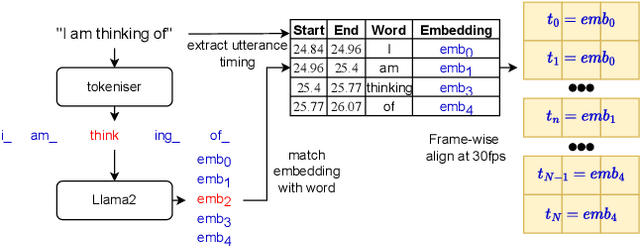

Co-speech gesturing is an important modality in conversation, providing context and social cues. In character animation, appropriate and synchronised gestures add realism, and can make interactive agents more engaging. Historically, methods for automatically generating gestures were predominantly audio-driven, exploiting the prosodic and speech-related content that is encoded in the audio signal. In this paper we instead experiment with using LLM features for gesture generation that are extracted from text using LLAMA2. We compare against audio features, and explore combining the two modalities in both objective tests and a user study. Surprisingly, our results show that LLAMA2 features on their own perform significantly better than audio features and that including both modalities yields no significant difference to using LLAMA2 features in isolation. We demonstrate that the LLAMA2 based model can generate both beat and semantic gestures without any audio input, suggesting LLMs can provide rich encodings that are well suited for gesture generation.
Personalized 3D Human Pose and Shape Refinement
Mar 18, 2024



Recently, regression-based methods have dominated the field of 3D human pose and shape estimation. Despite their promising results, a common issue is the misalignment between predictions and image observations, often caused by minor joint rotation errors that accumulate along the kinematic chain. To address this issue, we propose to construct dense correspondences between initial human model estimates and the corresponding images that can be used to refine the initial predictions. To this end, we utilize renderings of the 3D models to predict per-pixel 2D displacements between the synthetic renderings and the RGB images. This allows us to effectively integrate and exploit appearance information of the persons. Our per-pixel displacements can be efficiently transformed to per-visible-vertex displacements and then used for 3D model refinement by minimizing a reprojection loss. To demonstrate the effectiveness of our approach, we refine the initial 3D human mesh predictions of multiple models using different refinement procedures on 3DPW and RICH. We show that our approach not only consistently leads to better image-model alignment, but also to improved 3D accuracy.
* Accepted to 2023 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)
Structural Decompositions for End-to-End Relighting
Jun 07, 2019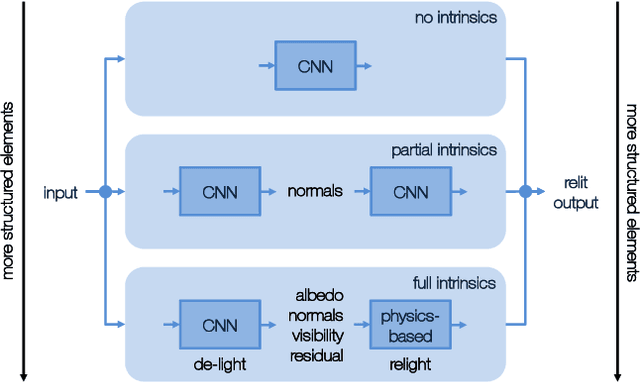
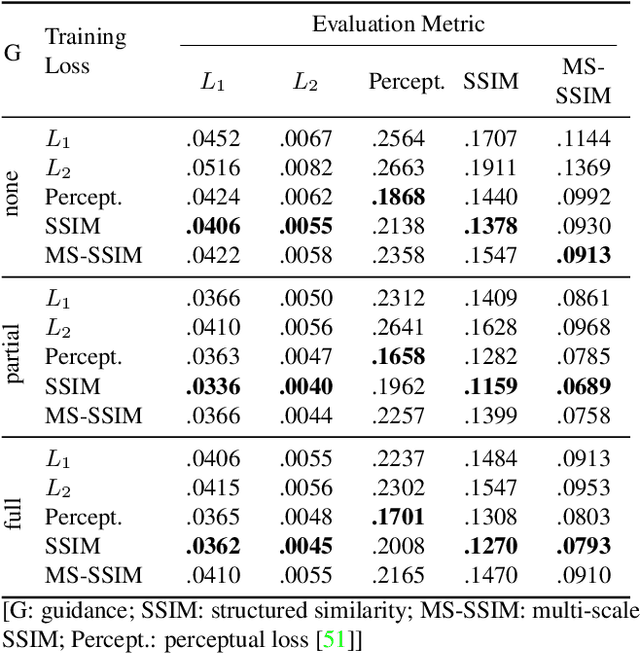

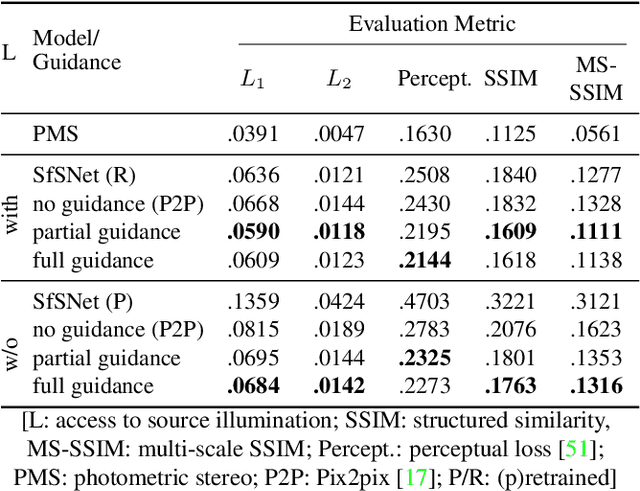
Relighting is an essential step in artificially transferring an object from one image into another environment. For example, a believable teleconference in Augmented Reality requires a portrait recorded in the source environment to be displayed and relit consistent with the light configuration of the destination scene. In this paper, we investigate architectures for learning to both de-light and relight an image of a human face end-to-end. The architectures vary in how much they enforce physically-based image formation and rendering constraints. The most structured model decomposes the input image into intrinsic components according to a diffuse physics-based image formation model and augments the render to relight including non-diffuse effects. An intermediate model uses fewer intrinsic constraints and the least structured model makes no assumptions on the image formation. To train our models and evaluate the approach, we collected portraits of 21 subjects with various expressions and poses, each in a sequence of 32 individual light sources in a controlled light stage setup. Our method leads to precise and believable relighting results in challenging illumination conditions and poses, including when the subject is facing away from the camera. We compare our method to state-of-the-art relighting approaches and illustrate its superiority in a series of quantitative and qualitative experiments.
Hand Keypoint Detection in Single Images using Multiview Bootstrapping
Apr 25, 2017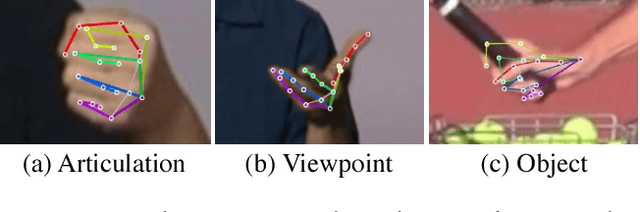
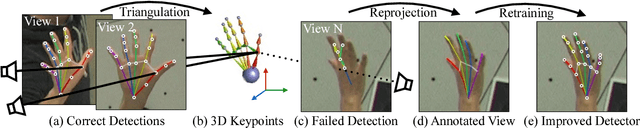
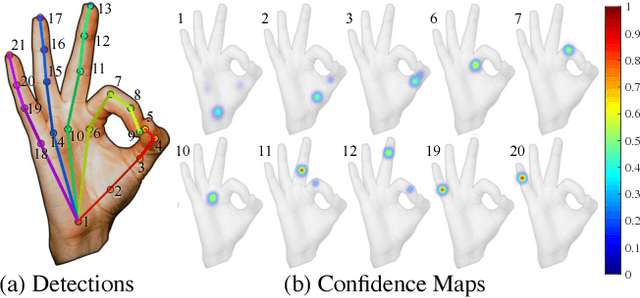
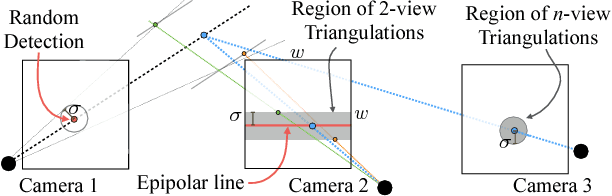
We present an approach that uses a multi-camera system to train fine-grained detectors for keypoints that are prone to occlusion, such as the joints of a hand. We call this procedure multiview bootstrapping: first, an initial keypoint detector is used to produce noisy labels in multiple views of the hand. The noisy detections are then triangulated in 3D using multiview geometry or marked as outliers. Finally, the reprojected triangulations are used as new labeled training data to improve the detector. We repeat this process, generating more labeled data in each iteration. We derive a result analytically relating the minimum number of views to achieve target true and false positive rates for a given detector. The method is used to train a hand keypoint detector for single images. The resulting keypoint detector runs in realtime on RGB images and has accuracy comparable to methods that use depth sensors. The single view detector, triangulated over multiple views, enables 3D markerless hand motion capture with complex object interactions.
Panoptic Studio: A Massively Multiview System for Social Interaction Capture
Dec 09, 2016



We present an approach to capture the 3D motion of a group of people engaged in a social interaction. The core challenges in capturing social interactions are: (1) occlusion is functional and frequent; (2) subtle motion needs to be measured over a space large enough to host a social group; (3) human appearance and configuration variation is immense; and (4) attaching markers to the body may prime the nature of interactions. The Panoptic Studio is a system organized around the thesis that social interactions should be measured through the integration of perceptual analyses over a large variety of view points. We present a modularized system designed around this principle, consisting of integrated structural, hardware, and software innovations. The system takes, as input, 480 synchronized video streams of multiple people engaged in social activities, and produces, as output, the labeled time-varying 3D structure of anatomical landmarks on individuals in the space. Our algorithm is designed to fuse the "weak" perceptual processes in the large number of views by progressively generating skeletal proposals from low-level appearance cues, and a framework for temporal refinement is also presented by associating body parts to reconstructed dense 3D trajectory stream. Our system and method are the first in reconstructing full body motion of more than five people engaged in social interactions without using markers. We also empirically demonstrate the impact of the number of views in achieving this goal.