 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUB-Depth: Self-distillation and Uncertainty Boosting Self-supervised Monocular Depth Estimation
Nov 19, 2021
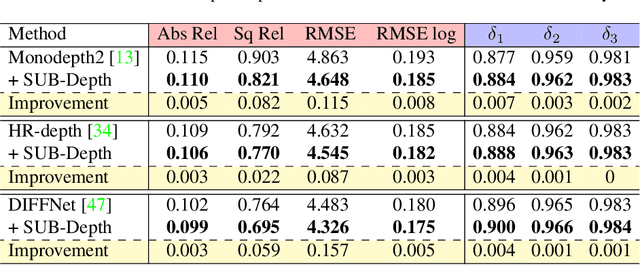
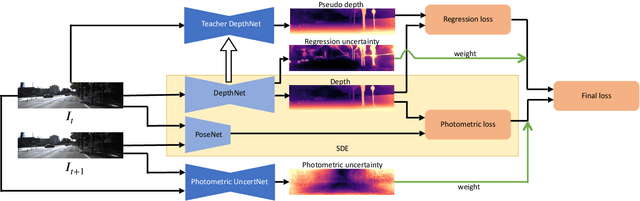
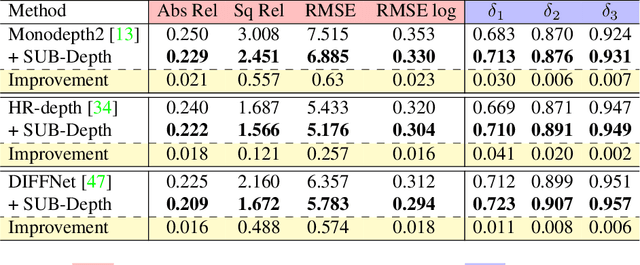
We propose SUB-Depth, a universal multi-task training framework for self-supervised monocular depth estimation (SDE). Depth models trained with SUB-Depth outperform the same models trained in a standard single-task SDE framework. By introducing an additional self-distillation task into a standard SDE training framework, SUB-Depth trains a depth network, not only to predict the depth map for an image reconstruction task, but also to distill knowledge from a trained teacher network with unlabelled data. To take advantage of this multi-task setting, we propose homoscedastic uncertainty formulations for each task to penalize areas likely to be affected by teacher network noise, or violate SDE assumptions. We present extensive evaluations on KITTI to demonstrate the improvements achieved by training a range of existing networks using the proposed framework, and we achieve state-of-the-art performance on this task. Additionally, SUB-Depth enables models to estimate uncertainty on depth output.
Self-Supervised Monocular Depth Estimation with Internal Feature Fusion
Oct 20, 2021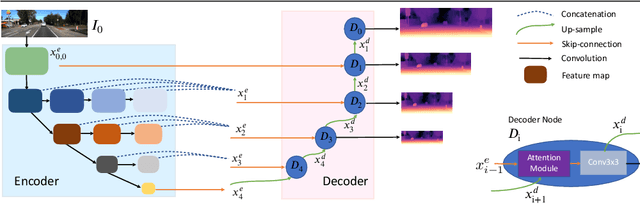
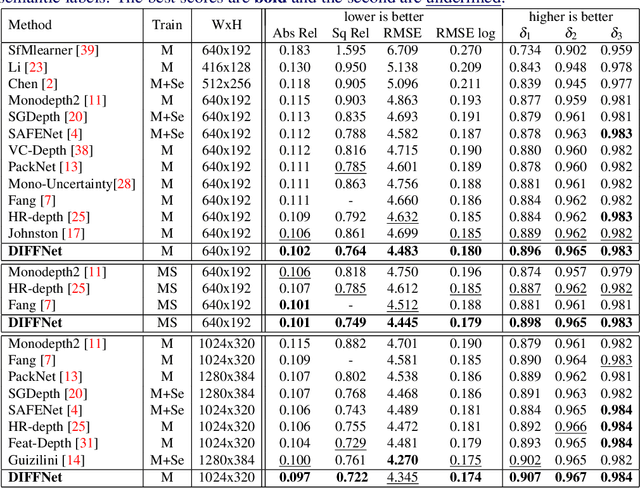

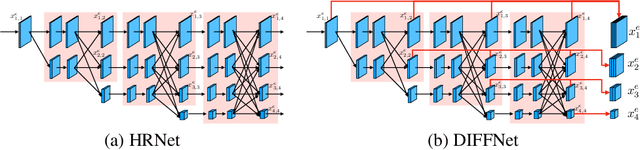
Self-supervised learning for depth estimation uses geometry in image sequences for supervision and shows promising results. Like many computer vision tasks, depth network performance is determined by the capability to learn accurate spatial and semantic representations from images. Therefore, it is natural to exploit semantic segmentation networks for depth estimation. In this work, based on a well-developed semantic segmentation network HRNet, we propose a novel depth estimation networkDIFFNet, which can make use of semantic information in down and upsampling procedures. By applying feature fusion and an attention mechanism, our proposed method outperforms the state-of-the-art monocular depth estimation methods on the KITTI benchmark. Our method also demonstrates greater potential on higher resolution training data. We propose an additional extended evaluation strategy by establishing a test set of challenging cases, empirically derived from the standard benchmark.