 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoneme-to-viseme mappings: the good, the bad, and the ugly
Paper and Code
May 08, 2018

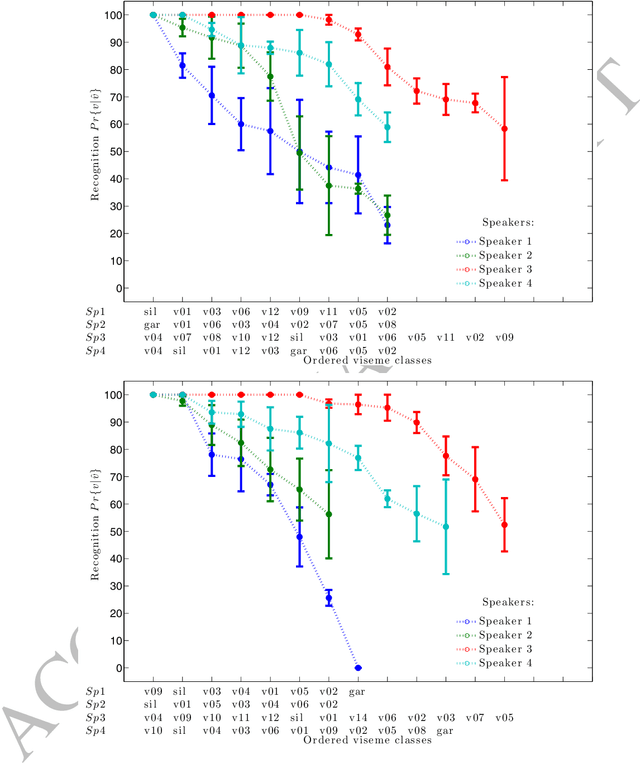

Visemes are the visual equivalent of phonemes. Although not precisely defined, a working definition of a viseme is "a set of phonemes which have identical appearance on the lips". Therefore a phoneme falls into one viseme class but a viseme may represent many phonemes: a many to one mapping. This mapping introduces ambiguity between phonemes when using viseme classifiers. Not only is this ambiguity damaging to the performance of audio-visual classifiers operating on real expressive speech, there is also considerable choice between possible mappings. In this paper we explore the issue of this choice of viseme-to-phoneme map. We show that there is definite difference in performance between viseme-to-phoneme mappings and explore why some maps appear to work better than others. We also devise a new algorithm for constructing phoneme-to-viseme mappings from labeled speech data. These new visemes, `Bear' visemes, are shown to perform better than previously known units.