 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn evaluation of data augmentation methods for sound scene geotagging
Oct 09, 2021
Sound scene geotagging is a new topic of research which has evolved from acoustic scene classification. It is motivated by the idea of audio surveillance. Not content with only describing a scene in a recording, a machine which can locate where the recording was captured would be of use to many. In this paper we explore a series of common audio data augmentation methods to evaluate which best improves the accuracy of audio geotagging classifiers. Our work improves on the state-of-the-art city geotagging method by 23% in terms of classification accuracy.
Visually Exploring Multi-Purpose Audio Data
Oct 09, 2021
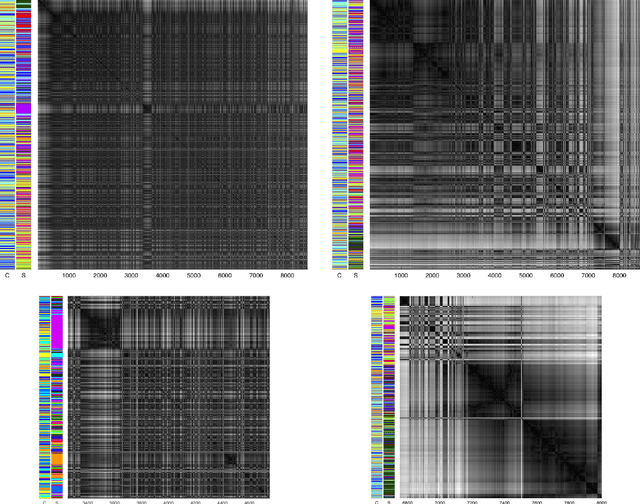


We analyse multi-purpose audio using tools to visualise similarities within the data that may be observed via unsupervised methods. The success of machine learning classifiers is affected by the information contained within system inputs, so we investigate whether latent patterns within the data may explain performance limitations of such classifiers. We use the visual assessment of cluster tendency (VAT) technique on a well known data set to observe how the samples naturally cluster, and we make comparisons to the labels used for audio geotagging and acoustic scene classification. We demonstrate that VAT helps to explain and corroborate confusions observed in prior work to classify this audio, yielding greater insight into the performance - and limitations - of supervised classification systems. While this exploratory analysis is conducted on data for which we know the "ground truth" labels, this method of visualising the natural groupings as dictated by the data leads to important questions about unlabelled data that can help the evaluation and realistic expectations of future (including self-supervised) classification systems.
Memory Controlled Sequential Self Attention for Sound Recognition
Jun 11, 2020


In this paper we investigate the importance of the extent of memory in sequential self attention for sound recognition. We propose to use a memory controlled sequential self attention mechanism on top of a convolutional recurrent neural network (CRNN) model for polyphonic sound event detection (SED). Experiments on the URBAN-SED dataset demonstrate the impact of the extent of memory on sound recognition performance with the self attention induced SED model. We extend the proposed idea with a multi-head self attention mechanism where each attention head processes the audio embedding with explicit attention width values. The proposed use of memory controlled sequential self attention offers a way to induce relations among frames of sound event tokens. We show that our memory controlled self attention model achieves an event based F -score of 33.92% on the URBAN-SED dataset, outperforming the F -score of 20.10% reported by the model without self attention.
The speaker-independent lipreading play-off; a survey of lipreading machines
Oct 24, 2018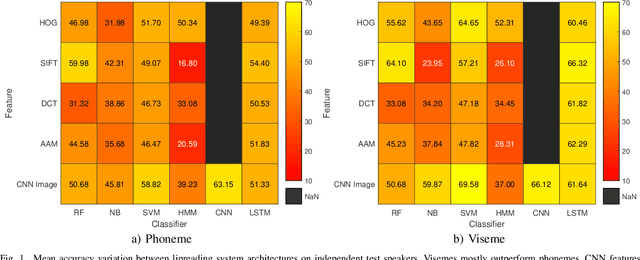
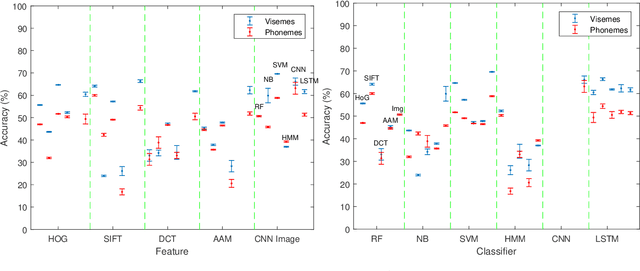

Lipreading is a difficult gesture classification task. One problem in computer lipreading is speaker-independence. Speaker-independence means to achieve the same accuracy on test speakers not included in the training set as speakers within the training set. Current literature is limited on speaker-independent lipreading, the few independent test speaker accuracy scores are usually aggregated within dependent test speaker accuracies for an averaged performance. This leads to unclear independent results. Here we undertake a systematic survey of experiments with the TCD-TIMIT dataset using both conventional approaches and deep learning methods to provide a series of wholly speaker-independent benchmarks and show that the best speaker-independent machine scores 69.58% accuracy with CNN features and an SVM classifier. This is less than state of the art speaker-dependent lipreading machines, but greater than previously reported in independence experiments.
Decoding visemes: improving machine lipreading
Oct 03, 2017

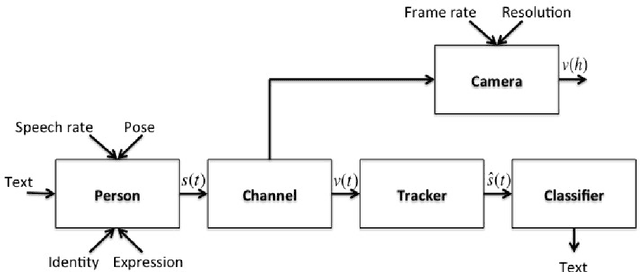

To undertake machine lip-reading, we try to recognise speech from a visual signal. Current work often uses viseme classification supported by language models with varying degrees of success. A few recent works suggest phoneme classification, in the right circumstances, can outperform viseme classification. In this work we present a novel two-pass method of training phoneme classifiers which uses previously trained visemes in the first pass. With our new training algorithm, we show classification performance which significantly improves on previous lip-reading results.
Finding phonemes: improving machine lip-reading
Oct 03, 2017



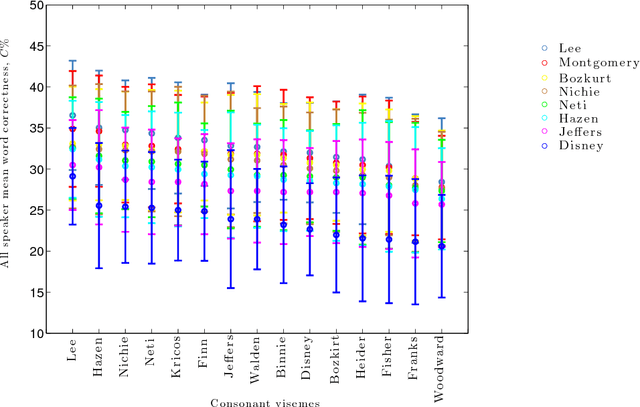
In machine lip-reading there is continued debate and research around the correct classes to be used for recognition. In this paper we use a structured approach for devising speaker-dependent viseme classes, which enables the creation of a set of phoneme-to-viseme maps where each has a different quantity of visemes ranging from two to 45. Viseme classes are based upon the mapping of articulated phonemes, which have been confused during phoneme recognition, into viseme groups. Using these maps, with the LiLIR dataset, we show the effect of changing the viseme map size in speaker-dependent machine lip-reading, measured by word recognition correctness and so demonstrate that word recognition with phoneme classifiers is not just possible, but often better than word recognition with viseme classifiers. Furthermore, there are intermediate units between visemes and phonemes which are better still.
Speaker-independent machine lip-reading with speaker-dependent viseme classifiers
Oct 03, 2017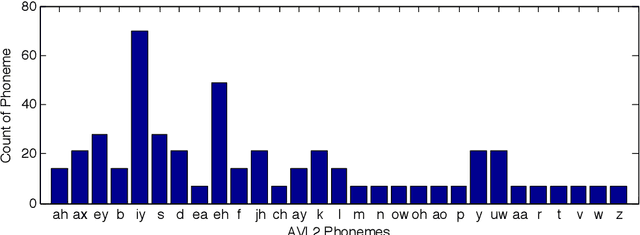
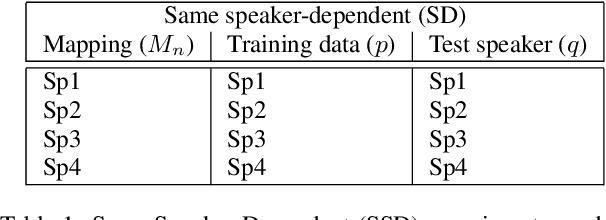
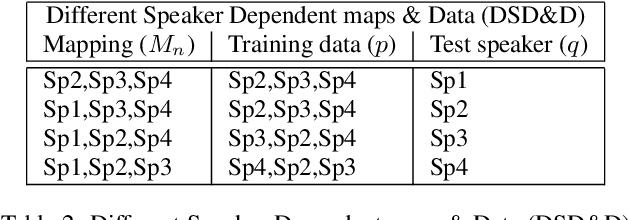
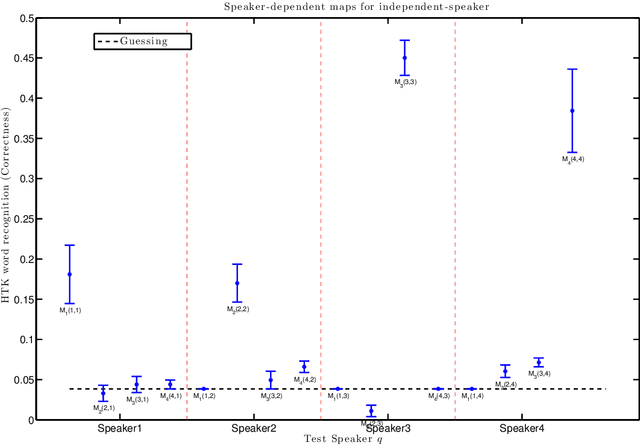
In machine lip-reading, which is identification of speech from visual-only information, there is evidence to show that visual speech is highly dependent upon the speaker [1]. Here, we use a phoneme-clustering method to form new phoneme-to-viseme maps for both individual and multiple speakers. We use these maps to examine how similarly speakers talk visually. We conclude that broadly speaking, speakers have the same repertoire of mouth gestures, where they differ is in the use of the gestures.
Which phoneme-to-viseme maps best improve visual-only computer lip-reading?
Oct 03, 2017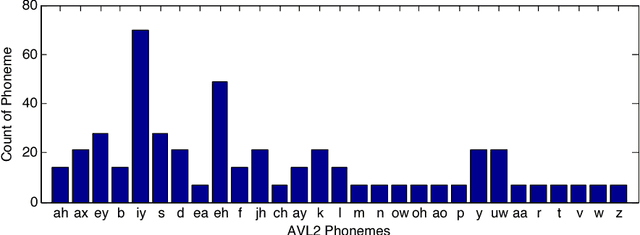


A critical assumption of all current visual speech recognition systems is that there are visual speech units called visemes which can be mapped to units of acoustic speech, the phonemes. Despite there being a number of published maps it is infrequent to see the effectiveness of these tested, particularly on visual-only lip-reading (many works use audio-visual speech). Here we examine 120 mappings and consider if any are stable across talkers. We show a method for devising maps based on phoneme confusions from an automated lip-reading system, and we present new mappings that show improvements for individual talkers.
Some observations on computer lip-reading: moving from the dream to the reality
Oct 03, 2017In the quest for greater computer lip-reading performance there are a number of tacit assumptions which are either present in the datasets (high resolution for example) or in the methods (recognition of spoken visual units called visemes for example). Here we review these and other assumptions and show the surprising result that computer lip-reading is not heavily constrained by video resolution, pose, lighting and other practical factors. However, the working assumption that visemes, which are the visual equivalent of phonemes, are the best unit for recognition does need further examination. We conclude that visemes, which were defined over a century ago, are unlikely to be optimal for a modern computer lip-reading system.
Resolution limits on visual speech recognition
Oct 03, 2017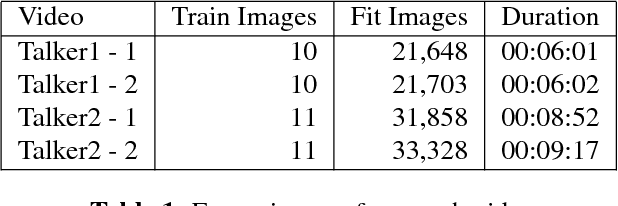

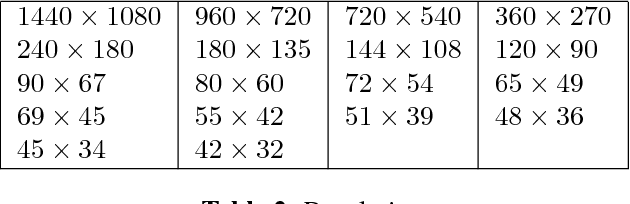
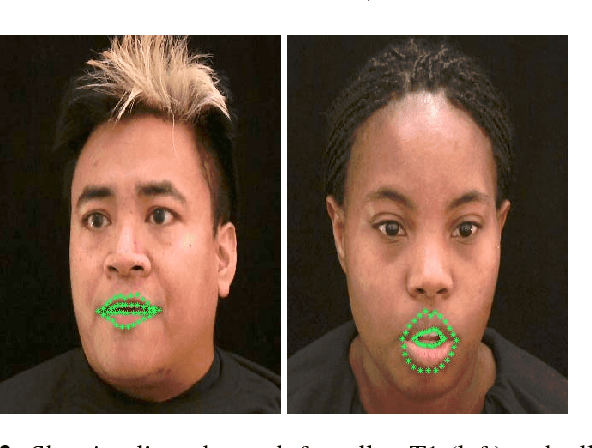
Visual-only speech recognition is dependent upon a number of factors that can be difficult to control, such as: lighting; identity; motion; emotion and expression. But some factors, such as video resolution are controllable, so it is surprising that there is not yet a systematic study of the effect of resolution on lip-reading. Here we use a new data set, the Rosetta Raven data, to train and test recognizers so we can measure the affect of video resolution on recognition accuracy. We conclude that, contrary to common practice, resolution need not be that great for automatic lip-reading. However it is highly unlikely that automatic lip-reading can work reliably when the distance between the bottom of the lower lip and the top of the upper lip is less than four pixels at rest.