 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeartbeat Detection from Ballistocardiogram using Transformer Network
Dec 18, 2024Longitudinal monitoring of heart rate (HR) and heart rate variability (HRV) can aid in tracking cardiovascular diseases (CVDs), sleep quality, sleep disorders, and reflect autonomic nervous system activity, stress levels, and overall well-being. These metrics are valuable in both clinical and everyday settings. In this paper, we present a transformer network aimed primarily at detecting the precise timing of heart beats from predicted electrocardiogram (ECG), derived from input Ballistocardiogram (BCG). We compared the performance of segment and subject models across three datasets: a lab dataset with 46 young subjects, an elder dataset with 28 elderly adults, and a combined dataset. The segment model demonstrated superior performance, with correlation coefficients of 0.97 for HR and mean heart beat interval (MHBI) when compared to ground truth. This non-invasive method offers significant potential for long-term, in-home HR and HRV monitoring, aiding in the early indication and prevention of cardiovascular issues.
Visually Exploring Multi-Purpose Audio Data
Oct 09, 2021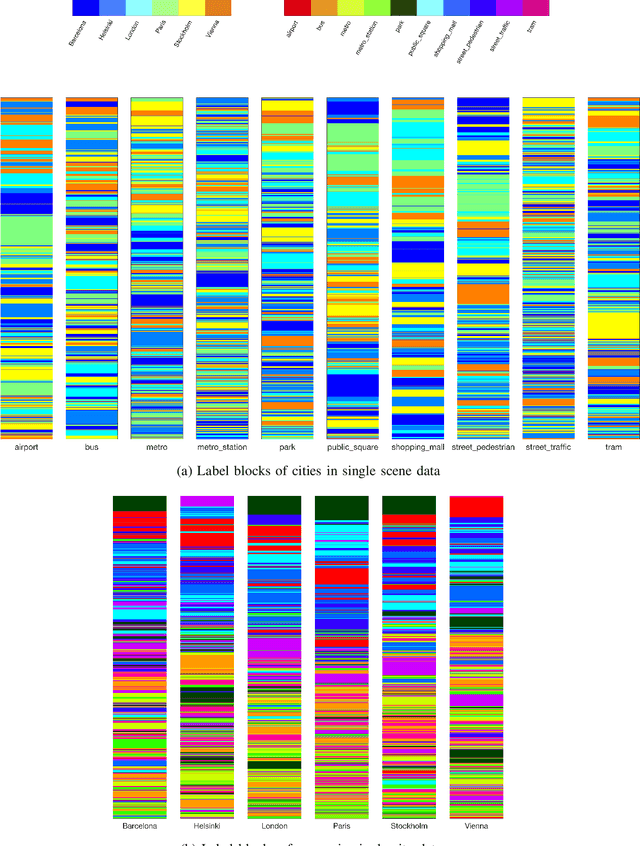
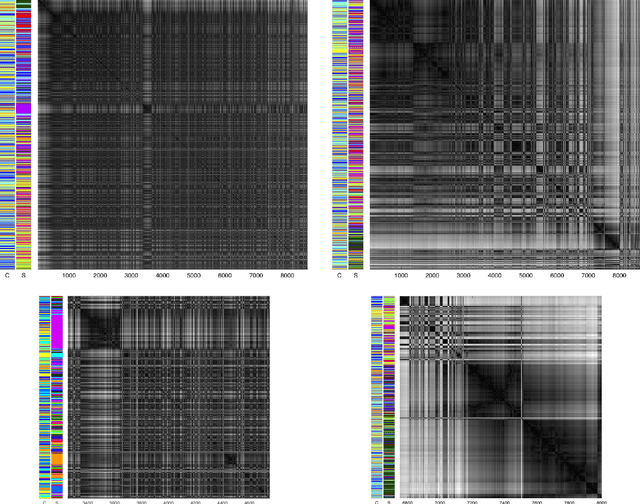


We analyse multi-purpose audio using tools to visualise similarities within the data that may be observed via unsupervised methods. The success of machine learning classifiers is affected by the information contained within system inputs, so we investigate whether latent patterns within the data may explain performance limitations of such classifiers. We use the visual assessment of cluster tendency (VAT) technique on a well known data set to observe how the samples naturally cluster, and we make comparisons to the labels used for audio geotagging and acoustic scene classification. We demonstrate that VAT helps to explain and corroborate confusions observed in prior work to classify this audio, yielding greater insight into the performance - and limitations - of supervised classification systems. While this exploratory analysis is conducted on data for which we know the "ground truth" labels, this method of visualising the natural groupings as dictated by the data leads to important questions about unlabelled data that can help the evaluation and realistic expectations of future (including self-supervised) classification systems.