Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich phoneme-to-viseme maps best improve visual-only computer lip-reading?
Paper and Code
Oct 03, 2017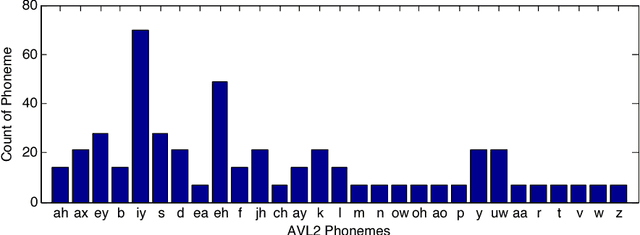


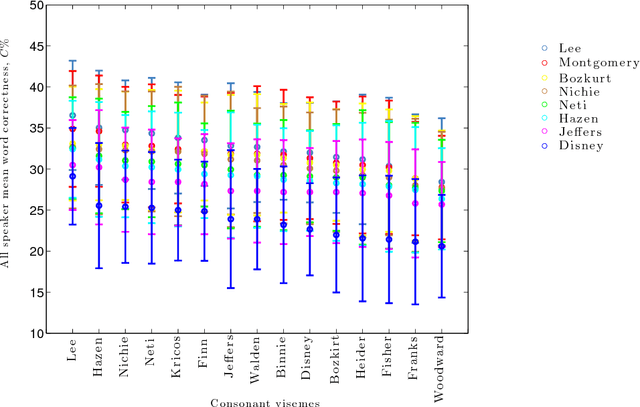
A critical assumption of all current visual speech recognition systems is that there are visual speech units called visemes which can be mapped to units of acoustic speech, the phonemes. Despite there being a number of published maps it is infrequent to see the effectiveness of these tested, particularly on visual-only lip-reading (many works use audio-visual speech). Here we examine 120 mappings and consider if any are stable across talkers. We show a method for devising maps based on phoneme confusions from an automated lip-reading system, and we present new mappings that show improvements for individual talkers.
* Helen L. Bear, Richard W. Harvey, Barry-John Theobald, and Yuxuan
Lan. Which phoneme-to-viseme maps best improve visual-only computer
lip-reading? Advances in Visual Computing 2014. p230-239
View paper on