 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe speaker-independent lipreading play-off; a survey of lipreading machines
Paper and Code
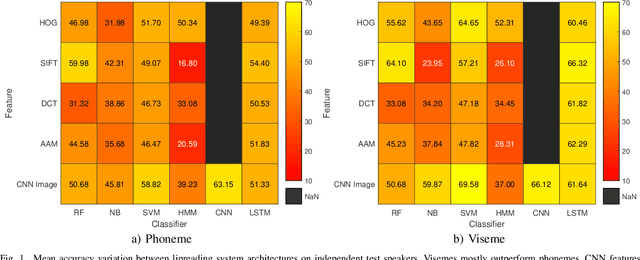
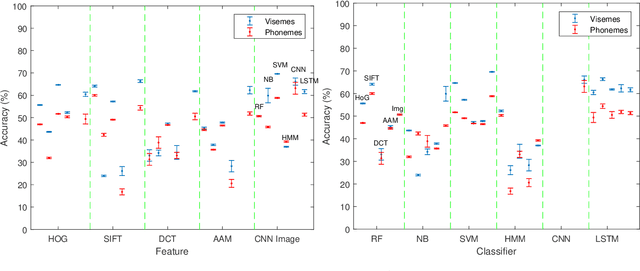

Lipreading is a difficult gesture classification task. One problem in computer lipreading is speaker-independence. Speaker-independence means to achieve the same accuracy on test speakers not included in the training set as speakers within the training set. Current literature is limited on speaker-independent lipreading, the few independent test speaker accuracy scores are usually aggregated within dependent test speaker accuracies for an averaged performance. This leads to unclear independent results. Here we undertake a systematic survey of experiments with the TCD-TIMIT dataset using both conventional approaches and deep learning methods to provide a series of wholly speaker-independent benchmarks and show that the best speaker-independent machine scores 69.58% accuracy with CNN features and an SVM classifier. This is less than state of the art speaker-dependent lipreading machines, but greater than previously reported in independence experiments.