Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker-independent machine lip-reading with speaker-dependent viseme classifiers
Oct 03, 2017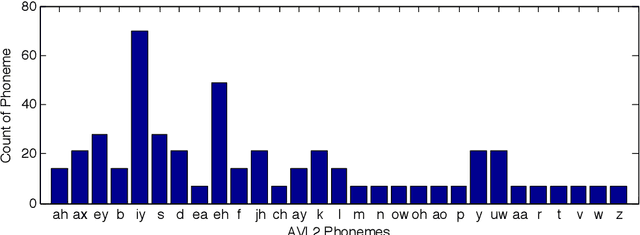
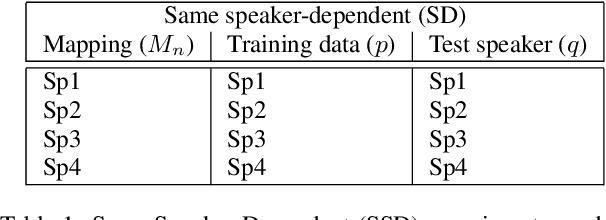
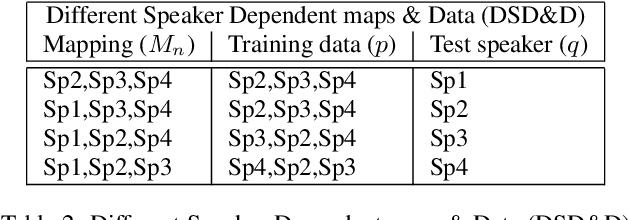
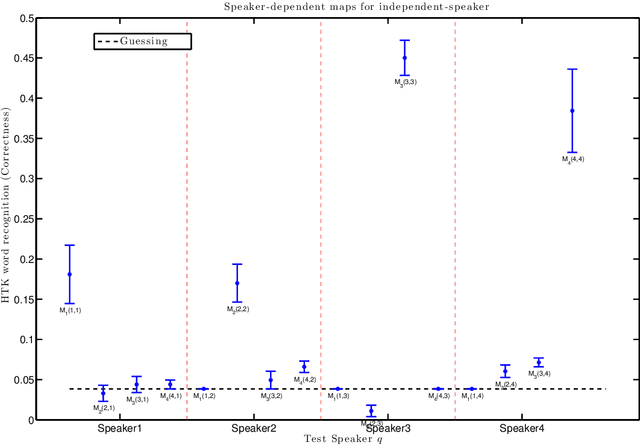
In machine lip-reading, which is identification of speech from visual-only information, there is evidence to show that visual speech is highly dependent upon the speaker [1]. Here, we use a phoneme-clustering method to form new phoneme-to-viseme maps for both individual and multiple speakers. We use these maps to examine how similarly speakers talk visually. We conclude that broadly speaking, speakers have the same repertoire of mouth gestures, where they differ is in the use of the gestures.
* Helen L. Bear, Stephen J. Cox, Richard W. Harvey,
Speaker-independent machine lip-reading with speaker-dependent viseme
classifiers. Audio-Visual Speech Processing (AVSP) 2015, p190-195
Via