 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeaeon: a Python toolkit for learning from time series
Jun 20, 2024aeon is a unified Python 3 library for all machine learning tasks involving time series. The package contains modules for time series forecasting, classification, extrinsic regression and clustering, as well as a variety of utilities, transformations and distance measures designed for time series data. aeon also has a number of experimental modules for tasks such as anomaly detection, similarity search and segmentation. aeon follows the scikit-learn API as much as possible to help new users and enable easy integration of aeon estimators with useful tools such as model selection and pipelines. It provides a broad library of time series algorithms, including efficient implementations of the very latest advances in research. Using a system of optional dependencies, aeon integrates a wide variety of packages into a single interface while keeping the core framework with minimal dependencies. The package is distributed under the 3-Clause BSD license and is available at https://github.com/ aeon-toolkit/aeon. This version was submitted to the JMLR journal on 02 Nov 2023 for v0.5.0 of aeon. At the time of this preprint aeon has released v0.9.0, and has had substantial changes.
Unsupervised Feature Based Algorithms for Time Series Extrinsic Regression
May 02, 2023Time Series Extrinsic Regression (TSER) involves using a set of training time series to form a predictive model of a continuous response variable that is not directly related to the regressor series. The TSER archive for comparing algorithms was released in 2022 with 19 problems. We increase the size of this archive to 63 problems and reproduce the previous comparison of baseline algorithms. We then extend the comparison to include a wider range of standard regressors and the latest versions of TSER models used in the previous study. We show that none of the previously evaluated regressors can outperform a regression adaptation of a standard classifier, rotation forest. We introduce two new TSER algorithms developed from related work in time series classification. FreshPRINCE is a pipeline estimator consisting of a transform into a wide range of summary features followed by a rotation forest regressor. DrCIF is a tree ensemble that creates features from summary statistics over random intervals. Our study demonstrates that both algorithms, along with InceptionTime, exhibit significantly better performance compared to the other 18 regressors tested. More importantly, these two proposals (DrCIF and FreshPRINCE) models are the only ones that significantly outperform the standard rotation forest regressor.
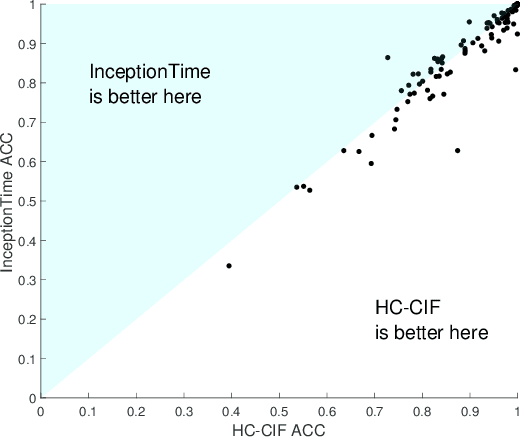
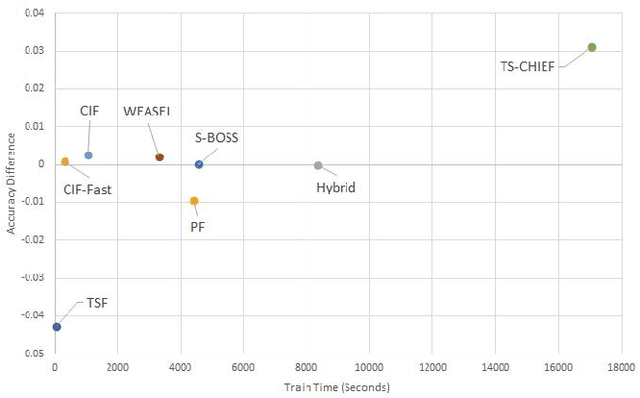
Bake off redux: a review and experimental evaluation of recent time series classification algorithms
Apr 25, 2023In 2017, a research paper compared 18 Time Series Classification (TSC) algorithms on 85 datasets from the University of California, Riverside (UCR) archive. This study, commonly referred to as a `bake off', identified that only nine algorithms performed significantly better than the Dynamic Time Warping (DTW) and Rotation Forest benchmarks that were used. The study categorised each algorithm by the type of feature they extract from time series data, forming a taxonomy of five main algorithm types. This categorisation of algorithms alongside the provision of code and accessible results for reproducibility has helped fuel an increase in popularity of the TSC field. Over six years have passed since this bake off, the UCR archive has expanded to 112 datasets and there have been a large number of new algorithms proposed. We revisit the bake off, seeing how each of the proposed categories have advanced since the original publication, and evaluate the performance of newer algorithms against the previous best-of-category using an expanded UCR archive. We extend the taxonomy to include three new categories to reflect recent developments. Alongside the originally proposed distance, interval, shapelet, dictionary and hybrid based algorithms, we compare newer convolution and feature based algorithms as well as deep learning approaches. We introduce 30 classification datasets either recently donated to the archive or reformatted to the TSC format, and use these to further evaluate the best performing algorithm from each category. Overall, we find that two recently proposed algorithms, Hydra+MultiROCKET and HIVE-COTEv2, perform significantly better than other approaches on both the current and new TSC problems.
A Review and Evaluation of Elastic Distance Functions for Time Series Clustering
May 30, 2022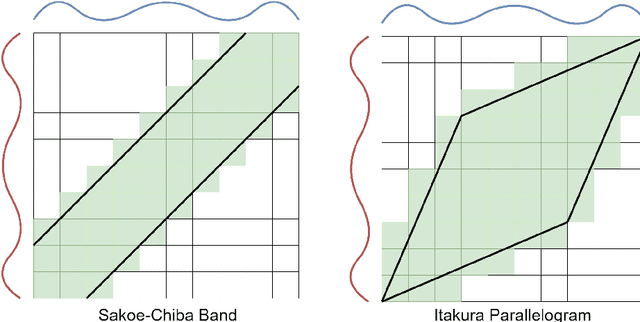
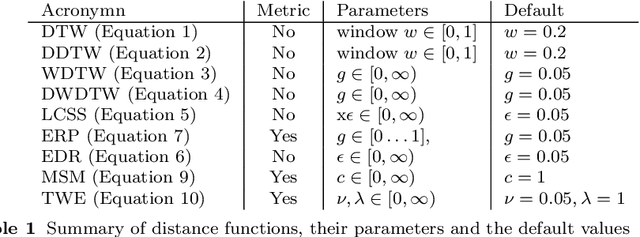
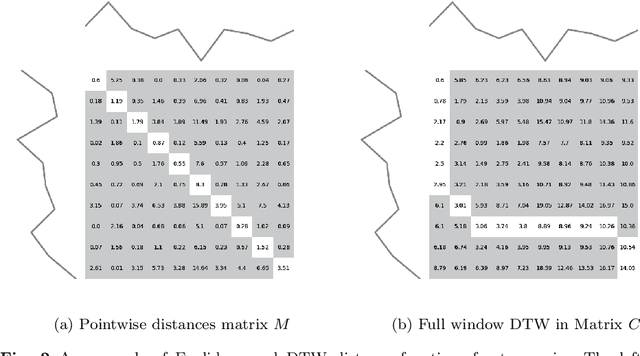
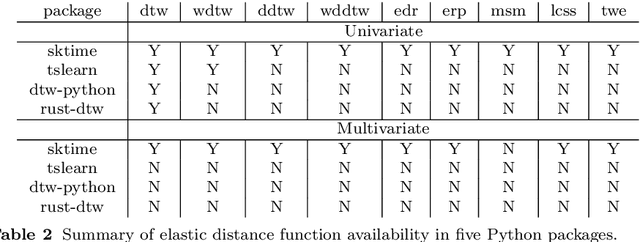
Time series clustering is the act of grouping time series data without recourse to a label. Algorithms that cluster time series can be classified into two groups: those that employ a time series specific distance measure; and those that derive features from time series. Both approaches usually rely on traditional clustering algorithms such as $k$-means. Our focus is on distance based time series that employ elastic distance measures, i.e. distances that perform some kind of realignment whilst measuring distance. We describe nine commonly used elastic distance measures and compare their performance with k-means and k-medoids clustering. Our findings are surprising. The most popular technique, dynamic time warping (DTW), performs worse than Euclidean distance with k-means, and even when tuned, is no better. Using k-medoids rather than k-means improved the clusterings for all nine distance measures. DTW is not significantly better than Euclidean distance with k-medoids. Generally, distance measures that employ editing in conjunction with warping perform better, and one distance measure, the move-split-merge (MSM) method, is the best performing measure of this study. We also compare to clustering with DTW using barycentre averaging (DBA). We find that DBA does improve DTW k-means, but that the standard DBA is still worse than using MSM. Our conclusion is to recommend MSM with k-medoids as the benchmark algorithm for clustering time series with elastic distance measures. We provide implementations, results and guidance on reproducing results on the associated GitHub repository.
The FreshPRINCE: A Simple Transformation Based Pipeline Time Series Classifier
Jan 28, 2022
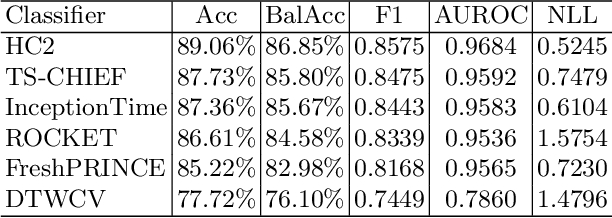
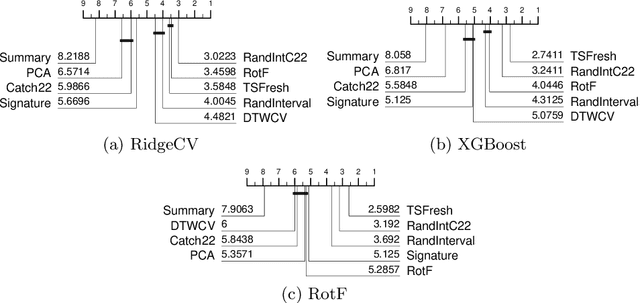

There have recently been significant advances in the accuracy of algorithms proposed for time series classification (TSC). However, a commonly asked question by real world practitioners and data scientists less familiar with the research topic, is whether the complexity of the algorithms considered state of the art is really necessary. Many times the first approach suggested is a simple pipeline of summary statistics or other time series feature extraction approaches such as TSFresh, which in itself is a sensible question; in publications on TSC algorithms generalised for multiple problem types, we rarely see these approaches considered or compared against. We experiment with basic feature extractors using vector based classifiers shown to be effective with continuous attributes in current state-of-the-art time series classifiers. We test these approaches on the UCR time series dataset archive, looking to see if TSC literature has overlooked the effectiveness of these approaches. We find that a pipeline of TSFresh followed by a rotation forest classifier, which we name FreshPRINCE, performs best. It is not state of the art, but it is significantly more accurate than nearest neighbour with dynamic time warping, and represents a reasonable benchmark for future comparison.
The Temporal Dictionary Ensemble (TDE) Classifier for Time Series Classification
May 09, 2021


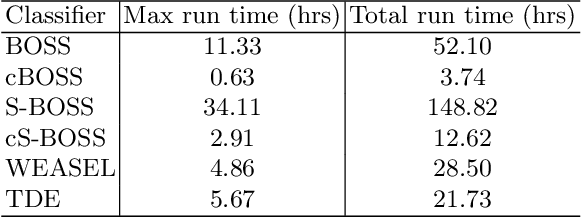
Using bag of words representations of time series is a popular approach to time series classification. These algorithms involve approximating and discretising windows over a series to form words, then forming a count of words over a given dictionary. Classifiers are constructed on the resulting histograms of word counts. A 2017 evaluation of a range of time series classifiers found the bag of symbolic-fourier approximation symbols (BOSS) ensemble the best of the dictionary based classifiers. It forms one of the components of hierarchical vote collective of transformation-based ensembles (HIVE-COTE), which represents the current state of the art. Since then, several new dictionary based algorithms have been proposed that are more accurate or more scalable (or both) than BOSS. We propose a further extension of these dictionary based classifiers that combines the best elements of the others combined with a novel approach to constructing ensemble members based on an adaptive Gaussian process model of the parameter space. We demonstrate that the temporal dictionary ensemble (TDE) is more accurate than other dictionary based approaches. Furthermore, unlike the other classifiers, if we replace BOSS in HIVE-COTE with TDE, HIVE-COTE is significantly more accurate. We also show this new version of HIVE-COTE is significantly more accurate than the current best deep learning approach, a recently proposed hybrid tree ensemble and a recently introduced competitive classifier making use of highly randomised convolutional kernels. This advance represents a new state of the art for time series classification.
* arXiv admin note: text overlap with arXiv:1911.12008
HIVE-COTE 2.0: a new meta ensemble for time series classification
Apr 15, 2021



The Hierarchical Vote Collective of Transformation-based Ensembles (HIVE-COTE) is a heterogeneous meta ensemble for time series classification. HIVE-COTE forms its ensemble from classifiers of multiple domains, including phase-independent shapelets, bag-of-words based dictionaries and phase-dependent intervals. Since it was first proposed in 2016, the algorithm has remained state of the art for accuracy on the UCR time series classification archive. Over time it has been incrementally updated, culminating in its current state, HIVE-COTE 1.0. During this time a number of algorithms have been proposed which match the accuracy of HIVE-COTE. We propose comprehensive changes to the HIVE-COTE algorithm which significantly improve its accuracy and usability, presenting this upgrade as HIVE-COTE 2.0. We introduce two novel classifiers, the Temporal Dictionary Ensemble (TDE) and Diverse Representation Canonical Interval Forest (DrCIF), which replace existing ensemble members. Additionally, we introduce the Arsenal, an ensemble of ROCKET classifiers as a new HIVE-COTE 2.0 constituent. We demonstrate that HIVE-COTE 2.0 is significantly more accurate than the current state of the art on 112 univariate UCR archive datasets and 26 multivariate UEA archive datasets.
The Canonical Interval Forest (CIF) Classifier for Time Series Classification
Aug 20, 2020

Time series classification (TSC) is home to a number of algorithm groups that utilise different kinds of discriminatory patterns. One of these groups describes classifiers that predict using phase dependant intervals. The time series forest (TSF) classifier is one of the most well known interval methods, and has demonstrated strong performance as well as relative speed in training and predictions. However, recent advances in other approaches have left TSF behind. TSF originally summarises intervals using three simple summary statistics. The `catch22' feature set of 22 time series features was recently proposed to aid time series analysis through a concise set of diverse and informative descriptive characteristics. We propose combining TSF and catch22 to form a new classifier, the Canonical Interval Forest (CIF). We outline additional enhancements to the training procedure, and extend the classifier to include multivariate classification capabilities. We demonstrate a large and significant improvement in accuracy over both TSF and catch22, and show it to be on par with top performers from other algorithmic classes. By upgrading the interval-based component from TSF to CIF, we also demonstrate a significant improvement in the hierarchical vote collective of transformation-based ensembles (HIVE-COTE) that combines different time series representations. HIVE-COTE using CIF is significantly more accurate on the UCR archive than any other classifier we are aware of and represents a new state of the art for TSC.
A tale of two toolkits, report the third: on the usage and performance of HIVE-COTE v1.0
Apr 25, 2020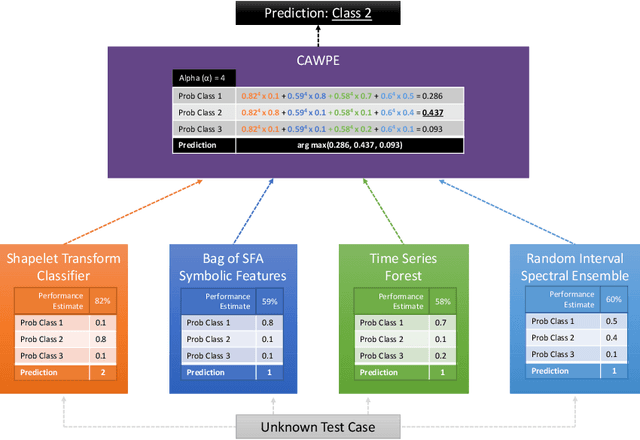
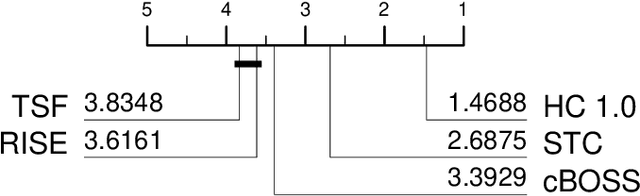
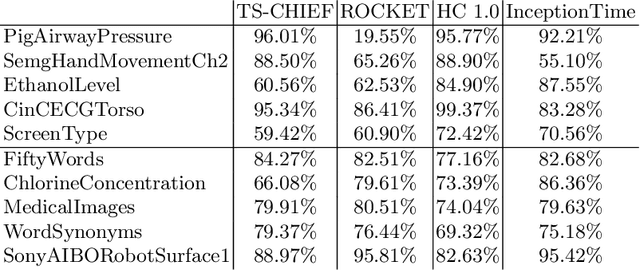

The Hierarchical Vote Collective of Transformation-based Ensembles (HIVE-COTE) is a heterogeneous meta ensemble for time series classification. Since it was first proposed in 2016, the algorithm has undergone some minor changes and there is now a configurable, scalable and easy to use version available in two open source repositories. We present an overview of the latest stable HIVE-COTE, version 1.0, and describe how it differs to the original. We provide a walkthrough guide of how to use the classifier, and conduct extensive experimental evaluation of its predictive performance and resource usage. We compare the performance of HIVE-COTE to three recently proposed algorithms.
A tale of two toolkits, report the second: bake off redux. Chapter 1. dictionary based classifiers
Nov 27, 2019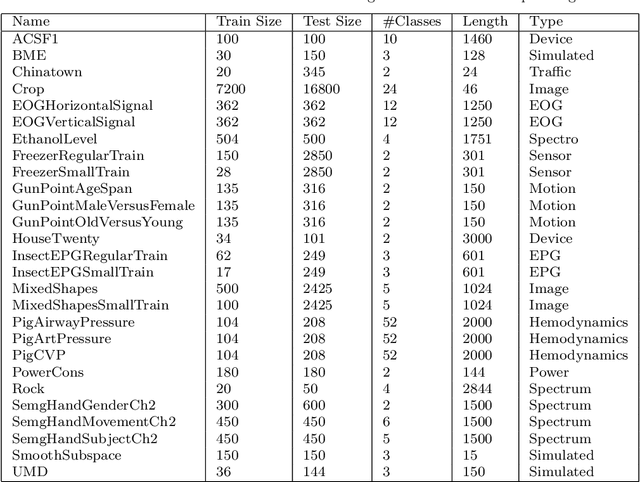


Time series classification (TSC) is the problem of learning labels from time dependent data. One class of algorithms is derived from a bag of words approach. A window is run along a series, the subseries is shortened and discretised to form a word, then features are formed from the histogram of frequency of occurrence of words. We call this type of approach to TSC dictionary based classification. We compare four dictionary based algorithms in the context of a wider project to update the great time series classification bakeoff, a comparative study published in 2017. We experimentally characterise the algorithms in terms of predictive performance, time complexity and space complexity. We find that we can improve on the previous best in terms of accuracy, but this comes at the cost of time and space. Alternatively, the same performance can be achieved with far less cost. We review the relative merits of the four algorithms before suggesting a path to possible improvement.