 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA tale of two toolkits, report the second: bake off redux. Chapter 1. dictionary based classifiers
Paper and Code
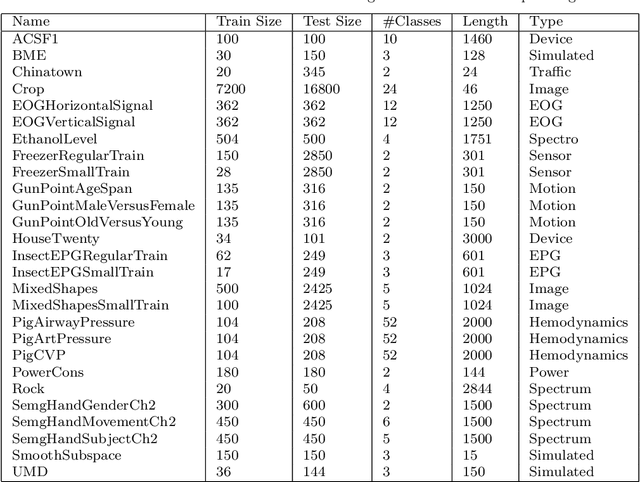


Time series classification (TSC) is the problem of learning labels from time dependent data. One class of algorithms is derived from a bag of words approach. A window is run along a series, the subseries is shortened and discretised to form a word, then features are formed from the histogram of frequency of occurrence of words. We call this type of approach to TSC dictionary based classification. We compare four dictionary based algorithms in the context of a wider project to update the great time series classification bakeoff, a comparative study published in 2017. We experimentally characterise the algorithms in terms of predictive performance, time complexity and space complexity. We find that we can improve on the previous best in terms of accuracy, but this comes at the cost of time and space. Alternatively, the same performance can be achieved with far less cost. We review the relative merits of the four algorithms before suggesting a path to possible improvement.