 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Temporal Dictionary Ensemble (TDE) Classifier for Time Series Classification
May 09, 2021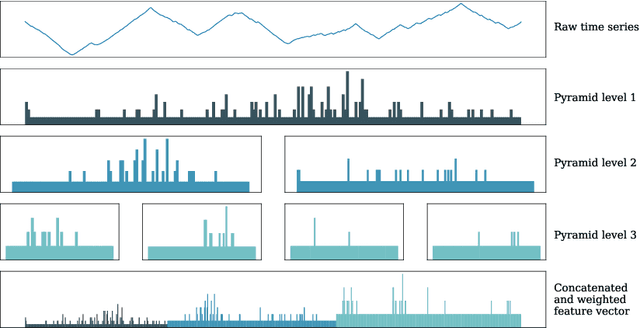


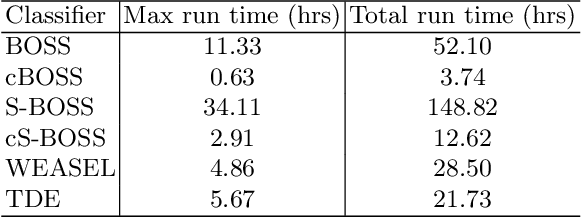
Using bag of words representations of time series is a popular approach to time series classification. These algorithms involve approximating and discretising windows over a series to form words, then forming a count of words over a given dictionary. Classifiers are constructed on the resulting histograms of word counts. A 2017 evaluation of a range of time series classifiers found the bag of symbolic-fourier approximation symbols (BOSS) ensemble the best of the dictionary based classifiers. It forms one of the components of hierarchical vote collective of transformation-based ensembles (HIVE-COTE), which represents the current state of the art. Since then, several new dictionary based algorithms have been proposed that are more accurate or more scalable (or both) than BOSS. We propose a further extension of these dictionary based classifiers that combines the best elements of the others combined with a novel approach to constructing ensemble members based on an adaptive Gaussian process model of the parameter space. We demonstrate that the temporal dictionary ensemble (TDE) is more accurate than other dictionary based approaches. Furthermore, unlike the other classifiers, if we replace BOSS in HIVE-COTE with TDE, HIVE-COTE is significantly more accurate. We also show this new version of HIVE-COTE is significantly more accurate than the current best deep learning approach, a recently proposed hybrid tree ensemble and a recently introduced competitive classifier making use of highly randomised convolutional kernels. This advance represents a new state of the art for time series classification.
* arXiv admin note: text overlap with arXiv:1911.12008
Nested cross-validation when selecting classifiers is overzealous for most practical applications
Sep 25, 2018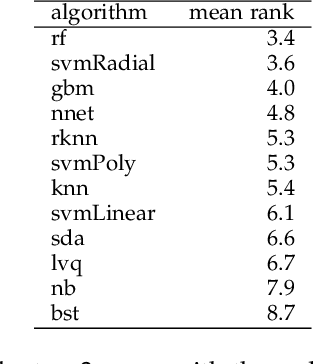



When selecting a classification algorithm to be applied to a particular problem, one has to simultaneously select the best algorithm for that dataset \emph{and} the best set of hyperparameters for the chosen model. The usual approach is to apply a nested cross-validation procedure; hyperparameter selection is performed in the inner cross-validation, while the outer cross-validation computes an unbiased estimate of the expected accuracy of the algorithm \emph{with cross-validation based hyperparameter tuning}. The alternative approach, which we shall call `flat cross-validation', uses a single cross-validation step both to select the optimal hyperparameter values and to provide an estimate of the expected accuracy of the algorithm, that while biased may nevertheless still be used to select the best learning algorithm. We tested both procedures using 12 different algorithms on 115 real life binary datasets and conclude that using the less computationally expensive flat cross-validation procedure will generally result in the selection of an algorithm that is, for all practical purposes, of similar quality to that selected via nested cross-validation, provided the learning algorithms have relatively few hyperparameters to be optimised.