 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLaP -- State Detection from Time Series
Apr 02, 2025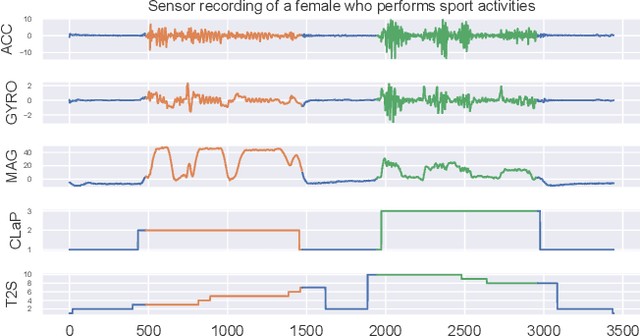
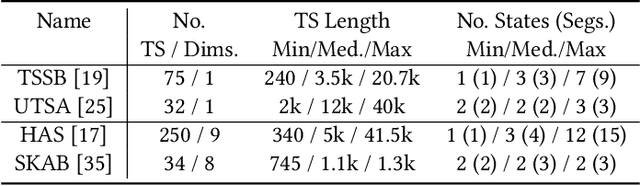
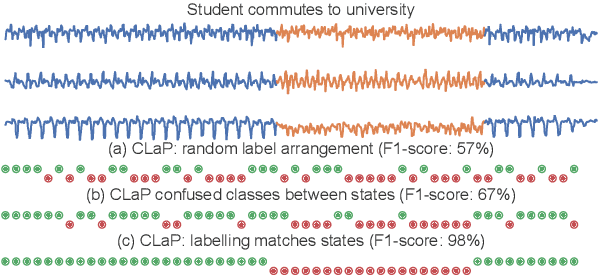
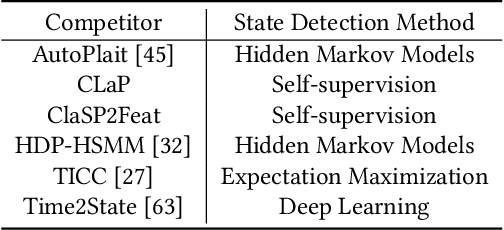
The ever-growing amount of sensor data from machines, smart devices, and the environment leads to an abundance of high-resolution, unannotated time series (TS). These recordings encode the recognizable properties of latent states and transitions from physical phenomena that can be modelled as abstract processes. The unsupervised localization and identification of these states and their transitions is the task of time series state detection (TSSD). We introduce CLaP, a new, highly accurate and efficient algorithm for TSSD. It leverages the predictive power of time series classification for TSSD in an unsupervised setting by applying novel self-supervision techniques to detect whether data segments emerge from the same state or not. To this end, CLaP cross-validates a classifier with segment-labelled subsequences to quantify confusion between segments. It merges labels from segments with high confusion, representing the same latent state, if this leads to an increase in overall classification quality. We conducted an experimental evaluation using 391 TS from four benchmarks and found CLaP to be significantly more precise in detecting states than five state-of-the-art competitors. It achieves the best accuracy-runtime tradeoff and is scalable to large TS. We provide a Python implementation of CLaP, which can be deployed in TS analysis workflows.
Discovering Leitmotifs in Multidimensional Time Series
Oct 16, 2024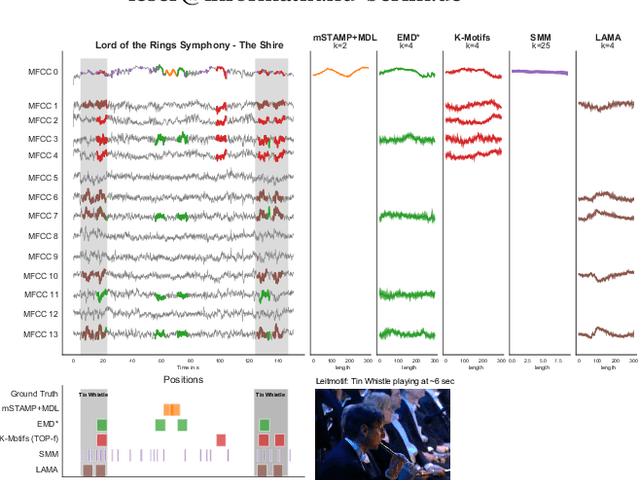
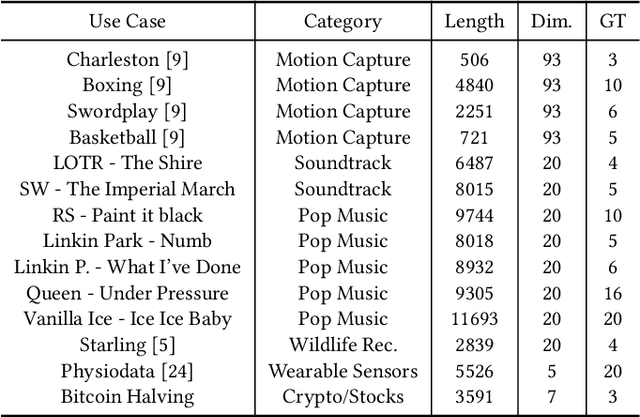
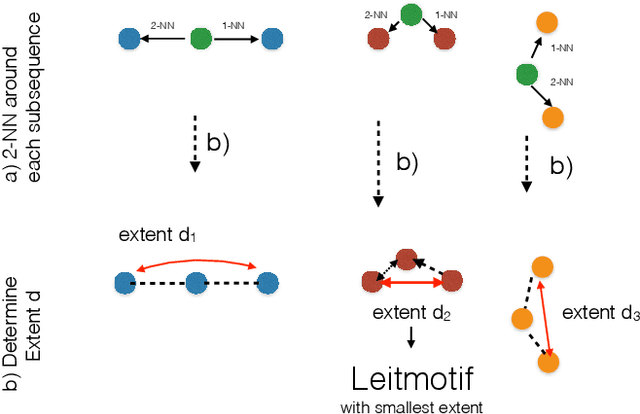
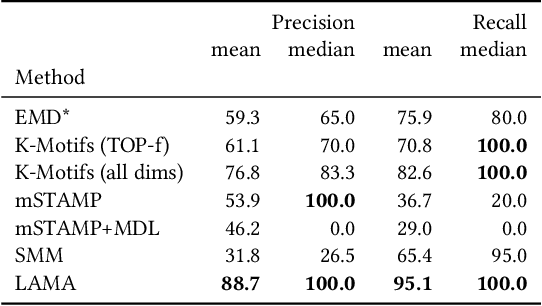
A leitmotif is a recurring theme in literature, movies or music that carries symbolic significance for the piece it is contained in. When this piece can be represented as a multi-dimensional time series (MDTS), such as acoustic or visual observations, finding a leitmotif is equivalent to the pattern discovery problem, which is an unsupervised and complex problem in time series analytics. Compared to the univariate case, it carries additional complexity because patterns typically do not occur in all dimensions but only in a few - which are, however, unknown and must be detected by the method itself. In this paper, we present the novel, efficient and highly effective leitmotif discovery algorithm LAMA for MDTS. LAMA rests on two core principals: (a) a leitmotif manifests solely given a yet unknown number of sub-dimensions - neither too few, nor too many, and (b) the set of sub-dimensions are not independent from the best pattern found therein, necessitating both problems to be approached in a joint manner. In contrast to most previous methods, LAMA tackles both problems jointly - instead of independently selecting dimensions (or leitmotifs) and finding the best leitmotifs (or dimensions). Our experimental evaluation on a novel ground-truth annotated benchmark of 14 distinct real-life data sets shows that LAMA, when compared to four state-of-the-art baselines, shows superior performance in detecting meaningful patterns without increased computational complexity.
aeon: a Python toolkit for learning from time series
Jun 20, 2024aeon is a unified Python 3 library for all machine learning tasks involving time series. The package contains modules for time series forecasting, classification, extrinsic regression and clustering, as well as a variety of utilities, transformations and distance measures designed for time series data. aeon also has a number of experimental modules for tasks such as anomaly detection, similarity search and segmentation. aeon follows the scikit-learn API as much as possible to help new users and enable easy integration of aeon estimators with useful tools such as model selection and pipelines. It provides a broad library of time series algorithms, including efficient implementations of the very latest advances in research. Using a system of optional dependencies, aeon integrates a wide variety of packages into a single interface while keeping the core framework with minimal dependencies. The package is distributed under the 3-Clause BSD license and is available at https://github.com/ aeon-toolkit/aeon. This version was submitted to the JMLR journal on 02 Nov 2023 for v0.5.0 of aeon. At the time of this preprint aeon has released v0.9.0, and has had substantial changes.
Raising the ClaSS of Streaming Time Series Segmentation
Oct 31, 2023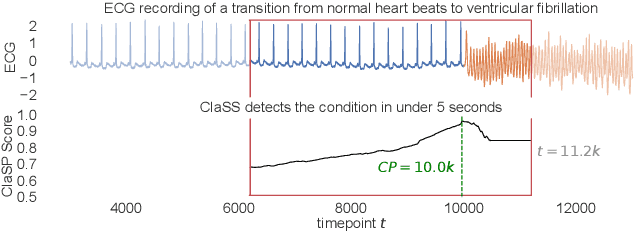


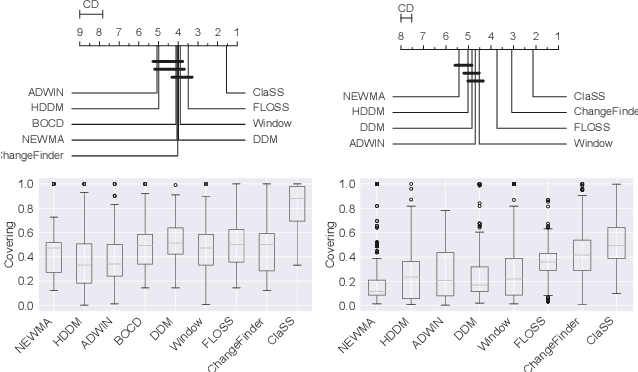
Ubiquitous sensors today emit high frequency streams of numerical measurements that reflect properties of human, animal, industrial, commercial, and natural processes. Shifts in such processes, e.g. caused by external events or internal state changes, manifest as changes in the recorded signals. The task of streaming time series segmentation (STSS) is to partition the stream into consecutive variable-sized segments that correspond to states of the observed processes or entities. The partition operation itself must in performance be able to cope with the input frequency of the signals. We introduce ClaSS, a novel, efficient, and highly accurate algorithm for STSS. ClaSS assesses the homogeneity of potential partitions using self-supervised time series classification and applies statistical tests to detect significant change points (CPs). In our experimental evaluation using two large benchmarks and six real-world data archives, we found ClaSS to be significantly more precise than eight state-of-the-art competitors. Its space and time complexity is independent of segment sizes and linear only in the sliding window size. We also provide ClaSS as a window operator with an average throughput of 538 data points per second for the Apache Flink streaming engine.
Bake off redux: a review and experimental evaluation of recent time series classification algorithms
Apr 25, 2023In 2017, a research paper compared 18 Time Series Classification (TSC) algorithms on 85 datasets from the University of California, Riverside (UCR) archive. This study, commonly referred to as a `bake off', identified that only nine algorithms performed significantly better than the Dynamic Time Warping (DTW) and Rotation Forest benchmarks that were used. The study categorised each algorithm by the type of feature they extract from time series data, forming a taxonomy of five main algorithm types. This categorisation of algorithms alongside the provision of code and accessible results for reproducibility has helped fuel an increase in popularity of the TSC field. Over six years have passed since this bake off, the UCR archive has expanded to 112 datasets and there have been a large number of new algorithms proposed. We revisit the bake off, seeing how each of the proposed categories have advanced since the original publication, and evaluate the performance of newer algorithms against the previous best-of-category using an expanded UCR archive. We extend the taxonomy to include three new categories to reflect recent developments. Alongside the originally proposed distance, interval, shapelet, dictionary and hybrid based algorithms, we compare newer convolution and feature based algorithms as well as deep learning approaches. We introduce 30 classification datasets either recently donated to the archive or reformatted to the TSC format, and use these to further evaluate the best performing algorithm from each category. Overall, we find that two recently proposed algorithms, Hydra+MultiROCKET and HIVE-COTEv2, perform significantly better than other approaches on both the current and new TSC problems.
WEASEL 2.0 -- A Random Dilated Dictionary Transform for Fast, Accurate and Memory Constrained Time Series Classification
Feb 01, 2023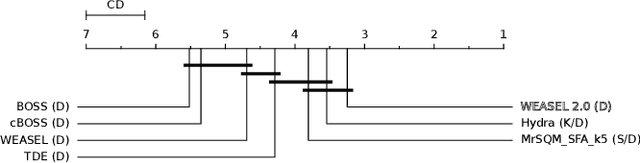


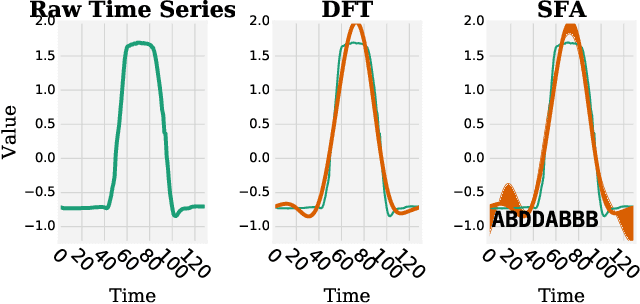
A time series is a sequence of sequentially ordered real values in time. Time series classification (TSC) is the task of assigning a time series to one of a set of predefined classes, usually based on a model learned from examples. Dictionary-based methods for TSC rely on counting the frequency of certain patterns in time series and are important components of the currently most accurate TSC ensembles. One of the early dictionary-based methods was WEASEL, which at its time achieved SotA results while also being very fast. However, it is outperformed both in terms of speed and accuracy by other methods. Furthermore, its design leads to an unpredictably large memory footprint, making it inapplicable for many applications. In this paper, we present WEASEL 2.0, a complete overhaul of WEASEL based on two recent advancements in TSC: Dilation and ensembling of randomized hyper-parameter settings. These two techniques allow WEASEL 2.0 to work with a fixed-size memory footprint while at the same time improving accuracy. Compared to 15 other SotA methods on the UCR benchmark set, WEASEL 2.0 is significantly more accurate than other dictionary methods and not significantly worse than the currently best methods. Actually, it achieves the highest median accuracy over all data sets, and it performs best in 5 out of 12 problem classes. We thus believe that WEASEL 2.0 is a viable alternative for current TSC and also a potentially interesting input for future ensembles.
ClaSP -- Parameter-free Time Series Segmentation
Jul 28, 2022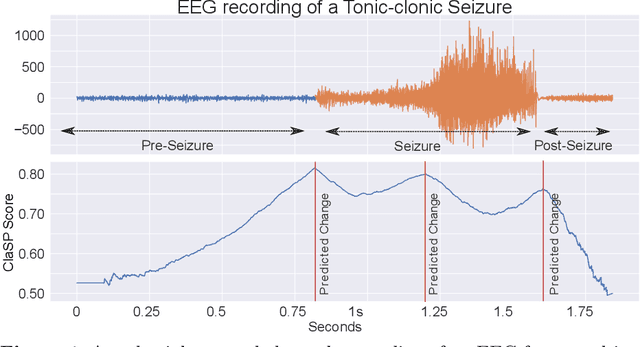
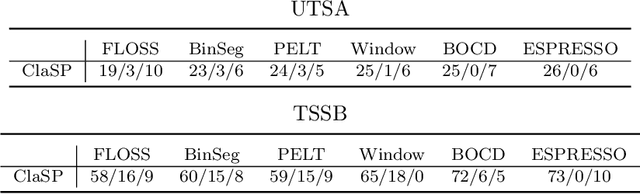
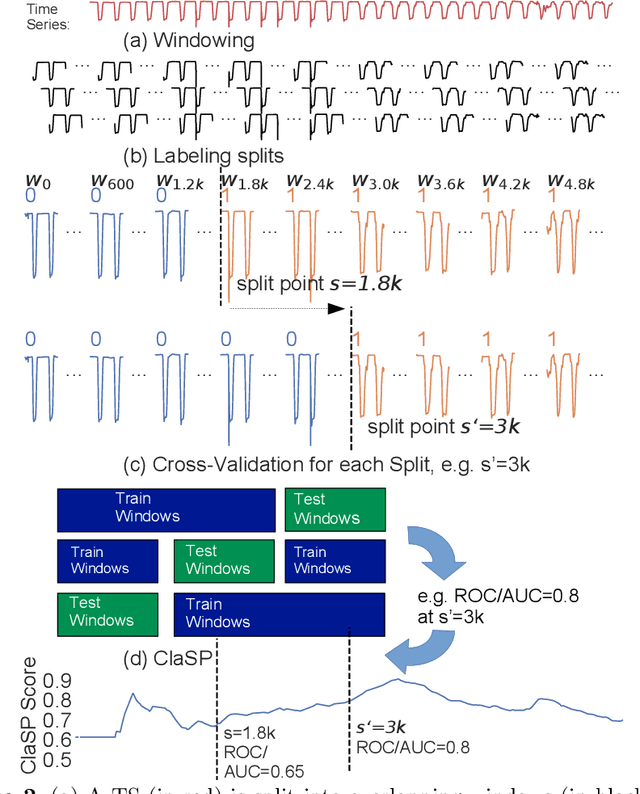
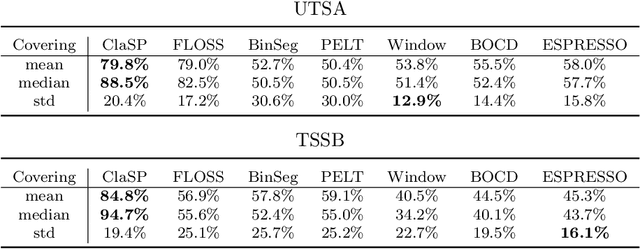
The study of natural and human-made processes often results in long sequences of temporally-ordered values, aka time series (TS). Such processes often consist of multiple states, e.g. operating modes of a machine, such that state changes in the observed processes result in changes in the distribution of shape of the measured values. Time series segmentation (TSS) tries to find such changes in TS post-hoc to deduce changes in the data-generating process. TSS is typically approached as an unsupervised learning problem aiming at the identification of segments distinguishable by some statistical property. Current algorithms for TSS require domain-dependent hyper-parameters to be set by the user, make assumptions about the TS value distribution or the types of detectable changes which limits their applicability. Common hyperparameters are the measure of segment homogeneity and the number of change points, which are particularly hard to tune for each data set. We present ClaSP, a novel, highly accurate, hyper-parameter-free and domain-agnostic method for TSS. ClaSP hierarchically splits a TS into two parts. A change point is determined by training a binary TS classifier for each possible split point and selecting the one split that is best at identifying subsequences to be from either of the partitions. ClaSP learns its main two model-parameters from the data using two novel bespoke algorithms. In our experimental evaluation using a benchmark of 115 data sets, we show that ClaSP outperforms the state of the art in terms of accuracy and is fast and scalable. Furthermore, we highlight properties of ClaSP using several real-world case studies.
Motiflets -- Fast and Accurate Detection of Motifs in Time Series
Jun 08, 2022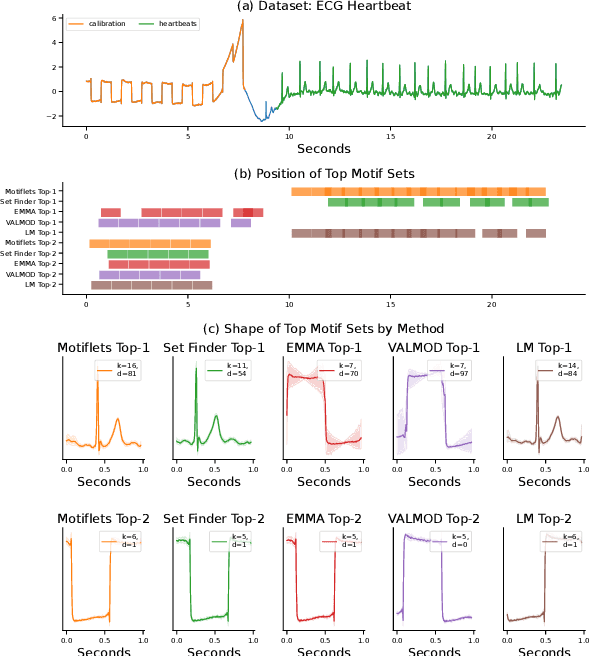



A motif intuitively is a short time series that repeats itself approximately the same within a larger time series. Such motifs often represent concealed structures, such as heart beats in an ECG recording, or sleep spindles in EEG sleep data. Motif discovery (MD) is the task of finding such motifs in a given input series. As there are varying definitions of what exactly a motif is, a number of algorithms exist. As central parameters they all take the length l of the motif and the maximal distance r between the motif's occurrences. In practice, however, suitable values for r are very hard to determine upfront, and the found motifs show a high variability. Setting the wrong input value will result in a motif that is not distinguishable from noise. Accordingly, finding an interesting motif with these methods requires extensive trial-and-error. We present a different approach to the MD problem. We define k-Motiflets as the set of exactly k occurrences of a motif of length l, whose maximum pairwise distance is minimal. This turns the MD problem upside-down: Our central parameter is not the distance threshold r, but the desired size k of a motif set, which we show is considerably more intuitive and easier to set. Based on this definition, we present exact and approximate algorithms for finding k-Motiflets and analyze their complexity. To further ease the use of our method, we describe extensions to automatically determine the right/suitable values for its input parameters. Thus, for the first time, extracting meaningful motif sets without any a-priori knowledge becomes feasible. By evaluating real-world use cases and comparison to 4 state-of-the-art MD algorithms, we show that our proposed algorithm is (a) quantitatively superior, finding larger motif sets at higher similarity, (b) qualitatively better, leading to clearer and easier to interpret motifs, and (c) has the lowest runtime.
timeXplain -- A Framework for Explaining the Predictions of Time Series Classifiers
Jul 15, 2020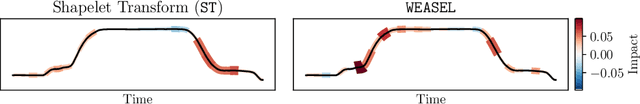



Modern time series classifiers display impressive predictive capabilities, yet their decision-making processes mostly remain black boxes to the user. At the same time, model-agnostic explainers, such as the recently proposed SHAP, promise to make the predictions of machine learning models interpretable, provided there are well-designed domain mappings. We bring both worlds together in our timeXplain framework, extending the reach of explainable artificial intelligence to time series classification and value prediction. We present novel domain mappings for the time and the frequency domain as well as series statistics and analyze their explicative power as well as their limits. We employ timeXplain in a large-scale experimental comparison of several state-of-the-art time series classifiers and discover similarities between seemingly distinct classification concepts such as residual neural networks and elastic ensembles.
Multivariate Time Series Classification with WEASEL+MUSE
Aug 17, 2018


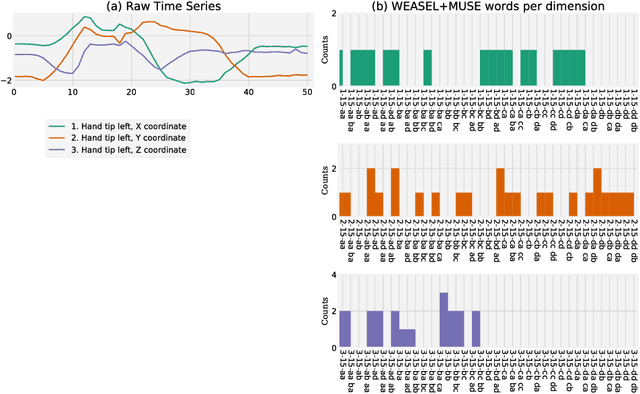
Multivariate time series (MTS) arise when multiple interconnected sensors record data over time. Dealing with this high-dimensional data is challenging for every classifier for at least two aspects: First, an MTS is not only characterized by individual feature values, but also by the interplay of features in different dimensions. Second, this typically adds large amounts of irrelevant data and noise. We present our novel MTS classifier WEASEL+MUSE which addresses both challenges. WEASEL+MUSE builds a multivariate feature vector, first using a sliding-window approach applied to each dimension of the MTS, then extracts discrete features per window and dimension. The feature vector is subsequently fed through feature selection, removing non-discriminative features, and analysed by a machine learning classifier. The novelty of WEASEL+MUSE lies in its specific way of extracting and filtering multivariate features from MTS by encoding context information into each feature. Still the resulting feature set is small, yet very discriminative and useful for MTS classification. Based on a popular benchmark of 20 MTS datasets, we found that WEASEL+MUSE is among the most accurate classifiers, when compared to the state of the art. The outstanding robustness of WEASEL+MUSE is further confirmed based on motion gesture recognition data, where it out-of-the-box achieved similar accuracies as domain-specific methods.