 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotiflets -- Fast and Accurate Detection of Motifs in Time Series
Paper and Code
Jun 08, 2022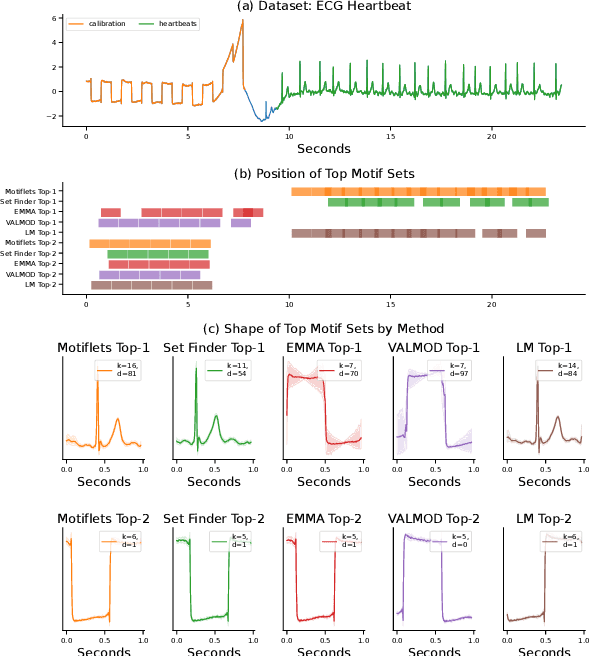



A motif intuitively is a short time series that repeats itself approximately the same within a larger time series. Such motifs often represent concealed structures, such as heart beats in an ECG recording, or sleep spindles in EEG sleep data. Motif discovery (MD) is the task of finding such motifs in a given input series. As there are varying definitions of what exactly a motif is, a number of algorithms exist. As central parameters they all take the length l of the motif and the maximal distance r between the motif's occurrences. In practice, however, suitable values for r are very hard to determine upfront, and the found motifs show a high variability. Setting the wrong input value will result in a motif that is not distinguishable from noise. Accordingly, finding an interesting motif with these methods requires extensive trial-and-error. We present a different approach to the MD problem. We define k-Motiflets as the set of exactly k occurrences of a motif of length l, whose maximum pairwise distance is minimal. This turns the MD problem upside-down: Our central parameter is not the distance threshold r, but the desired size k of a motif set, which we show is considerably more intuitive and easier to set. Based on this definition, we present exact and approximate algorithms for finding k-Motiflets and analyze their complexity. To further ease the use of our method, we describe extensions to automatically determine the right/suitable values for its input parameters. Thus, for the first time, extracting meaningful motif sets without any a-priori knowledge becomes feasible. By evaluating real-world use cases and comparison to 4 state-of-the-art MD algorithms, we show that our proposed algorithm is (a) quantitatively superior, finding larger motif sets at higher similarity, (b) qualitatively better, leading to clearer and easier to interpret motifs, and (c) has the lowest runtime.