 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNIPS - Not Even Wrong? A Systematic Review of Empirically Complete Demonstrations of Algorithmic Effectiveness in the Machine Learning and Artificial Intelligence Literature
Paper and Code
Dec 18, 2018
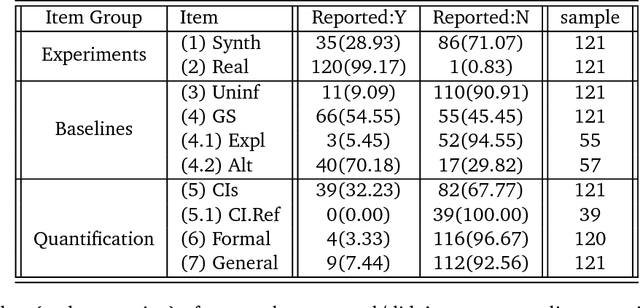
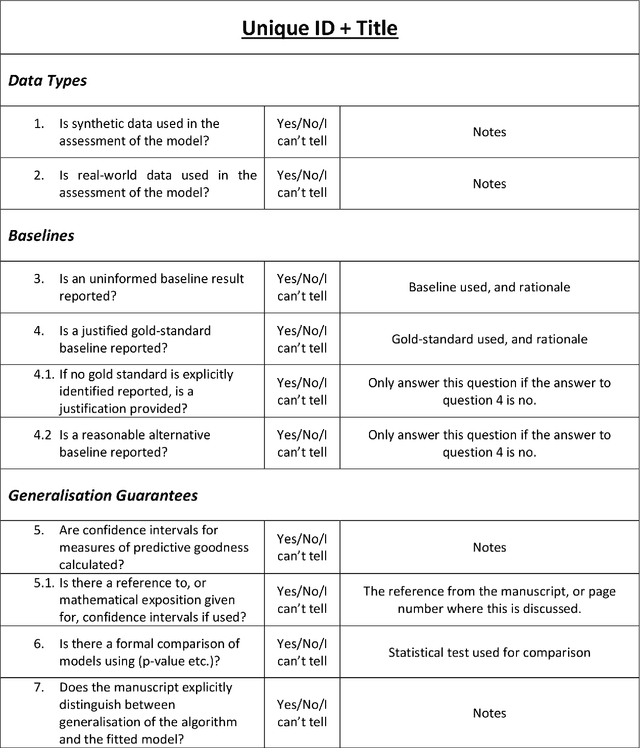
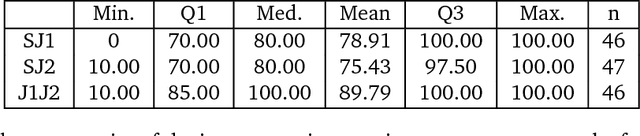
Objective: To determine the completeness of argumentative steps necessary to conclude effectiveness of an algorithm in a sample of current ML/AI supervised learning literature. Data Sources: Papers published in the Neural Information Processing Systems (NeurIPS, n\'ee NIPS) journal where the official record showed a 2017 year of publication. Eligibility Criteria: Studies reporting a (semi-)supervised model, or pre-processing fused with (semi-)supervised models for tabular data. Study Appraisal: Three reviewers applied the assessment criteria to determine argumentative completeness. The criteria were split into three groups, including: experiments (e.g real and/or synthetic data), baselines (e.g uninformed and/or state-of-art) and quantitative comparison (e.g. performance quantifiers with confidence intervals and formal comparison of the algorithm against baselines). Results: Of the 121 eligible manuscripts (from the sample of 679 abstracts), 99\% used real-world data and 29\% used synthetic data. 91\% of manuscripts did not report an uninformed baseline and 55\% reported a state-of-art baseline. 32\% reported confidence intervals for performance but none provided references or exposition for how these were calculated. 3\% reported formal comparisons. Limitations: The use of one journal as the primary information source may not be representative of all ML/AI literature. However, the NeurIPS conference is recognised to be amongst the top tier concerning ML/AI studies, so it is reasonable to consider its corpus to be representative of high-quality research. Conclusion: Using the 2017 sample of the NeurIPS supervised learning corpus as an indicator for the quality and trustworthiness of current ML/AI research, it appears that complete argumentative chains in demonstrations of algorithmic effectiveness are rare.