 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning and AI research for Patient Benefit: 20 Critical Questions on Transparency, Replicability, Ethics and Effectiveness
Dec 21, 2018Machine learning (ML), artificial intelligence (AI) and other modern statistical methods are providing new opportunities to operationalize previously untapped and rapidly growing sources of data for patient benefit. Whilst there is a lot of promising research currently being undertaken, the literature as a whole lacks: transparency; clear reporting to facilitate replicability; exploration for potential ethical concerns; and, clear demonstrations of effectiveness. There are many reasons for why these issues exist, but one of the most important that we provide a preliminary solution for here is the current lack of ML/AI- specific best practice guidance. Although there is no consensus on what best practice looks in this field, we believe that interdisciplinary groups pursuing research and impact projects in the ML/AI for health domain would benefit from answering a series of questions based on the important issues that exist when undertaking work of this nature. Here we present 20 questions that span the entire project life cycle, from inception, data analysis, and model evaluation, to implementation, as a means to facilitate project planning and post-hoc (structured) independent evaluation. By beginning to answer these questions in different settings, we can start to understand what constitutes a good answer, and we expect that the resulting discussion will be central to developing an international consensus framework for transparent, replicable, ethical and effective research in artificial intelligence (AI-TREE) for health.
NIPS - Not Even Wrong? A Systematic Review of Empirically Complete Demonstrations of Algorithmic Effectiveness in the Machine Learning and Artificial Intelligence Literature
Dec 18, 2018
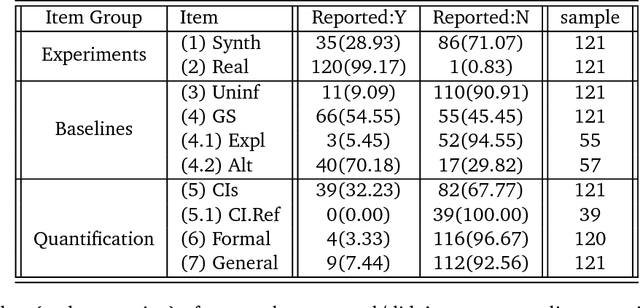
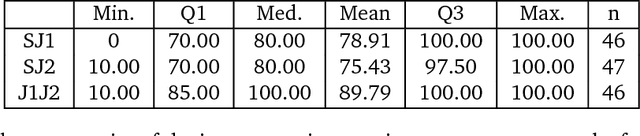
Objective: To determine the completeness of argumentative steps necessary to conclude effectiveness of an algorithm in a sample of current ML/AI supervised learning literature. Data Sources: Papers published in the Neural Information Processing Systems (NeurIPS, n\'ee NIPS) journal where the official record showed a 2017 year of publication. Eligibility Criteria: Studies reporting a (semi-)supervised model, or pre-processing fused with (semi-)supervised models for tabular data. Study Appraisal: Three reviewers applied the assessment criteria to determine argumentative completeness. The criteria were split into three groups, including: experiments (e.g real and/or synthetic data), baselines (e.g uninformed and/or state-of-art) and quantitative comparison (e.g. performance quantifiers with confidence intervals and formal comparison of the algorithm against baselines). Results: Of the 121 eligible manuscripts (from the sample of 679 abstracts), 99\% used real-world data and 29\% used synthetic data. 91\% of manuscripts did not report an uninformed baseline and 55\% reported a state-of-art baseline. 32\% reported confidence intervals for performance but none provided references or exposition for how these were calculated. 3\% reported formal comparisons. Limitations: The use of one journal as the primary information source may not be representative of all ML/AI literature. However, the NeurIPS conference is recognised to be amongst the top tier concerning ML/AI studies, so it is reasonable to consider its corpus to be representative of high-quality research. Conclusion: Using the 2017 sample of the NeurIPS supervised learning corpus as an indicator for the quality and trustworthiness of current ML/AI research, it appears that complete argumentative chains in demonstrations of algorithmic effectiveness are rare.
Predictive Independence Testing, Predictive Conditional Independence Testing, and Predictive Graphical Modelling
Apr 28, 2018


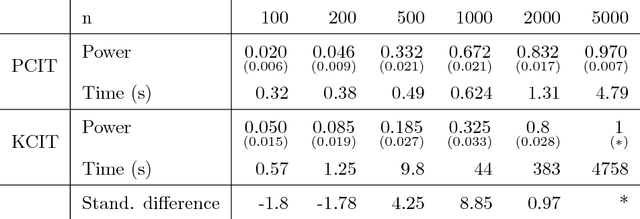
Testing (conditional) independence of multivariate random variables is a task central to statistical inference and modelling in general - though unfortunately one for which to date there does not exist a practicable workflow. State-of-art workflows suffer from the need for heuristic or subjective manual choices, high computational complexity, or strong parametric assumptions. We address these problems by establishing a theoretical link between multivariate/conditional independence testing, and model comparison in the multivariate predictive modelling aka supervised learning task. This link allows advances in the extensively studied supervised learning workflow to be directly transferred to independence testing workflows - including automated tuning of machine learning type which addresses the need for a heuristic choice, the ability to quantitatively trade-off computational demand with accuracy, and the modern black-box philosophy for checking and interfacing. As a practical implementation of this link between the two workflows, we present a python package 'pcit', which implements our novel multivariate and conditional independence tests, interfacing the supervised learning API of the scikit-learn package. Theory and package also allow for straightforward independence test based learning of graphical model structure. We empirically show that our proposed predictive independence test outperform or are on par to current practice, and the derived graphical model structure learning algorithms asymptotically recover the 'true' graph. This paper, and the 'pcit' package accompanying it, thus provide powerful, scalable, generalizable, and easy-to-use methods for multivariate and conditional independence testing, as well as for graphical model structure learning.
Machine Learning in Falls Prediction; A cognition-based predictor of falls for the acute neurological in-patient population
Jul 05, 2016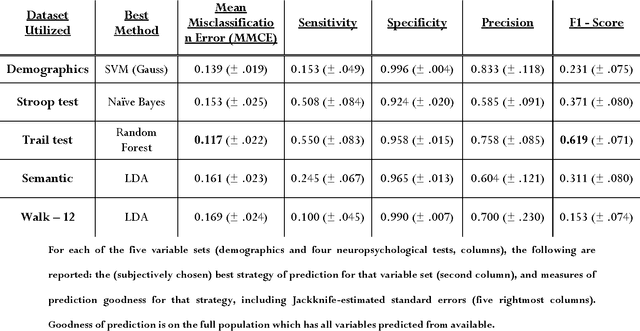
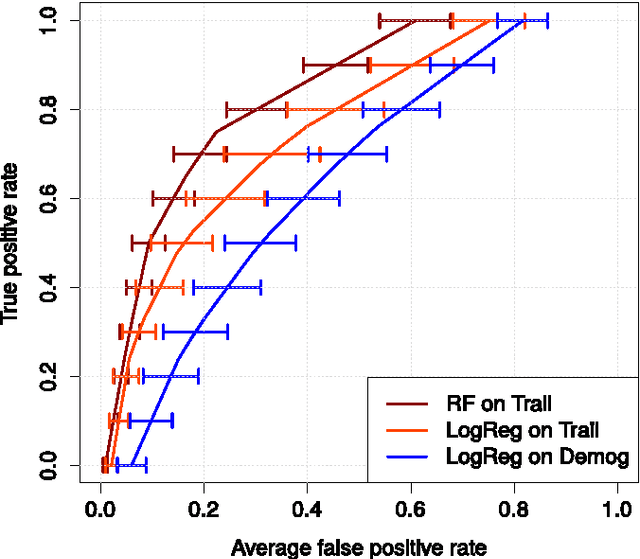
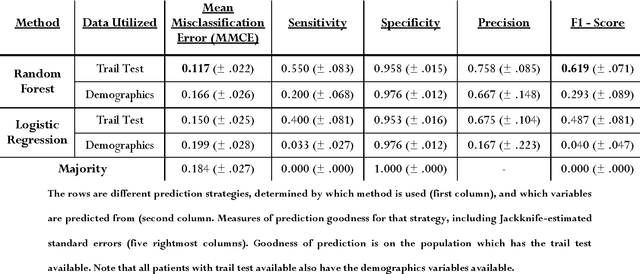
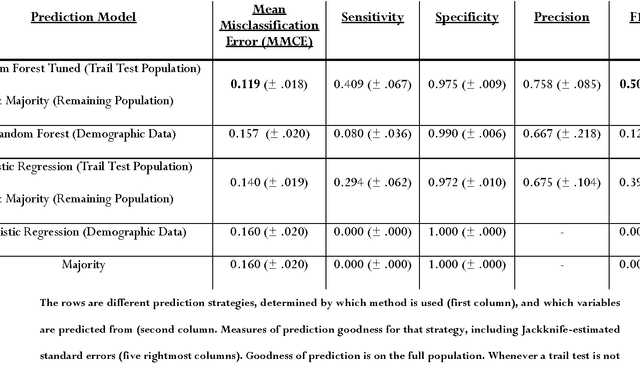
Background Information: Falls are associated with high direct and indirect costs, and significant morbidity and mortality for patients. Pathological falls are usually a result of a compromised motor system, and/or cognition. Very little research has been conducted on predicting falls based on this premise. Aims: To demonstrate that cognitive and motor tests can be used to create a robust predictive tool for falls. Methods: Three tests of attention and executive function (Stroop, Trail Making, and Semantic Fluency), a measure of physical function (Walk-12), a series of questions (concerning recent falls, surgery and physical function) and demographic information were collected from a cohort of 323 patients at a tertiary neurological center. The principal outcome was a fall during the in-patient stay (n = 54). Data-driven, predictive modelling was employed to identify the statistical modelling strategies which are most accurate in predicting falls, and which yield the most parsimonious models of clinical relevance. Results: The Trail test was identified as the best predictor of falls. Moreover, addition of any others variables, to the results of the Trail test did not improve the prediction (Wilcoxon signed-rank p < .001). The best statistical strategy for predicting falls was the random forest (Wilcoxon signed-rank p < .001), based solely on results of the Trail test. Tuning of the model results in the following optimized values: 68% (+- 7.7) sensitivity, 90% (+- 2.3) specificity, with a positive predictive value of 60%, when the relevant data is available. Conclusion: Predictive modelling has identified a simple yet powerful machine learning prediction strategy based on a single clinical test, the Trail test. Predictive evaluation shows this strategy to be robust, suggesting predictive modelling and machine learning as the standard for future predictive tools.
Kernels for sequentially ordered data
Jan 29, 2016



We present a novel framework for kernel learning with sequential data of any kind, such as time series, sequences of graphs, or strings. Our approach is based on signature features which can be seen as an ordered variant of sample (cross-)moments; it allows to obtain a "sequentialized" version of any static kernel. The sequential kernels are efficiently computable for discrete sequences and are shown to approximate a continuous moment form in a sampling sense. A number of known kernels for sequences arise as "sequentializations" of suitable static kernels: string kernels may be obtained as a special case, and alignment kernels are closely related up to a modification that resolves their open non-definiteness issue. Our experiments indicate that our signature-based sequential kernel framework may be a promising approach to learning with sequential data, such as time series, that allows to avoid extensive manual pre-processing.
Learning with Cross-Kernels and Ideal PCA
Jun 10, 2014We describe how cross-kernel matrices, that is, kernel matrices between the data and a custom chosen set of `feature spanning points' can be used for learning. The main potential of cross-kernels lies in the fact that (a) only one side of the matrix scales with the number of data points, and (b) cross-kernels, as opposed to the usual kernel matrices, can be used to certify for the data manifold. Our theoretical framework, which is based on a duality involving the feature space and vanishing ideals, indicates that cross-kernels have the potential to be used for any kind of kernel learning. We present a novel algorithm, Ideal PCA (IPCA), which cross-kernelizes PCA. We demonstrate on real and synthetic data that IPCA allows to (a) obtain PCA-like features faster and (b) to extract novel and empirically validated features certifying for the data manifold.
Matroid Regression
Mar 04, 2014We propose an algebraic combinatorial method for solving large sparse linear systems of equations locally - that is, a method which can compute single evaluations of the signal without computing the whole signal. The method scales only in the sparsity of the system and not in its size, and allows to provide error estimates for any solution method. At the heart of our approach is the so-called regression matroid, a combinatorial object associated to sparsity patterns, which allows to replace inversion of the large matrix with the inversion of a kernel matrix that is constant size. We show that our method provides the best linear unbiased estimator (BLUE) for this setting and the minimum variance unbiased estimator (MVUE) under Gaussian noise assumptions, and furthermore we show that the size of the kernel matrix which is to be inverted can be traded off with accuracy.
The Algebraic Approach to Phase Retrieval and Explicit Inversion at the Identifiability Threshold
Feb 17, 2014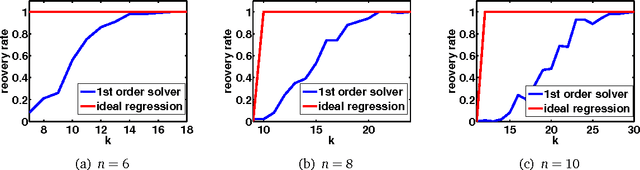
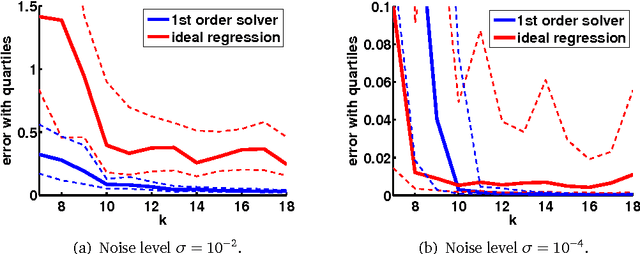
We study phase retrieval from magnitude measurements of an unknown signal as an algebraic estimation problem. Indeed, phase retrieval from rank-one and more general linear measurements can be treated in an algebraic way. It is verified that a certain number of generic rank-one or generic linear measurements are sufficient to enable signal reconstruction for generic signals, and slightly more generic measurements yield reconstructability for all signals. Our results solve a few open problems stated in the recent literature. Furthermore, we show how the algebraic estimation problem can be solved by a closed-form algebraic estimation technique, termed ideal regression, providing non-asymptotic success guarantees.