 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
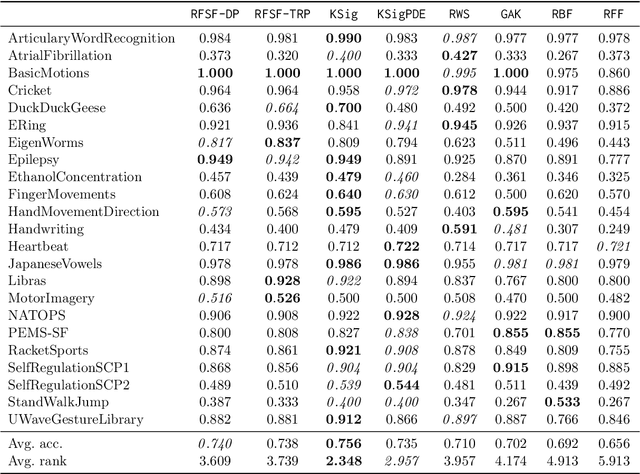
Add to EdgeA User's Guide to $\texttt{KSig}$: GPU-Accelerated Computation of the Signature Kernel
Jan 14, 2025



The signature kernel is a positive definite kernel for sequential and temporal data that has become increasingly popular in machine learning applications due to powerful theoretical guarantees, strong empirical performance, and recently introduced various scalable variations. In this chapter, we give a short introduction to $\texttt{KSig}$, a $\texttt{Scikit-Learn}$ compatible Python package that implements various GPU-accelerated algorithms for computing signature kernels, and performing downstream learning tasks. We also introduce a new algorithm based on tensor sketches which gives strong performance compared to existing algorithms. The package is available at https://github.com/tgcsaba/ksig.
Learning to Forget: Bayesian Time Series Forecasting using Recurrent Sparse Spectrum Signature Gaussian Processes
Dec 27, 2024



The signature kernel is a kernel between time series of arbitrary length and comes with strong theoretical guarantees from stochastic analysis. It has found applications in machine learning such as covariance functions for Gaussian processes. A strength of the underlying signature features is that they provide a structured global description of a time series. However, this property can quickly become a curse when local information is essential and forgetting is required; so far this has only been addressed with ad-hoc methods such as slicing the time series into subsegments. To overcome this, we propose a principled, data-driven approach by introducing a novel forgetting mechanism for signatures. This allows the model to dynamically adapt its context length to focus on more recent information. To achieve this, we revisit the recently introduced Random Fourier Signature Features, and develop Random Fourier Decayed Signature Features (RFDSF) with Gaussian processes (GPs). This results in a Bayesian time series forecasting algorithm with variational inference, that offers a scalable probabilistic algorithm that processes and transforms a time series into a joint predictive distribution over time steps in one pass using recurrence. For example, processing a sequence of length $10^4$ steps in $\approx 10^{-2}$ seconds and in $< 1\text{GB}$ of GPU memory. We demonstrate that it outperforms other GP-based alternatives and competes with state-of-the-art probabilistic time series forecasting algorithms.
A Quadrature Approach for General-Purpose Batch Bayesian Optimization via Probabilistic Lifting
Apr 19, 2024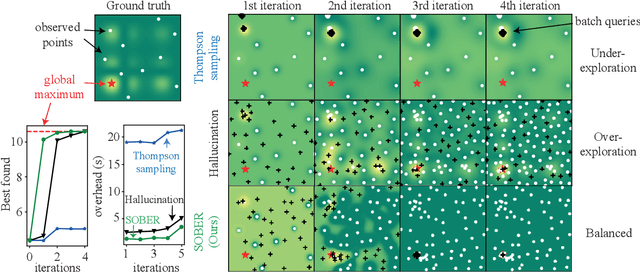

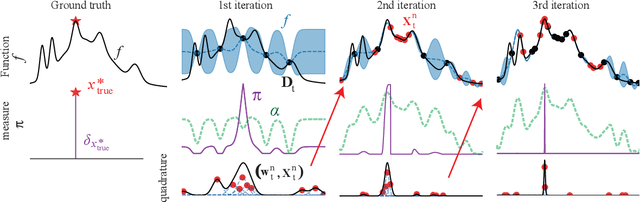

Parallelisation in Bayesian optimisation is a common strategy but faces several challenges: the need for flexibility in acquisition functions and kernel choices, flexibility dealing with discrete and continuous variables simultaneously, model misspecification, and lastly fast massive parallelisation. To address these challenges, we introduce a versatile and modular framework for batch Bayesian optimisation via probabilistic lifting with kernel quadrature, called SOBER, which we present as a Python library based on GPyTorch/BoTorch. Our framework offers the following unique benefits: (1) Versatility in downstream tasks under a unified approach. (2) A gradient-free sampler, which does not require the gradient of acquisition functions, offering domain-agnostic sampling (e.g., discrete and mixed variables, non-Euclidean space). (3) Flexibility in domain prior distribution. (4) Adaptive batch size (autonomous determination of the optimal batch size). (5) Robustness against a misspecified reproducing kernel Hilbert space. (6) Natural stopping criterion.
Random Fourier Signature Features
Nov 20, 2023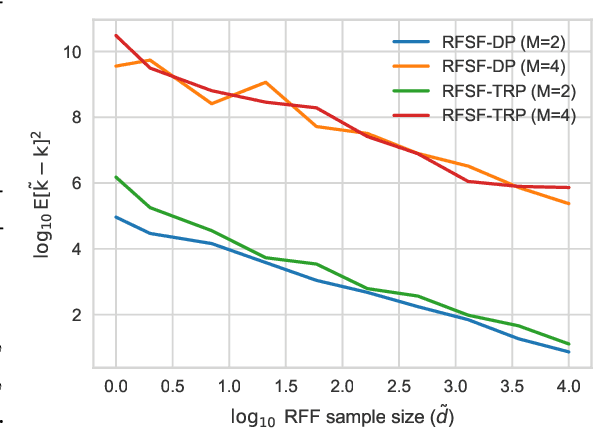

Tensor algebras give rise to one of the most powerful measures of similarity for sequences of arbitrary length called the signature kernel accompanied with attractive theoretical guarantees from stochastic analysis. Previous algorithms to compute the signature kernel scale quadratically in terms of the length and the number of the sequences. To mitigate this severe computational bottleneck, we develop a random Fourier feature-based acceleration of the signature kernel acting on the inherently non-Euclidean domain of sequences. We show uniform approximation guarantees for the proposed unbiased estimator of the signature kernel, while keeping its computation linear in the sequence length and number. In addition, combined with recent advances on tensor projections, we derive two even more scalable time series features with favourable concentration properties and computational complexity both in time and memory. Our empirical results show that the reduction in computational cost comes at a negligible price in terms of accuracy on moderate-sized datasets, and it enables one to scale to large datasets up to a million time series.
HADES: Fast Singularity Detection with Local Measure Comparison
Nov 07, 2023



We introduce Hades, an unsupervised algorithm to detect singularities in data. This algorithm employs a kernel goodness-of-fit test, and as a consequence it is much faster and far more scaleable than the existing topology-based alternatives. Using tools from differential geometry and optimal transport theory, we prove that Hades correctly detects singularities with high probability when the data sample lives on a transverse intersection of equidimensional manifolds. In computational experiments, Hades recovers singularities in synthetically generated data, branching points in road network data, intersection rings in molecular conformation space, and anomalies in image data.
Domain-Agnostic Batch Bayesian Optimization with Diverse Constraints via Bayesian Quadrature
Jun 09, 2023



Real-world optimisation problems often feature complex combinations of (1) diverse constraints, (2) discrete and mixed spaces, and are (3) highly parallelisable. (4) There are also cases where the objective function cannot be queried if unknown constraints are not satisfied, e.g. in drug discovery, safety on animal experiments (unknown constraints) must be established before human clinical trials (querying objective function) may proceed. However, most existing works target each of the above three problems in isolation and do not consider (4) unknown constraints with query rejection. For problems with diverse constraints and/or unconventional input spaces, it is difficult to apply these techniques as they are often mutually incompatible. We propose cSOBER, a domain-agnostic prudent parallel active sampler for Bayesian optimisation, based on SOBER of Adachi et al. (2023). We consider infeasibility under unknown constraints as a type of integration error that we can estimate. We propose a theoretically-driven approach that propagates such error as a tolerance in the quadrature precision that automatically balances exploitation and exploration with the expected rejection rate. Moreover, our method flexibly accommodates diverse constraints and/or discrete and mixed spaces via adaptive tolerance, including conventional zero-risk cases. We show that cSOBER outperforms competitive baselines on diverse real-world blackbox-constrained problems, including safety-constrained drug discovery, and human-relationship-aware team optimisation over graph-structured space.
The Signature Kernel
May 08, 2023


The signature kernel is a positive definite kernel for sequential data. It inherits theoretical guarantees from stochastic analysis, has efficient algorithms for computation, and shows strong empirical performance. In this short survey paper for a forthcoming Springer handbook, we give an elementary introduction to the signature kernel and highlight these theoretical and computational properties.
SOBER: Scalable Batch Bayesian Optimization and Quadrature using Recombination Constraints
Jan 30, 2023



Batch Bayesian optimisation (BO) has shown to be a sample-efficient method of performing optimisation where expensive-to-evaluate objective functions can be queried in parallel. However, current methods do not scale to large batch sizes -- a frequent desideratum in practice (e.g. drug discovery or simulation-based inference). We present a novel algorithm, SOBER, which permits scalable and diversified batch BO with arbitrary acquisition functions, arbitrary input spaces (e.g. graph), and arbitrary kernels. The key to our approach is to reformulate batch selection for BO as a Bayesian quadrature (BQ) problem, which offers computational advantages. This reformulation is beneficial in solving BQ tasks reciprocally, which introduces the exploitative functionality of BO to BQ. We show that SOBER offers substantive performance gains in synthetic and real-world tasks, including drug discovery and simulation-based inference.
Kernelized Cumulants: Beyond Kernel Mean Embeddings
Jan 29, 2023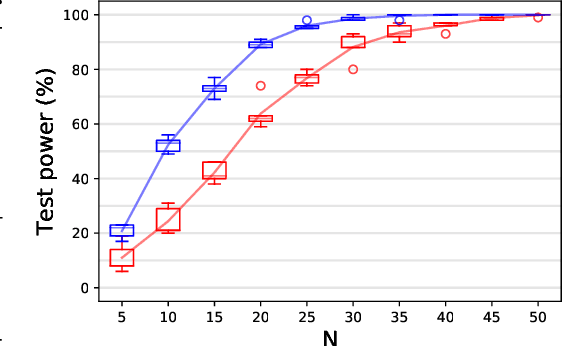
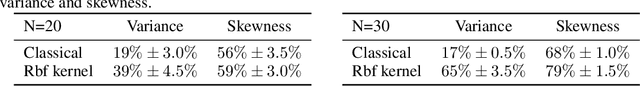
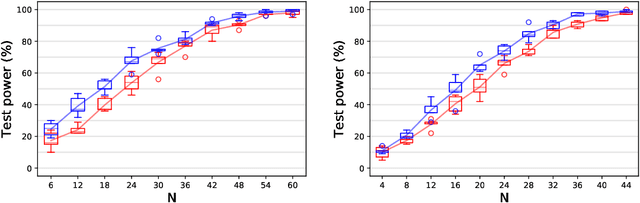
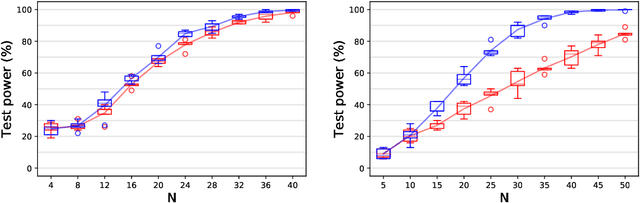
In $\mathbb R^d$, it is well-known that cumulants provide an alternative to moments that can achieve the same goals with numerous benefits such as lower variance estimators. In this paper we extend cumulants to reproducing kernel Hilbert spaces (RKHS) using tools from tensor algebras and show that they are computationally tractable by a kernel trick. These kernelized cumulants provide a new set of all-purpose statistics; the classical maximum mean discrepancy and Hilbert-Schmidt independence criterion arise as the degree one objects in our general construction. We argue both theoretically and empirically (on synthetic, environmental, and traffic data analysis) that going beyond degree one has several advantages and can be achieved with the same computational complexity and minimal overhead in our experiments.
Sampling-based Nyström Approximation and Kernel Quadrature
Jan 23, 2023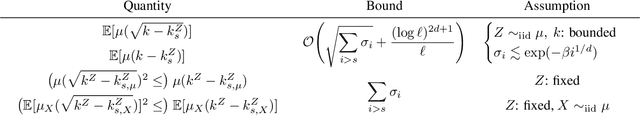
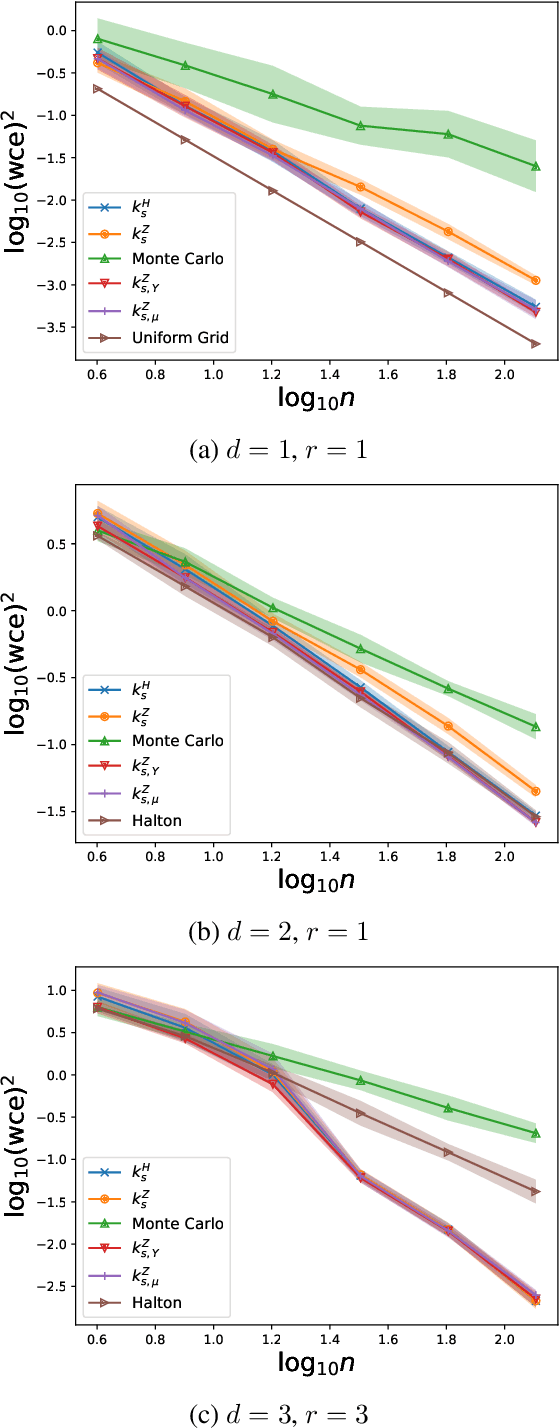
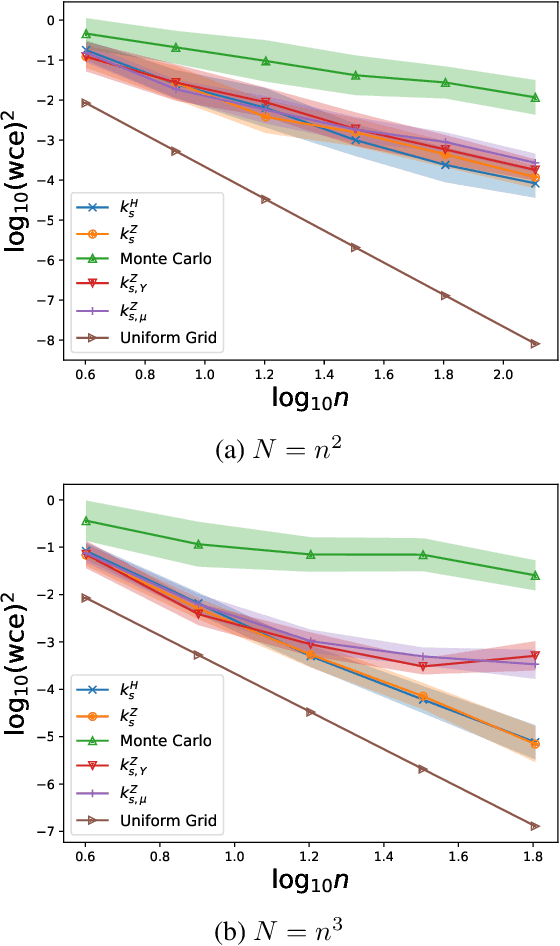
We analyze the Nystr\"om approximation of a positive definite kernel associated with a probability measure. We first prove an improved error bound for the conventional Nystr\"om approximation with i.i.d. sampling and singular-value decomposition in the continuous regime; the proof techniques are borrowed from statistical learning theory. We further introduce a refined selection of subspaces in Nystr\"om approximation with theoretical guarantees that is applicable to non-i.i.d. landmark points. Finally, we discuss their application to convex kernel quadrature and give novel theoretical guarantees as well as numerical observations.