 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemlr3torch: A Deep Learning Framework in R based on mlr3 and torch
Apr 20, 2026Deep learning (DL) has become a cornerstone of modern machine learning (ML) praxis. We introduce the R package mlr3torch, which is an extensible DL framework for the mlr3 ecosystem. It is built upon the torch package, and simplifies the definition, training, and evaluation of neural networks for both tabular data and generic tensors (e.g., images) for classification and regression. The package implements predefined architectures, and torch models can easily be converted to mlr3 learners. It also allows users to define neural networks as graphs. This representation is based on the graph language defined in mlr3pipelines and allows users to define the entire modeling workflow, including preprocessing, data augmentation, and network architecture, in a single graph. Through its integration into the mlr3 ecosystem, the package allows for convenient resampling, benchmarking, preprocessing, and more. We explain the package's design and features and show how to customize and extend it to new problems. Furthermore, we demonstrate the package's capabilities using three use cases, namely hyperparameter tuning, fine-tuning, and defining architectures for multimodal data. Finally, we present some runtime benchmarks.
xplainfi: Feature Importance and Statistical Inference for Machine Learning in R
Mar 16, 2026We introduce xplainfi, an R package built on top of the mlr3 ecosystem for global, loss-based feature importance methods for machine learning models. Various feature importance methods exist in R, but significant gaps remain, particularly regarding conditional importance methods and associated statistical inference procedures. The package implements permutation feature importance, conditional feature importance, relative feature importance, leave-one-covariate-out, and generalizations thereof, and both marginal and conditional Shapley additive global importance methods. It provides a modular conditional sampling architecture based on Gaussian distributions, adversarial random forests, conditional inference trees, and knockoff-based samplers, which enable conditional importance analysis for continuous and mixed data. Statistical inference is available through multiple approaches, including variance-corrected confidence intervals and the conditional predictive impact framework. We demonstrate that xplainfi produces importance scores consistent with existing implementations across multiple simulation settings and learner types, while offering competitive runtime performance. The package is available on CRAN and provides researchers and practitioners with a comprehensive toolkit for feature importance analysis and model interpretation in R.
Machine Learning in Epidemiology
Feb 18, 2026In the age of digital epidemiology, epidemiologists are faced by an increasing amount of data of growing complexity and dimensionality. Machine learning is a set of powerful tools that can help to analyze such enormous amounts of data. This chapter lays the methodological foundations for successfully applying machine learning in epidemiology. It covers the principles of supervised and unsupervised learning and discusses the most important machine learning methods. Strategies for model evaluation and hyperparameter optimization are developed and interpretable machine learning is introduced. All these theoretical parts are accompanied by code examples in R, where an example dataset on heart disease is used throughout the chapter.
Conditional Feature Importance with Generative Modeling Using Adversarial Random Forests
Jan 19, 2025This paper proposes a method for measuring conditional feature importance via generative modeling. In explainable artificial intelligence (XAI), conditional feature importance assesses the impact of a feature on a prediction model's performance given the information of other features. Model-agnostic post hoc methods to do so typically evaluate changes in the predictive performance under on-manifold feature value manipulations. Such procedures require creating feature values that respect conditional feature distributions, which can be challenging in practice. Recent advancements in generative modeling can facilitate this. For tabular data, which may consist of both categorical and continuous features, the adversarial random forest (ARF) stands out as a generative model that can generate on-manifold data points without requiring intensive tuning efforts or computational resources, making it a promising candidate model for subroutines in XAI methods. This paper proposes cARFi (conditional ARF feature importance), a method for measuring conditional feature importance through feature values sampled from ARF-estimated conditional distributions. cARFi requires only little tuning to yield robust importance scores that can flexibly adapt for conditional or marginal notions of feature importance, including straightforward extensions to condition on feature subsets and allows for inferring the significance of feature importances through statistical tests.
A Large-Scale Neutral Comparison Study of Survival Models on Low-Dimensional Data
Jun 06, 2024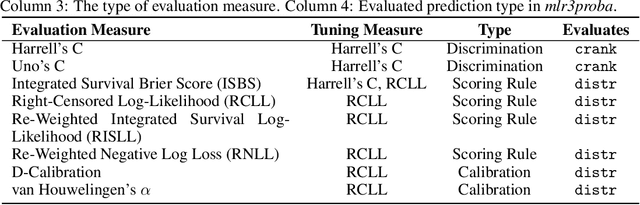

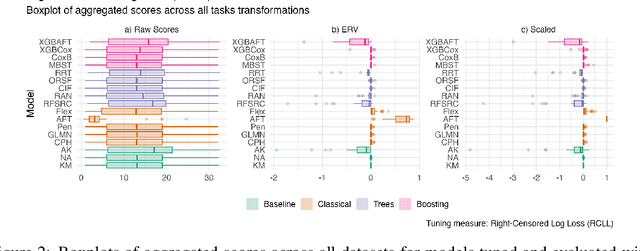
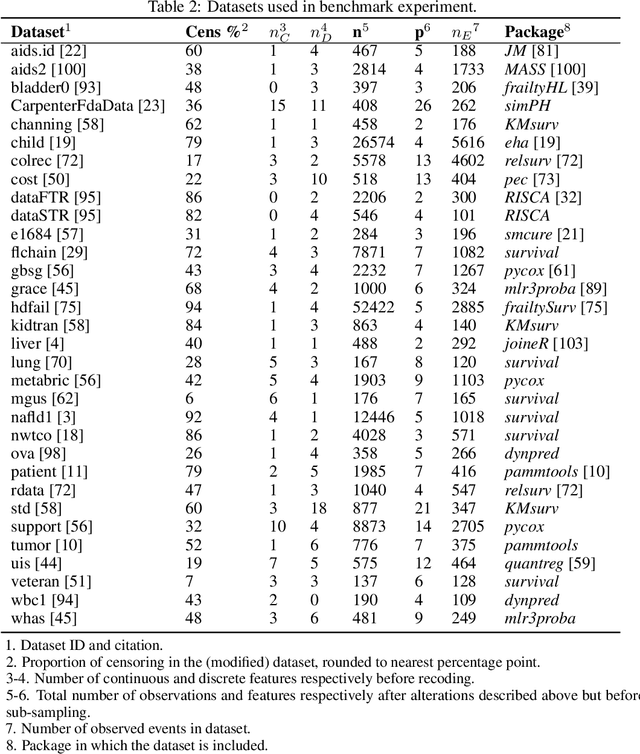
This work presents the first large-scale neutral benchmark experiment focused on single-event, right-censored, low-dimensional survival data. Benchmark experiments are essential in methodological research to scientifically compare new and existing model classes through proper empirical evaluation. Existing benchmarks in the survival literature are often narrow in scope, focusing, for example, on high-dimensional data. Additionally, they may lack appropriate tuning or evaluation procedures, or are qualitative reviews, rather than quantitative comparisons. This comprehensive study aims to fill the gap by neutrally evaluating a broad range of methods and providing generalizable conclusions. We benchmark 18 models, ranging from classical statistical approaches to many common machine learning methods, on 32 publicly available datasets. The benchmark tunes for both a discrimination measure and a proper scoring rule to assess performance in different settings. Evaluating on 8 survival metrics, we assess discrimination, calibration, and overall predictive performance of the tested models. Using discrimination measures, we find that no method significantly outperforms the Cox model. However, (tuned) Accelerated Failure Time models were able to achieve significantly better results with respect to overall predictive performance as measured by the right-censored log-likelihood. Machine learning methods that performed comparably well include Oblique Random Survival Forests under discrimination, and Cox-based likelihood-boosting under overall predictive performance. We conclude that for predictive purposes in the standard survival analysis setting of low-dimensional, right-censored data, the Cox Proportional Hazards model remains a simple and robust method, sufficient for practitioners.
Flexible Group Fairness Metrics for Survival Analysis
May 26, 2022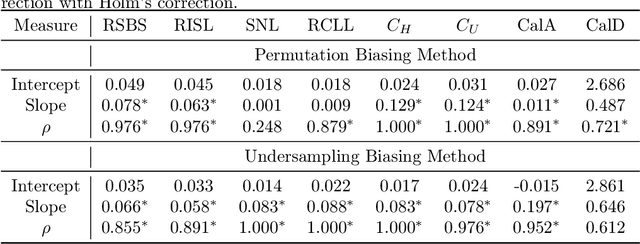
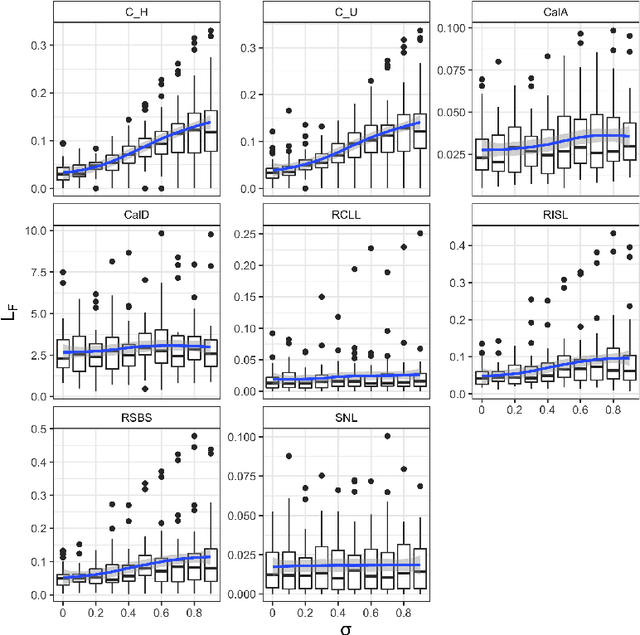
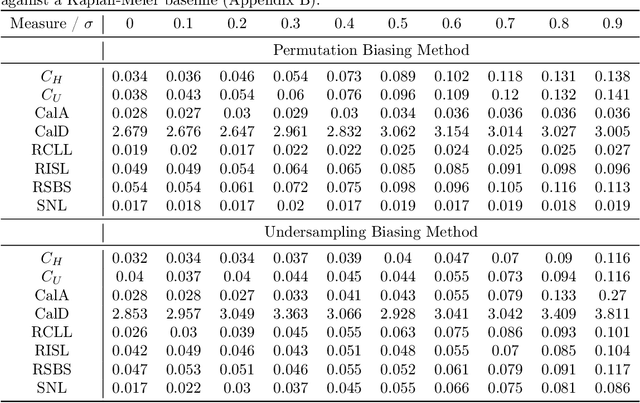
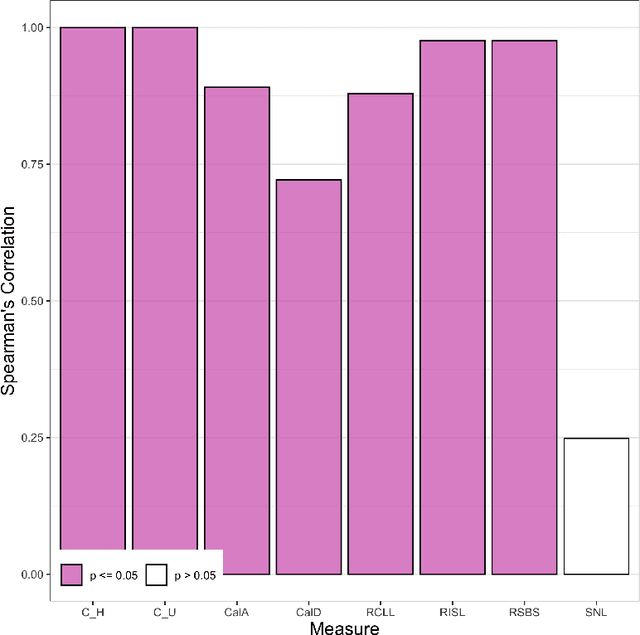
Algorithmic fairness is an increasingly important field concerned with detecting and mitigating biases in machine learning models. There has been a wealth of literature for algorithmic fairness in regression and classification however there has been little exploration of the field for survival analysis. Survival analysis is the prediction task in which one attempts to predict the probability of an event occurring over time. Survival predictions are particularly important in sensitive settings such as when utilising machine learning for diagnosis and prognosis of patients. In this paper we explore how to utilise existing survival metrics to measure bias with group fairness metrics. We explore this in an empirical experiment with 29 survival datasets and 8 measures. We find that measures of discrimination are able to capture bias well whereas there is less clarity with measures of calibration and scoring rules. We suggest further areas for research including prediction-based fairness metrics for distribution predictions.