 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonty Hall and Optimized Conformal Prediction to Improve Decision-Making with LLMs
Dec 31, 2024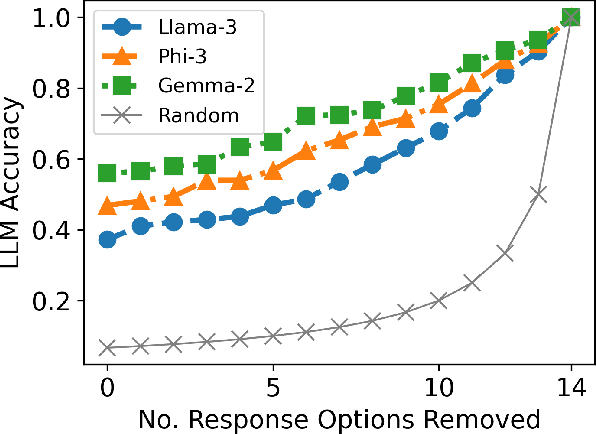
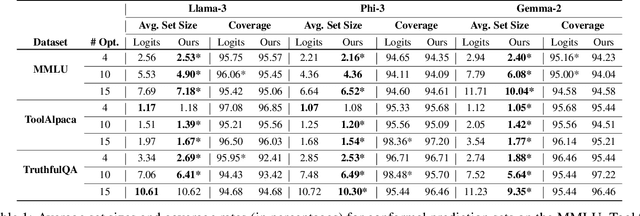
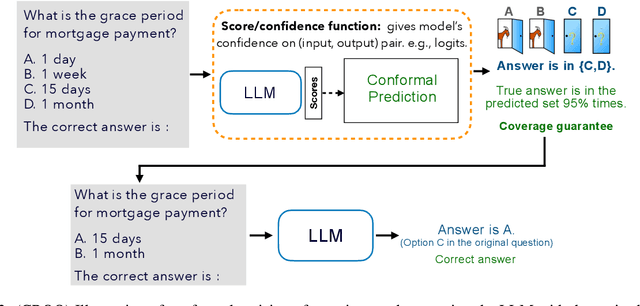
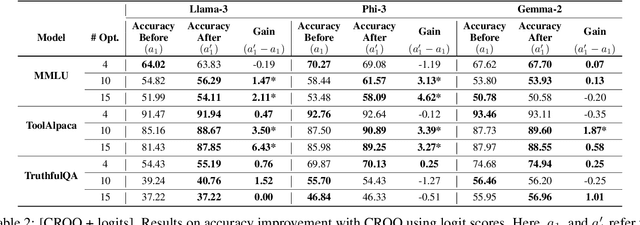
Large language models (LLMs) are empowering decision-making in several applications, including tool or API usage and answering multiple-choice questions (MCQs). However, they often make overconfident, incorrect predictions, which can be risky in high-stakes settings like healthcare and finance. To mitigate these risks, recent works have used conformal prediction (CP), a model-agnostic framework for distribution-free uncertainty quantification. CP transforms a \emph{score function} into prediction sets that contain the true answer with high probability. While CP provides this coverage guarantee for arbitrary scores, the score quality significantly impacts prediction set sizes. Prior works have relied on LLM logits or other heuristic scores, lacking quality guarantees. We address this limitation by introducing CP-OPT, an optimization framework to learn scores that minimize set sizes while maintaining coverage. Furthermore, inspired by the Monty Hall problem, we extend CP's utility beyond uncertainty quantification to improve accuracy. We propose \emph{conformal revision of questions} (CROQ) to revise the problem by narrowing down the available choices to those in the prediction set. The coverage guarantee of CP ensures that the correct choice is in the revised question prompt with high probability, while the smaller number of choices increases the LLM's chances of answering it correctly. Experiments on MMLU, ToolAlpaca, and TruthfulQA datasets with Gemma-2, Llama-3 and Phi-3 models show that CP-OPT significantly reduces set sizes while maintaining coverage, and CROQ improves accuracy over the standard inference, especially when paired with CP-OPT scores. Together, CP-OPT and CROQ offer a robust framework for improving both the safety and accuracy of LLM-driven decision-making.
Auditing and Enforcing Conditional Fairness via Optimal Transport
Oct 17, 2024

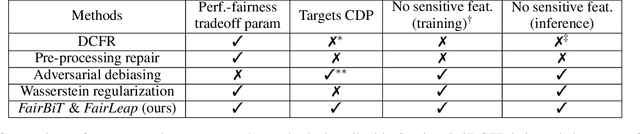

Conditional demographic parity (CDP) is a measure of the demographic parity of a predictive model or decision process when conditioning on an additional feature or set of features. Many algorithmic fairness techniques exist to target demographic parity, but CDP is much harder to achieve, particularly when the conditioning variable has many levels and/or when the model outputs are continuous. The problem of auditing and enforcing CDP is understudied in the literature. In light of this, we propose novel measures of {conditional demographic disparity (CDD)} which rely on statistical distances borrowed from the optimal transport literature. We further design and evaluate regularization-based approaches based on these CDD measures. Our methods, \fairbit{} and \fairlp{}, allow us to target CDP even when the conditioning variable has many levels. When model outputs are continuous, our methods target full equality of the conditional distributions, unlike other methods that only consider first moments or related proxy quantities. We validate the efficacy of our approaches on real-world datasets.
Semiparametric Efficient Inference in Adaptive Experiments
Nov 30, 2023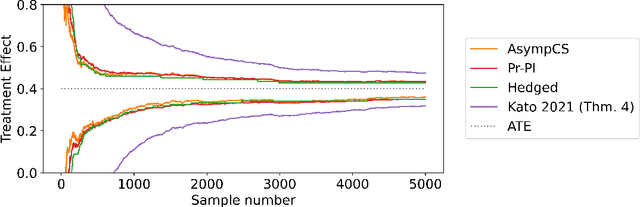
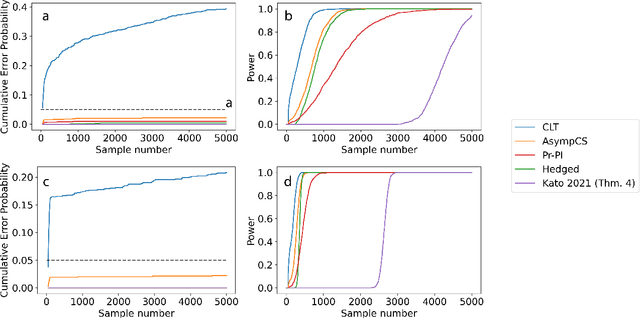
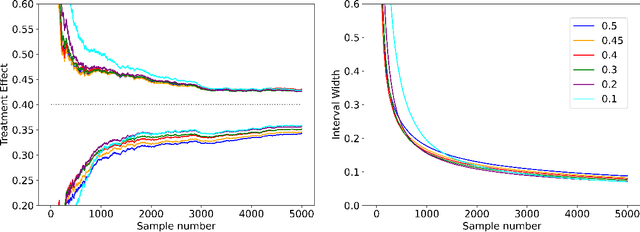
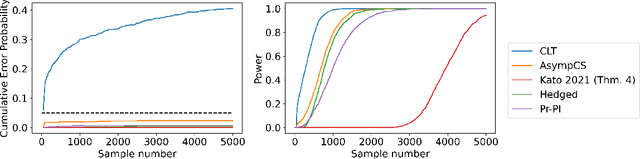
We consider the problem of efficient inference of the Average Treatment Effect in a sequential experiment where the policy governing the assignment of subjects to treatment or control can change over time. We first provide a central limit theorem for the Adaptive Augmented Inverse-Probability Weighted estimator, which is semiparametric efficient, under weaker assumptions than those previously made in the literature. This central limit theorem enables efficient inference at fixed sample sizes. We then consider a sequential inference setting, deriving both asymptotic and nonasymptotic confidence sequences that are considerably tighter than previous methods. These anytime-valid methods enable inference under data-dependent stopping times (sample sizes). Additionally, we use propensity score truncation techniques from the recent off-policy estimation literature to reduce the finite sample variance of our estimator without affecting the asymptotic variance. Empirical results demonstrate that our methods yield narrower confidence sequences than those previously developed in the literature while maintaining time-uniform error control.
FairWASP: Fast and Optimal Fair Wasserstein Pre-processing
Oct 31, 2023Recent years have seen a surge of machine learning approaches aimed at reducing disparities in model outputs across different subgroups. In many settings, training data may be used in multiple downstream applications by different users, which means it may be most effective to intervene on the training data itself. In this work, we present FairWASP, a novel pre-processing approach designed to reduce disparities in classification datasets without modifying the original data. FairWASP returns sample-level weights such that the reweighted dataset minimizes the Wasserstein distance to the original dataset while satisfying (an empirical version of) demographic parity, a popular fairness criterion. We show theoretically that integer weights are optimal, which means our method can be equivalently understood as duplicating or eliminating samples. FairWASP can therefore be used to construct datasets which can be fed into any classification method, not just methods which accept sample weights. Our work is based on reformulating the pre-processing task as a large-scale mixed-integer program (MIP), for which we propose a highly efficient algorithm based on the cutting plane method. Experiments on synthetic datasets demonstrate that our proposed optimization algorithm significantly outperforms state-of-the-art commercial solvers in solving both the MIP and its linear program relaxation. Further experiments highlight the competitive performance of FairWASP in reducing disparities while preserving accuracy in downstream classification settings.
Hyper-parameter Tuning for Fair Classification without Sensitive Attribute Access
Feb 02, 2023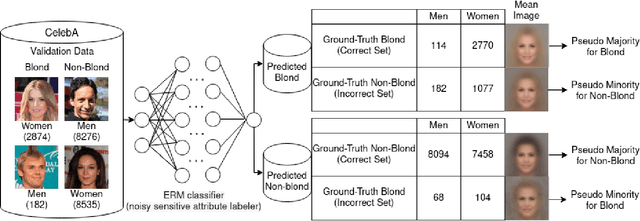


Fair machine learning methods seek to train models that balance model performance across demographic subgroups defined over sensitive attributes like race and gender. Although sensitive attributes are typically assumed to be known during training, they may not be available in practice due to privacy and other logistical concerns. Recent work has sought to train fair models without sensitive attributes on training data. However, these methods need extensive hyper-parameter tuning to achieve good results, and hence assume that sensitive attributes are known on validation data. However, this assumption too might not be practical. Here, we propose Antigone, a framework to train fair classifiers without access to sensitive attributes on either training or validation data. Instead, we generate pseudo sensitive attributes on the validation data by training a biased classifier and using the classifier's incorrectly (correctly) labeled examples as proxies for minority (majority) groups. Since fairness metrics like demographic parity, equal opportunity and subgroup accuracy can be estimated to within a proportionality constant even with noisy sensitive attribute information, we show theoretically and empirically that these proxy labels can be used to maximize fairness under average accuracy constraints. Key to our results is a principled approach to select the hyper-parameters of the biased classifier in a completely unsupervised fashion (meaning without access to ground truth sensitive attributes) that minimizes the gap between fairness estimated using noisy versus ground-truth sensitive labels.
Fairness via In-Processing in the Over-parameterized Regime: A Cautionary Tale
Jun 29, 2022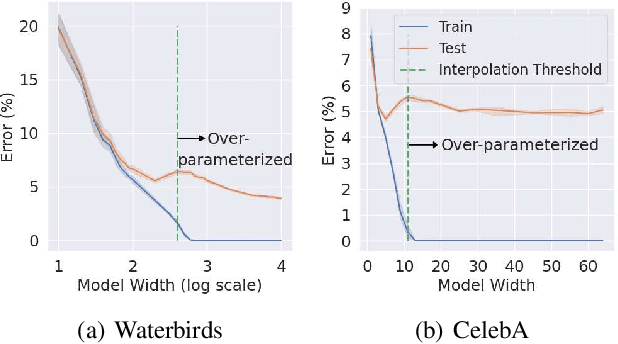
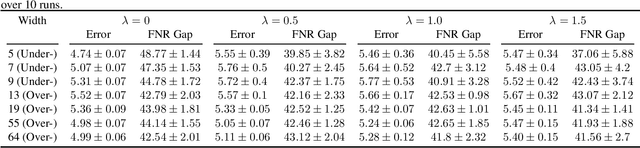
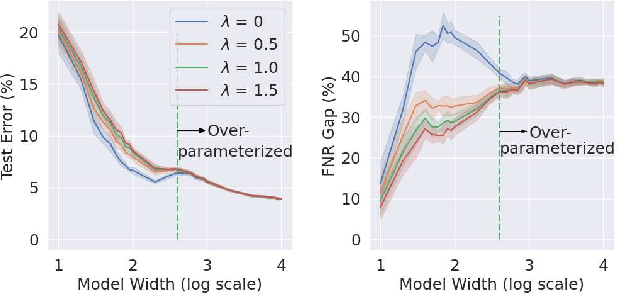

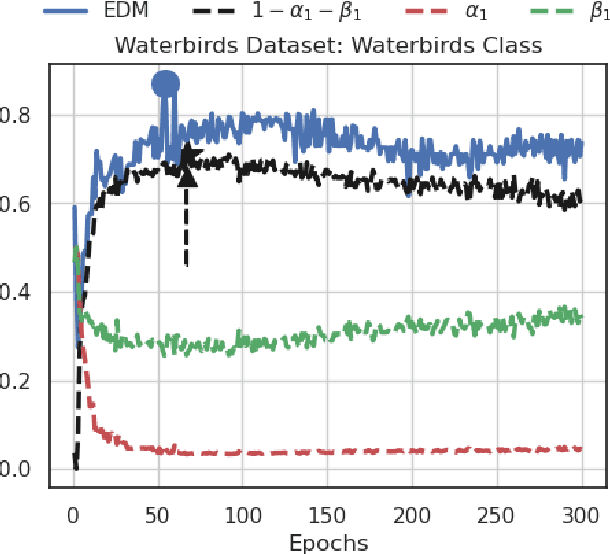
The success of DNNs is driven by the counter-intuitive ability of over-parameterized networks to generalize, even when they perfectly fit the training data. In practice, test error often continues to decrease with increasing over-parameterization, referred to as double descent. This allows practitioners to instantiate large models without having to worry about over-fitting. Despite its benefits, however, prior work has shown that over-parameterization can exacerbate bias against minority subgroups. Several fairness-constrained DNN training methods have been proposed to address this concern. Here, we critically examine MinDiff, a fairness-constrained training procedure implemented within TensorFlow's Responsible AI Toolkit, that aims to achieve Equality of Opportunity. We show that although MinDiff improves fairness for under-parameterized models, it is likely to be ineffective in the over-parameterized regime. This is because an overfit model with zero training loss is trivially group-wise fair on training data, creating an "illusion of fairness," thus turning off the MinDiff optimization (this will apply to any disparity-based measures which care about errors or accuracy. It won't apply to demographic parity). Within specified fairness constraints, under-parameterized MinDiff models can even have lower error compared to their over-parameterized counterparts (despite baseline over-parameterized models having lower error). We further show that MinDiff optimization is very sensitive to choice of batch size in the under-parameterized regime. Thus, fair model training using MinDiff requires time-consuming hyper-parameter searches. Finally, we suggest using previously proposed regularization techniques, viz. L2, early stopping and flooding in conjunction with MinDiff to train fair over-parameterized models.
Flexible Group Fairness Metrics for Survival Analysis
May 26, 2022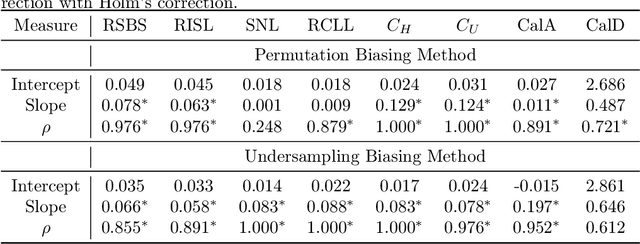
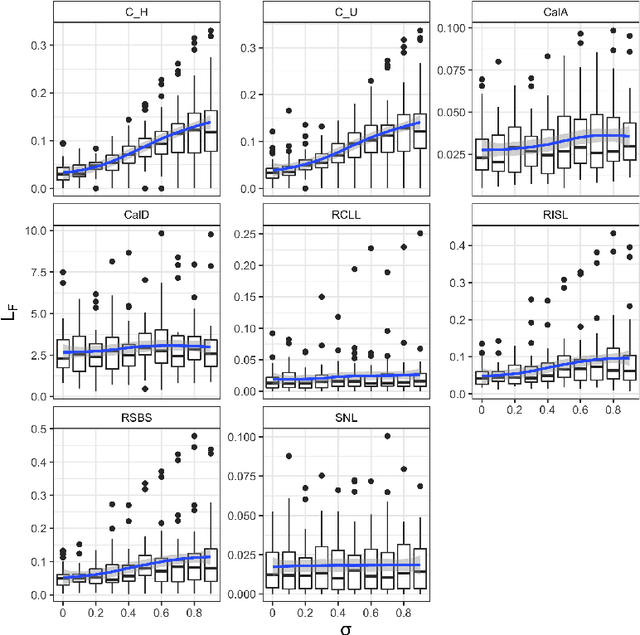
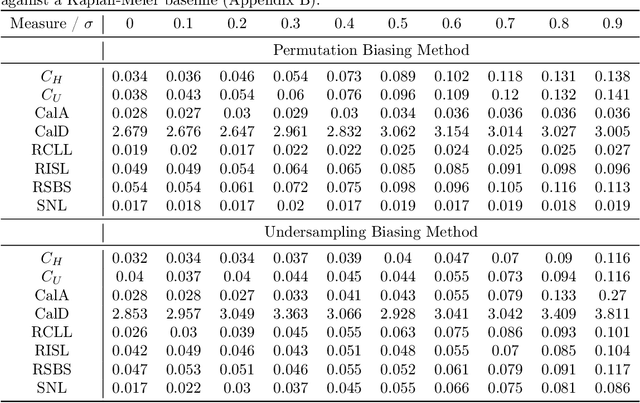
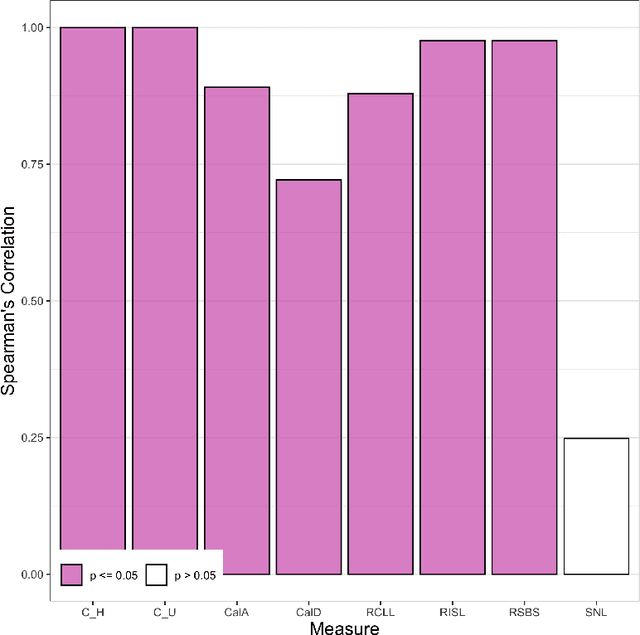
Algorithmic fairness is an increasingly important field concerned with detecting and mitigating biases in machine learning models. There has been a wealth of literature for algorithmic fairness in regression and classification however there has been little exploration of the field for survival analysis. Survival analysis is the prediction task in which one attempts to predict the probability of an event occurring over time. Survival predictions are particularly important in sensitive settings such as when utilising machine learning for diagnosis and prognosis of patients. In this paper we explore how to utilise existing survival metrics to measure bias with group fairness metrics. We explore this in an empirical experiment with 29 survival datasets and 8 measures. We find that measures of discrimination are able to capture bias well whereas there is less clarity with measures of calibration and scoring rules. We suggest further areas for research including prediction-based fairness metrics for distribution predictions.
Fair When Trained, Unfair When Deployed: Observable Fairness Measures are Unstable in Performative Prediction Settings
Feb 10, 2022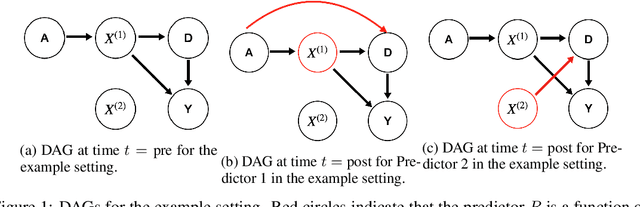

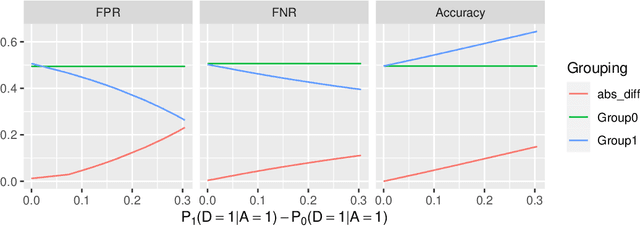
Many popular algorithmic fairness measures depend on the joint distribution of predictions, outcomes, and a sensitive feature like race or gender. These measures are sensitive to distribution shift: a predictor which is trained to satisfy one of these fairness definitions may become unfair if the distribution changes. In performative prediction settings, however, predictors are precisely intended to induce distribution shift. For example, in many applications in criminal justice, healthcare, and consumer finance, the purpose of building a predictor is to reduce the rate of adverse outcomes such as recidivism, hospitalization, or default on a loan. We formalize the effect of such predictors as a type of concept shift-a particular variety of distribution shift-and show both theoretically and via simulated examples how this causes predictors which are fair when they are trained to become unfair when they are deployed. We further show how many of these issues can be avoided by using fairness definitions that depend on counterfactual rather than observable outcomes.
FADE: FAir Double Ensemble Learning for Observable and Counterfactual Outcomes
Sep 01, 2021


Methods for building fair predictors often involve tradeoffs between fairness and accuracy and between different fairness criteria, but the nature of these tradeoffs varies. Recent work seeks to characterize these tradeoffs in specific problem settings, but these methods often do not accommodate users who wish to improve the fairness of an existing benchmark model without sacrificing accuracy, or vice versa. These results are also typically restricted to observable accuracy and fairness criteria. We develop a flexible framework for fair ensemble learning that allows users to efficiently explore the fairness-accuracy space or to improve the fairness or accuracy of a benchmark model. Our framework can simultaneously target multiple observable or counterfactual fairness criteria, and it enables users to combine a large number of previously trained and newly trained predictors. We provide theoretical guarantees that our estimators converge at fast rates. We apply our method on both simulated and real data, with respect to both observable and counterfactual accuracy and fairness criteria. We show that, surprisingly, multiple unfairness measures can sometimes be minimized simultaneously with little impact on accuracy, relative to unconstrained predictors or existing benchmark models.
Filtering Tweets for Social Unrest
Apr 01, 2017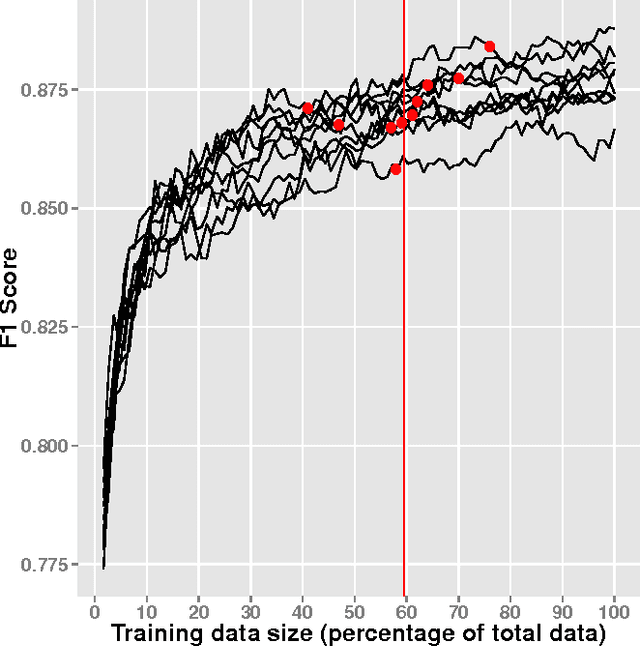
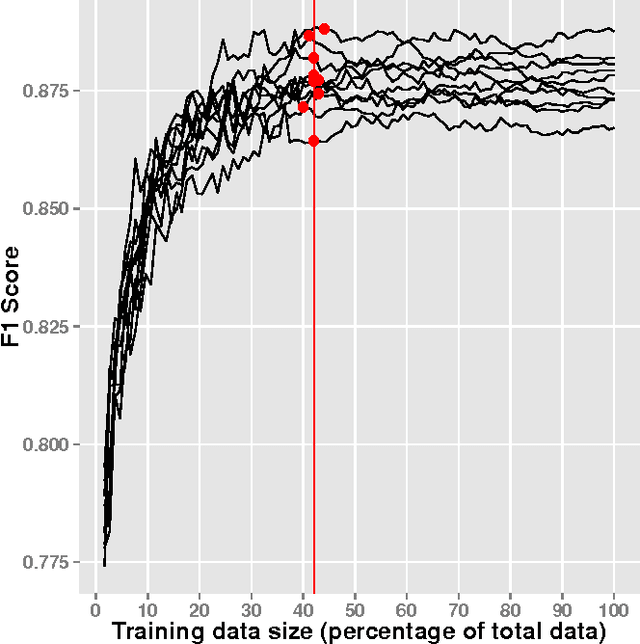
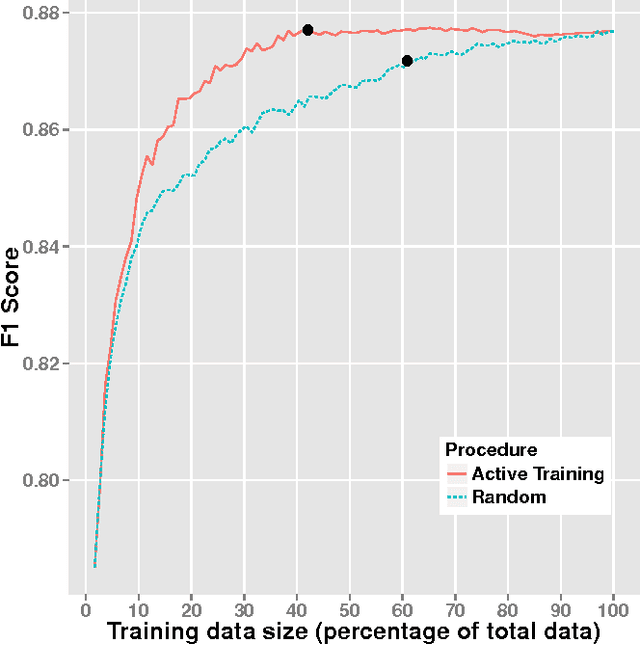
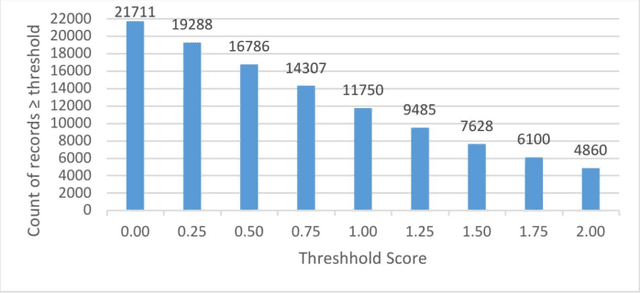
Since the events of the Arab Spring, there has been increased interest in using social media to anticipate social unrest. While efforts have been made toward automated unrest prediction, we focus on filtering the vast volume of tweets to identify tweets relevant to unrest, which can be provided to downstream users for further analysis. We train a supervised classifier that is able to label Arabic language tweets as relevant to unrest with high reliability. We examine the relationship between training data size and performance and investigate ways to optimize the model building process while minimizing cost. We also explore how confidence thresholds can be set to achieve desired levels of performance.
* 7 pages, 8 figures, 3 tables; published in Proceedings of the 2017 IEEE 11th International Conference on Semantic Computing (ICSC), San Diego, CA, USA, pages 17-23, January 2017