 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime To Impeach LLM-as-a-Judge: Programs are the Future of Evaluation
Jun 12, 2025Large language models (LLMs) are widely used to evaluate the quality of LLM generations and responses, but this leads to significant challenges: high API costs, uncertain reliability, inflexible pipelines, and inherent biases. To address these, we introduce PAJAMA (Program-As-a-Judge for Automated Model Assessment), a new alternative that uses LLMs to synthesize executable judging programs instead of directly scoring responses. These synthesized programs can be stored and run locally, costing orders of magnitude less while providing interpretable, and auditable judging logic that can be easily adapted. Program-based judges mitigate biases, improving judgment consistency by 15.83% and reducing biased responses by 23.7% on average compared to a Qwen2.5-14B-based LLM-as-a-judge. When program judgments are distilled into a model, PAJAMA outperforms LLM-as-a-judge on the challenging CHAT-HARD subset of RewardBench, outperforming metrics by 2.19% on Prometheus and 8.67% on the JudgeLM dataset, all at three orders of magnitude lower cost.
Adaptive Scoring and Thresholding with Human Feedback for Robust Out-of-Distribution Detection
May 05, 2025Machine Learning (ML) models are trained on in-distribution (ID) data but often encounter out-of-distribution (OOD) inputs during deployment -- posing serious risks in safety-critical domains. Recent works have focused on designing scoring functions to quantify OOD uncertainty, with score thresholds typically set based solely on ID data to achieve a target true positive rate (TPR), since OOD data is limited before deployment. However, these TPR-based thresholds leave false positive rates (FPR) uncontrolled, often resulting in high FPRs where OOD points are misclassified as ID. Moreover, fixed scoring functions and thresholds lack the adaptivity needed to handle newly observed, evolving OOD inputs, leading to sub-optimal performance. To address these challenges, we propose a human-in-the-loop framework that \emph{safely updates both scoring functions and thresholds on the fly} based on real-world OOD inputs. Our method maximizes TPR while strictly controlling FPR at all times, even as the system adapts over time. We provide theoretical guarantees for FPR control under stationary conditions and present extensive empirical evaluations on OpenOOD benchmarks to demonstrate that our approach outperforms existing methods by achieving higher TPRs while maintaining FPR control.
ScriptoriumWS: A Code Generation Assistant for Weak Supervision
Feb 17, 2025Weak supervision is a popular framework for overcoming the labeled data bottleneck: the need to obtain labels for training data. In weak supervision, multiple noisy-but-cheap sources are used to provide guesses of the label and are aggregated to produce high-quality pseudolabels. These sources are often expressed as small programs written by domain experts -- and so are expensive to obtain. Instead, we argue for using code-generation models to act as coding assistants for crafting weak supervision sources. We study prompting strategies to maximize the quality of the generated sources, settling on a multi-tier strategy that incorporates multiple types of information. We explore how to best combine hand-written and generated sources. Using these insights, we introduce ScriptoriumWS, a weak supervision system that, when compared to hand-crafted sources, maintains accuracy and greatly improves coverage.
Monty Hall and Optimized Conformal Prediction to Improve Decision-Making with LLMs
Dec 31, 2024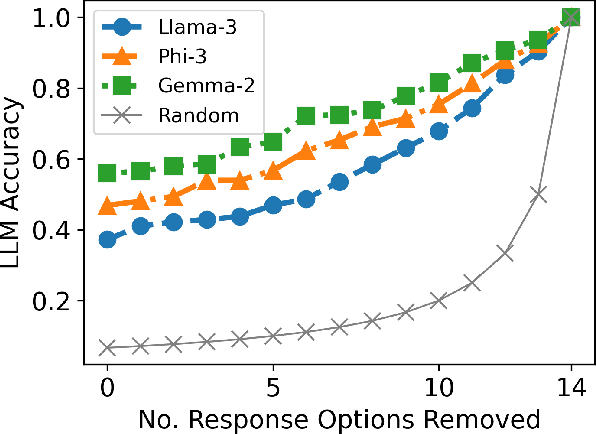
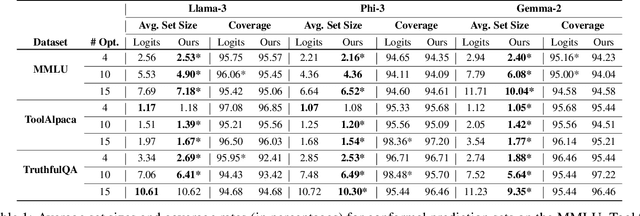
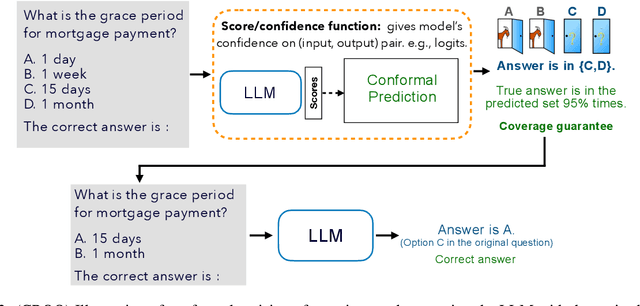
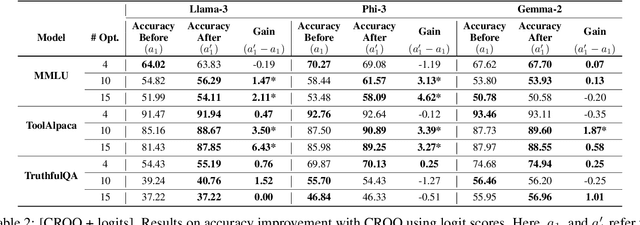
Large language models (LLMs) are empowering decision-making in several applications, including tool or API usage and answering multiple-choice questions (MCQs). However, they often make overconfident, incorrect predictions, which can be risky in high-stakes settings like healthcare and finance. To mitigate these risks, recent works have used conformal prediction (CP), a model-agnostic framework for distribution-free uncertainty quantification. CP transforms a \emph{score function} into prediction sets that contain the true answer with high probability. While CP provides this coverage guarantee for arbitrary scores, the score quality significantly impacts prediction set sizes. Prior works have relied on LLM logits or other heuristic scores, lacking quality guarantees. We address this limitation by introducing CP-OPT, an optimization framework to learn scores that minimize set sizes while maintaining coverage. Furthermore, inspired by the Monty Hall problem, we extend CP's utility beyond uncertainty quantification to improve accuracy. We propose \emph{conformal revision of questions} (CROQ) to revise the problem by narrowing down the available choices to those in the prediction set. The coverage guarantee of CP ensures that the correct choice is in the revised question prompt with high probability, while the smaller number of choices increases the LLM's chances of answering it correctly. Experiments on MMLU, ToolAlpaca, and TruthfulQA datasets with Gemma-2, Llama-3 and Phi-3 models show that CP-OPT significantly reduces set sizes while maintaining coverage, and CROQ improves accuracy over the standard inference, especially when paired with CP-OPT scores. Together, CP-OPT and CROQ offer a robust framework for improving both the safety and accuracy of LLM-driven decision-making.
Taming False Positives in Out-of-Distribution Detection with Human Feedback
Apr 25, 2024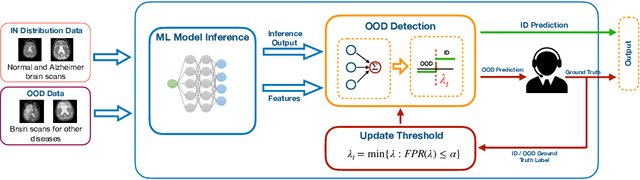

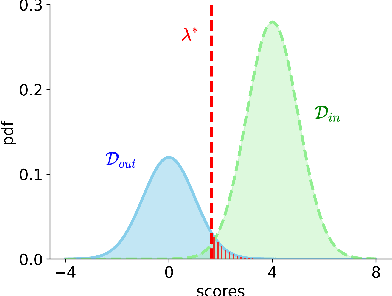

Robustness to out-of-distribution (OOD) samples is crucial for safely deploying machine learning models in the open world. Recent works have focused on designing scoring functions to quantify OOD uncertainty. Setting appropriate thresholds for these scoring functions for OOD detection is challenging as OOD samples are often unavailable up front. Typically, thresholds are set to achieve a desired true positive rate (TPR), e.g., $95\%$ TPR. However, this can lead to very high false positive rates (FPR), ranging from 60 to 96\%, as observed in the Open-OOD benchmark. In safety-critical real-life applications, e.g., medical diagnosis, controlling the FPR is essential when dealing with various OOD samples dynamically. To address these challenges, we propose a mathematically grounded OOD detection framework that leverages expert feedback to \emph{safely} update the threshold on the fly. We provide theoretical results showing that it is guaranteed to meet the FPR constraint at all times while minimizing the use of human feedback. Another key feature of our framework is that it can work with any scoring function for OOD uncertainty quantification. Empirical evaluation of our system on synthetic and benchmark OOD datasets shows that our method can maintain FPR at most $5\%$ while maximizing TPR.
* Appeared in the 27th International Conference on Artificial Intelligence and Statistics (AISTATS 2024)
Pearls from Pebbles: Improved Confidence Functions for Auto-labeling
Apr 24, 2024



Auto-labeling is an important family of techniques that produce labeled training sets with minimum manual labeling. A prominent variant, threshold-based auto-labeling (TBAL), works by finding a threshold on a model's confidence scores above which it can accurately label unlabeled data points. However, many models are known to produce overconfident scores, leading to poor TBAL performance. While a natural idea is to apply off-the-shelf calibration methods to alleviate the overconfidence issue, such methods still fall short. Rather than experimenting with ad-hoc choices of confidence functions, we propose a framework for studying the \emph{optimal} TBAL confidence function. We develop a tractable version of the framework to obtain \texttt{Colander} (Confidence functions for Efficient and Reliable Auto-labeling), a new post-hoc method specifically designed to maximize performance in TBAL systems. We perform an extensive empirical evaluation of our method \texttt{Colander} and compare it against methods designed for calibration. \texttt{Colander} achieves up to 60\% improvements on coverage over the baselines while maintaining auto-labeling error below $5\%$ and using the same amount of labeled data as the baselines.
OTTER: Improving Zero-Shot Classification via Optimal Transport
Apr 12, 2024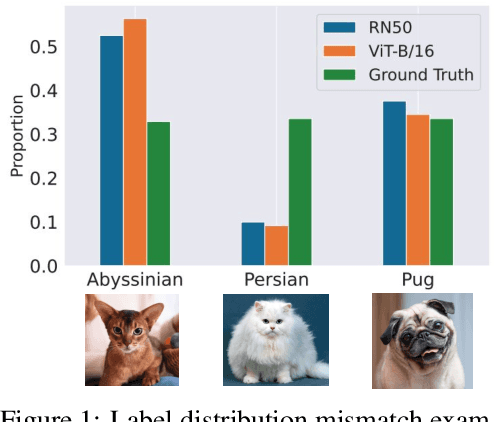
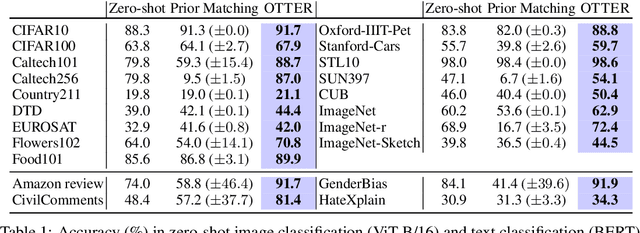
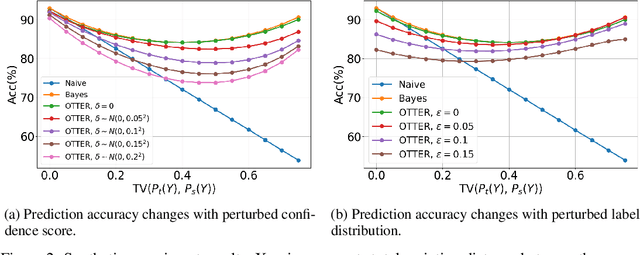
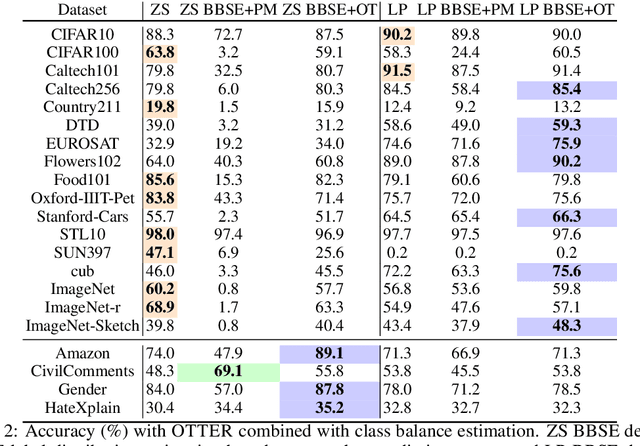
Popular zero-shot models suffer due to artifacts inherited from pretraining. A particularly detrimental artifact, caused by unbalanced web-scale pretraining data, is mismatched label distribution. Existing approaches that seek to repair the label distribution are not suitable in zero-shot settings, as they have incompatible requirements such as access to labeled downstream task data or knowledge of the true label balance in the pretraining distribution. We sidestep these challenges and introduce a simple and lightweight approach to adjust pretrained model predictions via optimal transport. Our technique requires only an estimate of the label distribution of a downstream task. Theoretically, we characterize the improvement produced by our procedure under certain mild conditions and provide bounds on the error caused by misspecification. Empirically, we validate our method in a wide array of zero-shot image and text classification tasks, improving accuracy by 4.8% and 15.9% on average, and beating baselines like Prior Matching -- often by significant margins -- in 17 out of 21 datasets.
Train 'n Trade: Foundations of Parameter Markets
Dec 07, 2023


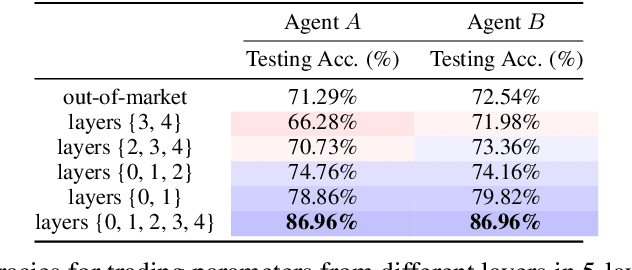
Organizations typically train large models individually. This is costly and time-consuming, particularly for large-scale foundation models. Such vertical production is known to be suboptimal. Inspired by this economic insight, we ask whether it is possible to leverage others' expertise by trading the constituent parts in models, i.e., sets of weights, as if they were market commodities. While recent advances in aligning and interpolating models suggest that doing so may be possible, a number of fundamental questions must be answered to create viable parameter markets. In this work, we address these basic questions, propose a framework containing the infrastructure necessary for market operations to take place, study strategies for exchanging parameters, and offer means for agents to monetize parameters. Excitingly, compared to agents who train siloed models from scratch, we show that it is possible to mutually gain by using the market, even in competitive settings. This suggests that the notion of parameter markets may be a useful paradigm for improving large-scale model training in the future.
Lifting Weak Supervision To Structured Prediction
Nov 24, 2022

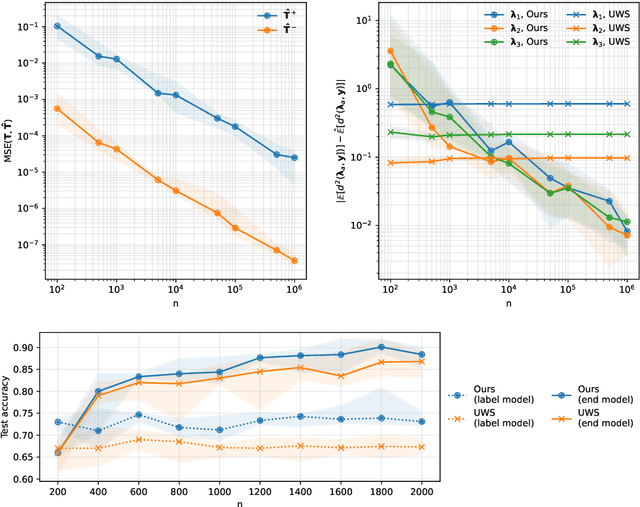
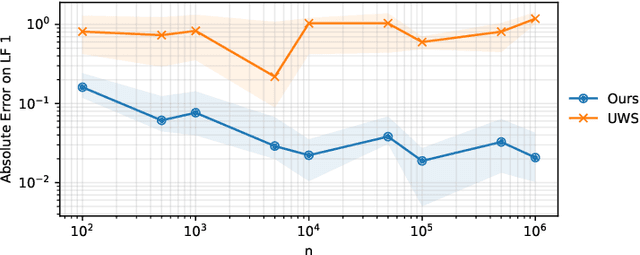
Weak supervision (WS) is a rich set of techniques that produce pseudolabels by aggregating easily obtained but potentially noisy label estimates from a variety of sources. WS is theoretically well understood for binary classification, where simple approaches enable consistent estimation of pseudolabel noise rates. Using this result, it has been shown that downstream models trained on the pseudolabels have generalization guarantees nearly identical to those trained on clean labels. While this is exciting, users often wish to use WS for structured prediction, where the output space consists of more than a binary or multi-class label set: e.g. rankings, graphs, manifolds, and more. Do the favorable theoretical properties of WS for binary classification lift to this setting? We answer this question in the affirmative for a wide range of scenarios. For labels taking values in a finite metric space, we introduce techniques new to weak supervision based on pseudo-Euclidean embeddings and tensor decompositions, providing a nearly-consistent noise rate estimator. For labels in constant-curvature Riemannian manifolds, we introduce new invariants that also yield consistent noise rate estimation. In both cases, when using the resulting pseudolabels in concert with a flexible downstream model, we obtain generalization guarantees nearly identical to those for models trained on clean data. Several of our results, which can be viewed as robustness guarantees in structured prediction with noisy labels, may be of independent interest. Empirical evaluation validates our claims and shows the merits of the proposed method.
Good Data from Bad Models : Foundations of Threshold-based Auto-labeling
Nov 22, 2022
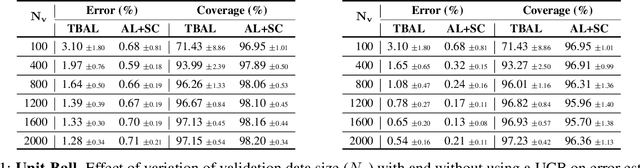

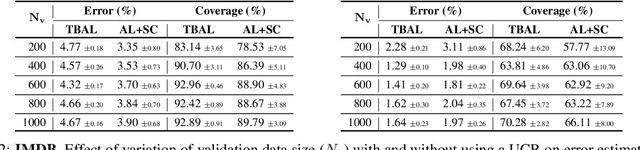
Creating large-scale high-quality labeled datasets is a major bottleneck in supervised machine learning workflows. Auto-labeling systems are a promising way to reduce reliance on manual labeling for dataset construction. Threshold-based auto-labeling, where validation data obtained from humans is used to find a threshold for confidence above which the data is machine-labeled, is emerging as a popular solution used widely in practice. Given the long shelf-life and diverse usage of the resulting datasets, understanding when the data obtained by such auto-labeling systems can be relied on is crucial. In this work, we analyze threshold-based auto-labeling systems and derive sample complexity bounds on the amount of human-labeled validation data required for guaranteeing the quality of machine-labeled data. Our results provide two insights. First, reasonable chunks of the unlabeled data can be automatically and accurately labeled by seemingly bad models. Second, a hidden downside of threshold-based auto-labeling systems is potentially prohibitive validation data usage. Together, these insights describe the promise and pitfalls of using such systems. We validate our theoretical guarantees with simulations and study the efficacy of threshold-based auto-labeling on real datasets.