 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabby: Tabular Data Synthesis with Language Models
Mar 04, 2025



While advances in large language models (LLMs) have greatly improved the quality of synthetic text data in recent years, synthesizing tabular data has received relatively less attention. We address this disparity with Tabby, a simple but powerful post-training modification to the standard Transformer language model architecture, enabling its use for tabular dataset synthesis. Tabby enables the representation of differences across columns using Gated Mixture-of-Experts, with column-specific sets of parameters. Empirically, Tabby results in data quality near or equal to that of real data. By pairing our novel LLM table training technique, Plain, with Tabby, we observe up to a 44% improvement in quality over previous methods. We also show that Tabby extends beyond tables to more general structured data, reaching parity with real data on a nested JSON dataset as well.
Pretrained Hybrids with MAD Skills
Jun 02, 2024



While Transformers underpin modern large language models (LMs), there is a growing list of alternative architectures with new capabilities, promises, and tradeoffs. This makes choosing the right LM architecture challenging. Recently-proposed $\textit{hybrid architectures}$ seek a best-of-all-worlds approach that reaps the benefits of all architectures. Hybrid design is difficult for two reasons: it requires manual expert-driven search, and new hybrids must be trained from scratch. We propose $\textbf{Manticore}$, a framework that addresses these challenges. Manticore $\textit{automates the design of hybrid architectures}$ while reusing pretrained models to create $\textit{pretrained}$ hybrids. Our approach augments ideas from differentiable Neural Architecture Search (NAS) by incorporating simple projectors that translate features between pretrained blocks from different architectures. We then fine-tune hybrids that combine pretrained models from different architecture families -- such as the GPT series and Mamba -- end-to-end. With Manticore, we enable LM selection without training multiple models, the construction of pretrained hybrids from existing pretrained models, and the ability to $\textit{program}$ pretrained hybrids to have certain capabilities. Manticore hybrids outperform existing manually-designed hybrids, achieve strong performance on Long Range Arena (LRA) tasks, and can improve on pretrained transformers and state space models.
OTTER: Improving Zero-Shot Classification via Optimal Transport
Apr 12, 2024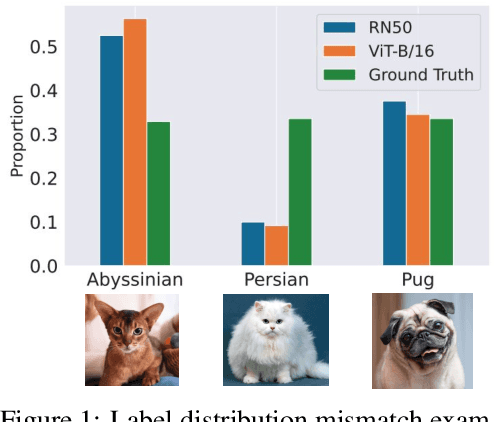
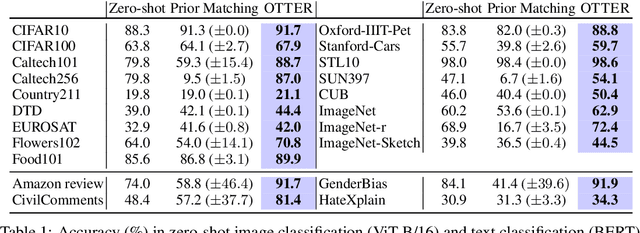
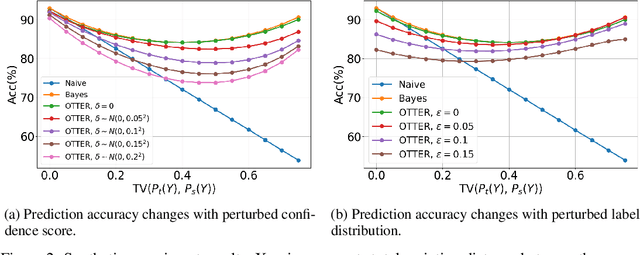
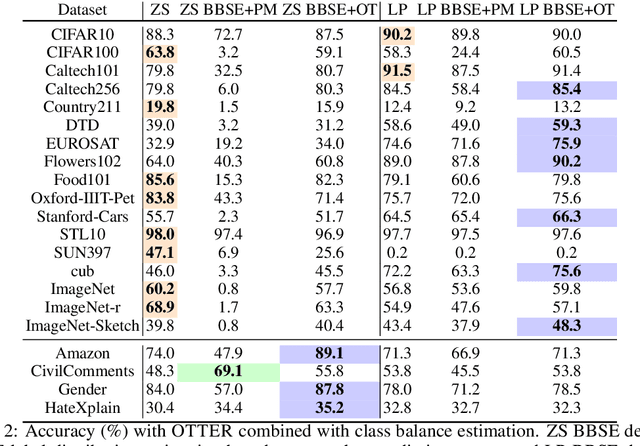
Popular zero-shot models suffer due to artifacts inherited from pretraining. A particularly detrimental artifact, caused by unbalanced web-scale pretraining data, is mismatched label distribution. Existing approaches that seek to repair the label distribution are not suitable in zero-shot settings, as they have incompatible requirements such as access to labeled downstream task data or knowledge of the true label balance in the pretraining distribution. We sidestep these challenges and introduce a simple and lightweight approach to adjust pretrained model predictions via optimal transport. Our technique requires only an estimate of the label distribution of a downstream task. Theoretically, we characterize the improvement produced by our procedure under certain mild conditions and provide bounds on the error caused by misspecification. Empirically, we validate our method in a wide array of zero-shot image and text classification tasks, improving accuracy by 4.8% and 15.9% on average, and beating baselines like Prior Matching -- often by significant margins -- in 17 out of 21 datasets.
Geometry-Aware Adaptation for Pretrained Models
Jul 23, 2023

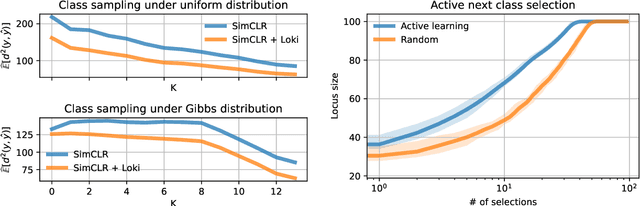

Machine learning models -- including prominent zero-shot models -- are often trained on datasets whose labels are only a small proportion of a larger label space. Such spaces are commonly equipped with a metric that relates the labels via distances between them. We propose a simple approach to exploit this information to adapt the trained model to reliably predict new classes -- or, in the case of zero-shot prediction, to improve its performance -- without any additional training. Our technique is a drop-in replacement of the standard prediction rule, swapping argmax with the Fr\'echet mean. We provide a comprehensive theoretical analysis for this approach, studying (i) learning-theoretic results trading off label space diameter, sample complexity, and model dimension, (ii) characterizations of the full range of scenarios in which it is possible to predict any unobserved class, and (iii) an optimal active learning-like next class selection procedure to obtain optimal training classes for when it is not possible to predict the entire range of unobserved classes. Empirically, using easily-available external metrics, our proposed approach, Loki, gains up to 29.7% relative improvement over SimCLR on ImageNet and scales to hundreds of thousands of classes. When no such metric is available, Loki can use self-derived metrics from class embeddings and obtains a 10.5% improvement on pretrained zero-shot models such as CLIP.
Mitigating Source Bias for Fairer Weak Supervision
Mar 30, 2023
Weak supervision overcomes the label bottleneck, enabling efficient development of training sets. Millions of models trained on such datasets have been deployed in the real world and interact with users on a daily basis. However, the techniques that make weak supervision attractive -- such as integrating any source of signal to estimate unknown labels -- also ensure that the pseudolabels it produces are highly biased. Surprisingly, given everyday use and the potential for increased bias, weak supervision has not been studied from the point of view of fairness. This work begins such a study. Our departure point is the observation that even when a fair model can be built from a dataset with access to ground-truth labels, the corresponding dataset labeled via weak supervision can be arbitrarily unfair. Fortunately, not all is lost: we propose and empirically validate a model for source unfairness in weak supervision, then introduce a simple counterfactual fairness-based technique that can mitigate these biases. Theoretically, we show that it is possible for our approach to simultaneously improve both accuracy and fairness metrics -- in contrast to standard fairness approaches that suffer from tradeoffs. Empirically, we show that our technique improves accuracy on weak supervision baselines by as much as 32% while reducing demographic parity gap by 82.5%.
Relational Boosted Regression Trees
Jul 25, 2021Many tasks use data housed in relational databases to train boosted regression tree models. In this paper, we give a relational adaptation of the greedy algorithm for training boosted regression trees. For the subproblem of calculating the sum of squared residuals of the dataset, which dominates the runtime of the boosting algorithm, we provide a $(1 + \epsilon)$-approximation using the tensor sketch technique. Employing this approximation within the relational boosted regression trees algorithm leads to learning similar model parameters, but with asymptotically better runtime.