 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlopCodeBench: Benchmarking How Coding Agents Degrade Over Long-Horizon Iterative Tasks
Mar 25, 2026Software development is iterative, yet agentic coding benchmarks overwhelmingly evaluate single-shot solutions against complete specifications. Code can pass the test suite but become progressively harder to extend. Recent iterative benchmarks attempt to close this gap, but constrain the agent's design decisions too tightly to faithfully measure how code quality shapes future extensions. We introduce SlopCodeBench, a language-agnostic benchmark comprising 20 problems and 93 checkpoints, in which agents repeatedly extend their own prior solutions under evolving specifications that force architectural decisions without prescribing internal structure. We track two trajectory-level quality signals: verbosity, the fraction of redundant or duplicated code, and structural erosion, the share of complexity mass concentrated in high-complexity functions. No agent solves any problem end-to-end across 11 models; the highest checkpoint solve rate is 17.2%. Quality degrades steadily: erosion rises in 80% of trajectories and verbosity in 89.8%. Against 48 open-source Python repositories, agent code is 2.2x more verbose and markedly more eroded. Tracking 20 of those repositories over time shows that human code stays flat, while agent code deteriorates with each iteration. A prompt-intervention study shows that initial quality can be improved, but it does not halt degradation. These results demonstrate that pass-rate benchmarks systematically undermeasure extension robustness, and that current agents lack the design discipline iterative software development demands.
Grow, Don't Overwrite: Fine-tuning Without Forgetting
Mar 09, 2026Adapting pre-trained models to specialized tasks often leads to catastrophic forgetting, where new knowledge overwrites foundational capabilities. Existing methods either compromise performance on the new task or struggle to balance training stability with efficient reuse of pre-trained knowledge. We introduce a novel function-preserving expansion method that resolves this dilemma. Our technique expands model capacity by replicating pre-trained parameters within transformer submodules and applying a scaling correction that guarantees the expanded model is mathematically identical to the original at initialization, enabling stable training while exploiting existing knowledge. Empirically, our method eliminates the trade-off between plasticity and stability, matching the performance of full fine-tuning on downstream tasks without any degradation of the model's original capabilities. Furthermore, we demonstrate the modularity of our approach, showing that by selectively expanding a small subset of layers we can achieve the same performance as full fine-tuning at a fraction of the computational cost.
Weight Updates as Activation Shifts: A Principled Framework for Steering
Feb 28, 2026Activation steering promises to be an extremely parameter-efficient form of adaptation, but its effectiveness depends on critical design choices -- such as intervention location and parameterization -- that currently rely on empirical heuristics rather than a principled foundation. We establish a first-order equivalence between activation-space interventions and weight-space updates, deriving the conditions under which activation steering can replicate fine-tuning behavior. This equivalence yields a principled framework for steering design and identifies the post-block output as a theoretically-backed and highly expressive intervention site. We further explain why certain intervention locations outperform others and show that weight updates and activation updates play distinct, complementary functional roles. This analysis motivates a new approach -- joint adaptation -- that trains in both spaces simultaneously. Our post-block steering achieves accuracy within 0.2%-0.9%$ of full-parameter tuning, on average across tasks and models, while training only 0.04% of model parameters. It consistently outperforms prior activation steering methods such as ReFT and PEFT approaches including LoRA, while using significantly fewer parameters. Finally, we show that joint adaptation often surpasses the performance ceilings of weight and activation updates in isolation, introducing a new paradigm for efficient model adaptation.
CrEst: Credibility Estimation for Contexts in LLMs via Weak Supervision
Jun 17, 2025The integration of contextual information has significantly enhanced the performance of large language models (LLMs) on knowledge-intensive tasks. However, existing methods often overlook a critical challenge: the credibility of context documents can vary widely, potentially leading to the propagation of unreliable information. In this paper, we introduce CrEst, a novel weakly supervised framework for assessing the credibility of context documents during LLM inference--without requiring manual annotations. Our approach is grounded in the insight that credible documents tend to exhibit higher semantic coherence with other credible documents, enabling automated credibility estimation through inter-document agreement. To incorporate credibility into LLM inference, we propose two integration strategies: a black-box approach for models without access to internal weights or activations, and a white-box method that directly modifies attention mechanisms. Extensive experiments across three model architectures and five datasets demonstrate that CrEst consistently outperforms strong baselines, achieving up to a 26.86% improvement in accuracy and a 3.49% increase in F1 score. Further analysis shows that CrEst maintains robust performance even under high-noise conditions.
Personalize Your LLM: Fake it then Align it
Mar 05, 2025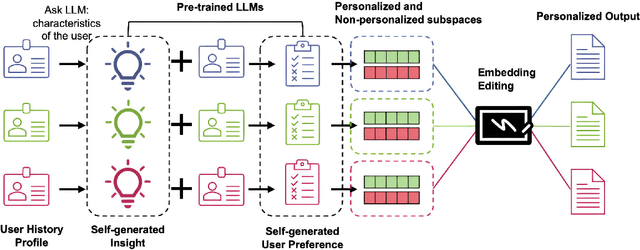

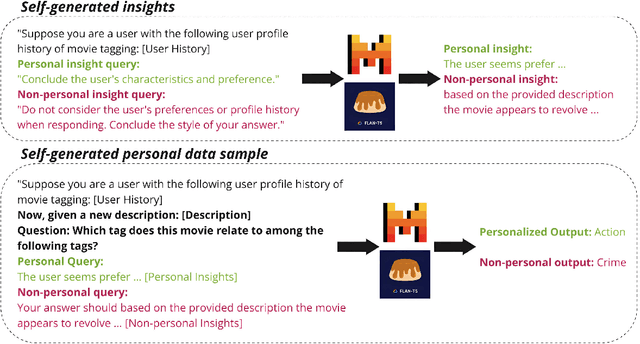

Personalizing large language models (LLMs) is essential for delivering tailored interactions that improve user experience. Many existing personalization methods require fine-tuning LLMs for each user, rendering them prohibitively expensive for widespread adoption. Although retrieval-based approaches offer a more compute-efficient alternative, they still depend on large, high-quality datasets that are not consistently available for all users. To address this challenge, we propose CHAMELEON, a scalable and efficient personalization approach that uses (1) self-generated personal preference data and (2) representation editing to enable quick and cost-effective personalization. Our experiments on various tasks, including those from the LaMP personalization benchmark, show that CHAMELEON efficiently adapts models to personal preferences, improving instruction-tuned models and outperforms two personalization baselines by an average of 40% across two model architectures.
Discovering Bias in Latent Space: An Unsupervised Debiasing Approach
Jun 05, 2024The question-answering (QA) capabilities of foundation models are highly sensitive to prompt variations, rendering their performance susceptible to superficial, non-meaning-altering changes. This vulnerability often stems from the model's preference or bias towards specific input characteristics, such as option position or superficial image features in multi-modal settings. We propose to rectify this bias directly in the model's internal representation. Our approach, SteerFair, finds the bias direction in the model's representation space and steers activation values away from it during inference. Specifically, we exploit the observation that bias often adheres to simple association rules, such as the spurious association between the first option and correctness likelihood. Next, we construct demonstrations of these rules from unlabeled samples and use them to identify the bias directions. We empirically show that SteerFair significantly reduces instruction-tuned model performance variance across prompt modifications on three benchmark tasks. Remarkably, our approach surpasses a supervised baseline with 100 labels by an average of 10.86% accuracy points and 12.95 score points and matches the performance with 500 labels.
Is Free Self-Alignment Possible?
Jun 05, 2024Aligning pretrained language models (LMs) is a complex and resource-intensive process, often requiring access to large amounts of ground-truth preference data and substantial compute. Are these costs necessary? That is, it is possible to align using only inherent model knowledge and without additional training? We tackle this challenge with AlignEZ, a novel approach that uses (1) self-generated preference data and (2) representation editing to provide nearly cost-free alignment. During inference, AlignEZ modifies LM representations to reduce undesirable and boost desirable components using subspaces identified via self-generated preference pairs. Our experiments reveal that this nearly cost-free procedure significantly narrows the gap between base pretrained and tuned models by an average of 31.6%, observed across six datasets and three model architectures. Additionally, we explore the potential of using AlignEZ as a means of expediting more expensive alignment procedures. Our experiments show that AlignEZ improves DPO models tuned only using a small subset of ground-truth preference data. Lastly, we study the conditions under which improvement using AlignEZ is feasible, providing valuable insights into its effectiveness.
Zero-Shot Robustification of Zero-Shot Models With Foundation Models
Sep 08, 2023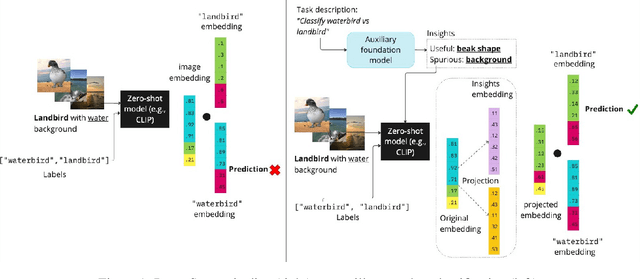
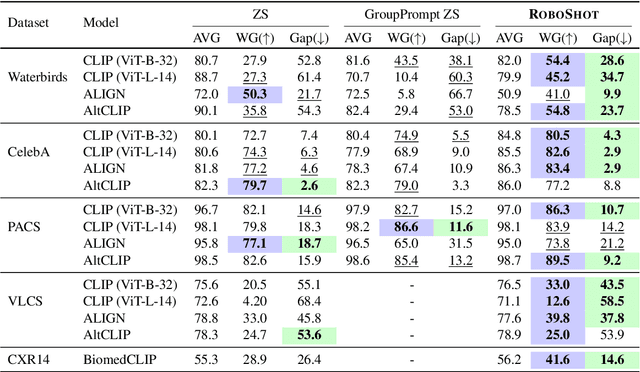
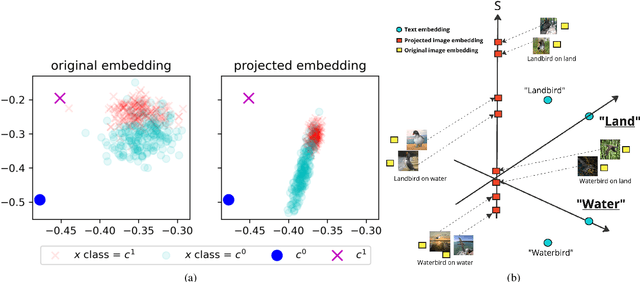
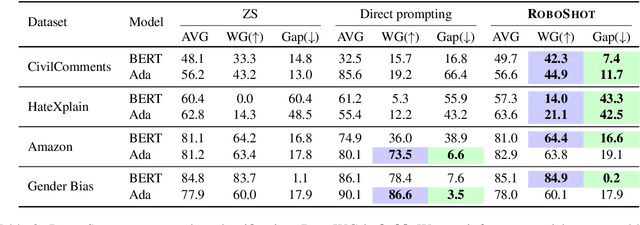
Zero-shot inference is a powerful paradigm that enables the use of large pretrained models for downstream classification tasks without further training. However, these models are vulnerable to inherited biases that can impact their performance. The traditional solution is fine-tuning, but this undermines the key advantage of pretrained models, which is their ability to be used out-of-the-box. We propose RoboShot, a method that improves the robustness of pretrained model embeddings in a fully zero-shot fashion. First, we use zero-shot language models (LMs) to obtain useful insights from task descriptions. These insights are embedded and used to remove harmful and boost useful components in embeddings -- without any supervision. Theoretically, we provide a simple and tractable model for biases in zero-shot embeddings and give a result characterizing under what conditions our approach can boost performance. Empirically, we evaluate RoboShot on nine image and NLP classification tasks and show an average improvement of 15.98% over several zero-shot baselines. Additionally, we demonstrate that RoboShot is compatible with a variety of pretrained and language models.
Geometry-Aware Adaptation for Pretrained Models
Jul 23, 2023

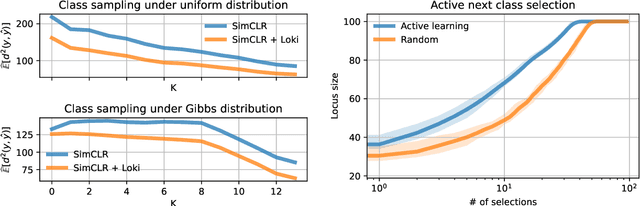

Machine learning models -- including prominent zero-shot models -- are often trained on datasets whose labels are only a small proportion of a larger label space. Such spaces are commonly equipped with a metric that relates the labels via distances between them. We propose a simple approach to exploit this information to adapt the trained model to reliably predict new classes -- or, in the case of zero-shot prediction, to improve its performance -- without any additional training. Our technique is a drop-in replacement of the standard prediction rule, swapping argmax with the Fr\'echet mean. We provide a comprehensive theoretical analysis for this approach, studying (i) learning-theoretic results trading off label space diameter, sample complexity, and model dimension, (ii) characterizations of the full range of scenarios in which it is possible to predict any unobserved class, and (iii) an optimal active learning-like next class selection procedure to obtain optimal training classes for when it is not possible to predict the entire range of unobserved classes. Empirically, using easily-available external metrics, our proposed approach, Loki, gains up to 29.7% relative improvement over SimCLR on ImageNet and scales to hundreds of thousands of classes. When no such metric is available, Loki can use self-derived metrics from class embeddings and obtains a 10.5% improvement on pretrained zero-shot models such as CLIP.
Mitigating Source Bias for Fairer Weak Supervision
Mar 30, 2023
Weak supervision overcomes the label bottleneck, enabling efficient development of training sets. Millions of models trained on such datasets have been deployed in the real world and interact with users on a daily basis. However, the techniques that make weak supervision attractive -- such as integrating any source of signal to estimate unknown labels -- also ensure that the pseudolabels it produces are highly biased. Surprisingly, given everyday use and the potential for increased bias, weak supervision has not been studied from the point of view of fairness. This work begins such a study. Our departure point is the observation that even when a fair model can be built from a dataset with access to ground-truth labels, the corresponding dataset labeled via weak supervision can be arbitrarily unfair. Fortunately, not all is lost: we propose and empirically validate a model for source unfairness in weak supervision, then introduce a simple counterfactual fairness-based technique that can mitigate these biases. Theoretically, we show that it is possible for our approach to simultaneously improve both accuracy and fairness metrics -- in contrast to standard fairness approaches that suffer from tradeoffs. Empirically, we show that our technique improves accuracy on weak supervision baselines by as much as 32% while reducing demographic parity gap by 82.5%.