 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Out-of-distribution: A Perspective of Data Dynamics
Paper and Code
Nov 29, 2021
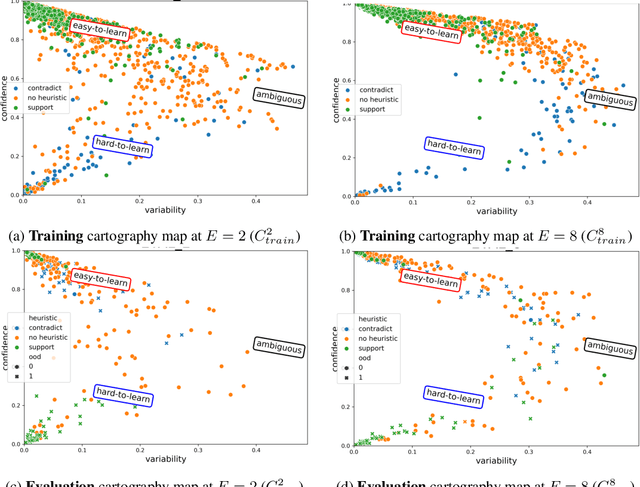
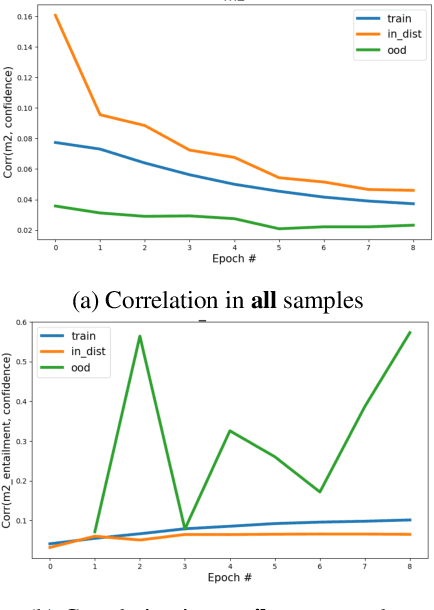
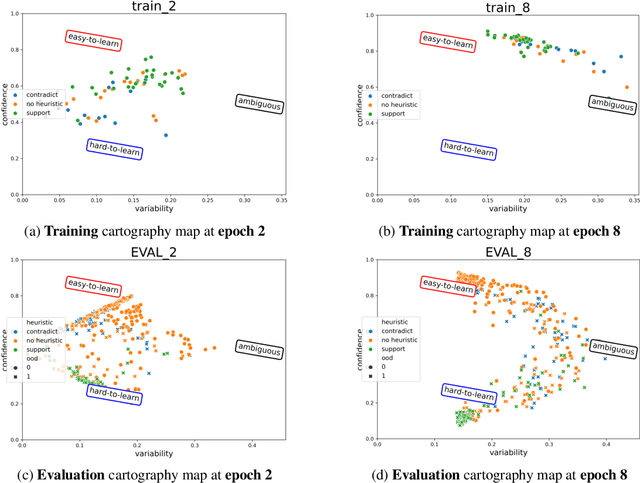
Despite machine learning models' success in Natural Language Processing (NLP) tasks, predictions from these models frequently fail on out-of-distribution (OOD) samples. Prior works have focused on developing state-of-the-art methods for detecting OOD. The fundamental question of how OOD samples differ from in-distribution samples remains unanswered. This paper explores how data dynamics in training models can be used to understand the fundamental differences between OOD and in-distribution samples in extensive detail. We found that syntactic characteristics of the data samples that the model consistently predicts incorrectly in both OOD and in-distribution cases directly contradict each other. In addition, we observed preliminary evidence supporting the hypothesis that models are more likely to latch on trivial syntactic heuristics (e.g., overlap of words between two sentences) when making predictions on OOD samples. We hope our preliminary study accelerates the data-centric analysis on various machine learning phenomena.